
Explore our expert-made templates & start with the right one for you.
Table of contents
What is Amazon Athena?
Amazon Athena is a serverless, interactive query service that reads data directly from Amazon S3 object storage. It is based on the open-source Apache Presto, but offered exclusively as a managed service by Amazon Web Services. Athena allows you to analyze very high volumes of data using ANSI-SQL, without the need to manage infrastructure.
Unlike a traditional database, Athena doesn’t store data at rest – storage is done entirely on S3, while the compute resources needed to return results for a query are provisioned automatically by AWS. Pricing follows a similar logic and based on terabytes of data scanned ($5 per terabyte).
Upsolver is the only AWS-recommended partner of Amazon Athena, providing seamless data prep and ETL to make complex data instantly available for analysis on Athena. Learn more about our Athena ETL solution or Start for free!
What Are the Benefits of Amazon Athena?
- Less reliance on IT: Running Athena does not require users to monitor infrastructure, spin up additional clusters or manually provision resources, making it simpler to get started.
- Open architecture: Athena supports commonly-used open source formats such as JSON, CSV and Apache Parquet, which reduces vendor lock-in and enables users to employ additional querying and analytics tools as needed.
- Decoupled storage and compute: Since Athena utilizes Amazon S3 for data storage, costs are exponentially lower compared to storing the same amounts of data in a coupled database. This allows organizations to store exponentially higher volumes of data without incurring significant additional costs.
- SQL-based: SQL is the language of choice for most data analysts and DBAs, and is simpler to work with compared to Python or Scala. Athena queries are written in regular ANSI-SQL, which makes it accessible by almost every data professional or developer.
Read more about the benefits of Athena compared to traditional databases.
What Are the Different Use Cases for Amazon Athena?
Athena can be relevant whenever you want to query data stored on Amazon S3. Common scenarios include:
- Streaming analytics: Querying and visualizing streaming sources such as web click-streams in real time, or near-real time.
- Ad-hoc analytics on big data: Quickly answering a specific question that requires you to scan terabytes of data, without setting up infrastructure.
- Redshift cost reduction: While Redshift ensures very high performance, it is a coupled database which can become costly and complex to operate at higher scales; in these cases, Athena and S3 storage can be used to reduce some of the operational cost of Redshift.
Learn more about Athena use cases:
- [Blog] How to Use Amazon Athena to Query S3: We cover the basics of querying Amazon S3 using Athena, including some handy links to previous resources we’ve published on this topic, and end with a quick example and tutorial on querying Apache Parquet files on S3 as Athena tables. Read more
- [Blog] Data Architecture for Amazon Athena: 6 Use Cases to Learn From: In this article we’ll look at a few examples of how you can incorporate Athena in different data architectures and to support various use cases – streaming analytics, ad-hoc querying and Redshift cost reduction. Learn more
- [Blog] Handling GDPR / CCPA Requests in Amazon Athena: In this article, we’ll discuss the challenge of ensuring GDPR compliance when using Amazon Athena and explain how you can use data lake ETL tools such as Upsolver in order to remove PII from Athena quickly and efficiently. Read more
Benchmarks and Comparisons
- [Blog] AWS Athena Pricing vs. AWS Redshift Pricing Comparison: In this post, we would take a closer look at the pricing scheme of Amazon Athena and Redshift. Read more
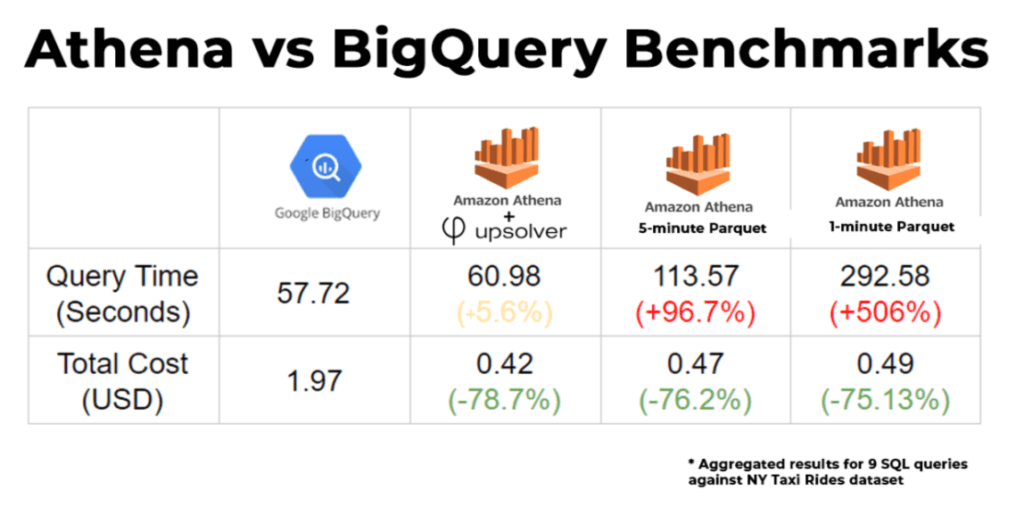
- [Blog] Benchmarking Athena and BigQuery – Performance and Price: We ran a series of SQL queries against the same dataset in Amazon Athena and Google BigQuery, and measured the time it took to return query results as well as the costs. We also tested the impact of data preparation. Read more
- [Blog] Deciding between Athena and Redshift: We look at typical use cases for these two popular AWS tools and attempt to give a few high-level guidelines to decide which of the two you should use. Read more
- [Blog] AWS Serverless Showdown: Redshift Spectrum vs Athena: t’s easy to get confused when comparing Amazon Athena and Amazon Redshift Spectrum. Ostensibly, both of these services are used to query data from Amazon S3 using SQL, without managing infrastructure. We clear up the confusion. Read more
Analyzing Streaming Data in Athena
Streaming data is challenging in unique ways. See how to build efficient data pipelines that enable you to query event streams in Athena:
- [Blog] ETL your Kinesis Data to Athena with UpSQL: In this step-by-step guide, we demonstrate how you can use UpSQL to ingest data from Kinesis to S3 and create a structured table in Athena using only regular SQL. Read more
- [Blog] Data Architecture for AWS Athena: 6 Examples to Learn From Amazon Athena is a powerful tool for querying data. In this article, we dive into examples of how to incorporate Athena in different data architectures. Read more
- [Blog] How (and Why) to Analyze CloudWatch Logs In AWS Athena: This blog post presents a reference architecture and key principles for storing your logs in analytics-ready format on Amazon S3, and then using Amazon Athena to query and analyze the data. Read more
- [Video] Kafka to Athena We look at typical use cases for these two popular AWS tools and attempt to give a few high-level guidelines to decide which of the two you should use. Read more Watch now
ETL and Data Preparation for Athena
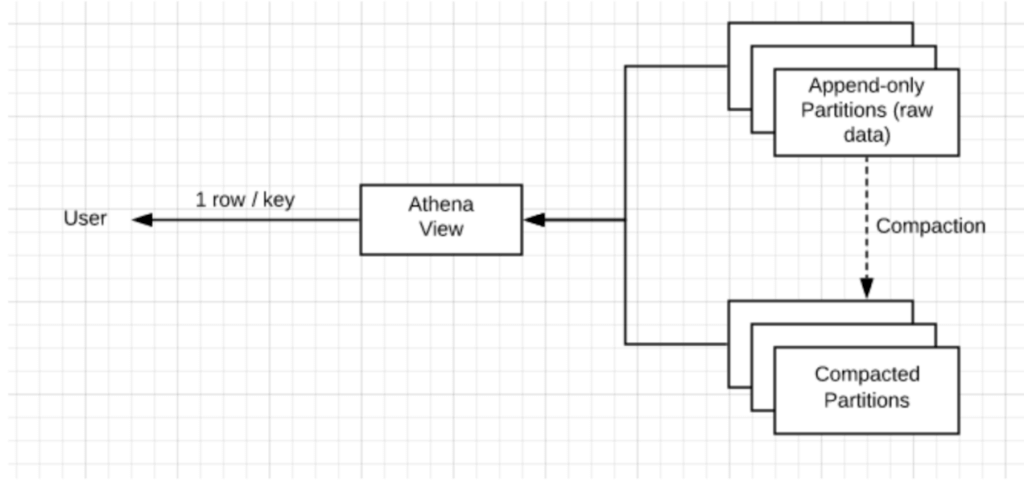
Athena reads data directly from Amazon S3, and the way data is stored on S3 can have a dramatic impact on how much value you get from Athena. Discover best practices around partitioning, compaction and file formats to learn how to optimize your data for analytic consumption.
- [Webinar] ETL for Amazon Athena: ETL for Amazon Athena: Watch this on-demand webinar to learn the essential guidelines and unique characteristics of ETL for Athena – including partitioning, compaction, pre-joining data and more. Watch now
- [Blog] 6 Data Preparation Tips for Querying Big Data in Athena: A written and abridged version of the above webinar, if you’re more into text than video. Read more
- [Blog] Solving the Problem of Small Files on S3: Learn how merging small JSON files on S3 into larger files can improve query performance, including benchmarks, and discover the best practices for doing so. Read more
- [Blog] Custom Partitioning for Embedded Analytics with Athena: In this blog post, we will present a solution for building performant embedded analytics on streaming data using Amazon Athena. Read more
- [Blog] Using Upsolver to Flatten JSON Arrays into Athena Tables: We explain the concept of flattening arrays, and Upsolver’s automated method of addressing it. Read more
Improving Athena Performance
- [Blog] Partitioning Data on S3 to Improve Performance in Athena: When storing data on an AWS data lake, partitioning is key to ensure optimal query performance. Check out our guide to partitioning strategies to learn how to do it right. Read more
- [eBook] Athena Challenges and Best Practices: earn how to avoid common pitfalls, reduce costs and ensure high performance when working with Amazon Athena. Read more Read more
- [Blog] Ultimate Guide to Improving Athena Performance: Understand the basics of what drives Athena performance, and typical things to look out for to ensure queries return quickly. Read more
- [Webinar] Improving Athena + Looker Performance by 380% with Upsolver: Ori Rafael, CEO of Upsolver, and Shohei Narron, Technology Alliances Manager of Looker, discuss key data preparation best practices that can have a major impact on query performance in Amazon Athena. Watch the webinar
See how you can use Athena to analyze product data while maintaining high performance and low costs:
Case Studies and Reference Architectures
See real-life examples and reference architectures to see how companies are using Amazon Athena to analyze large volumes of data.
- How Sisense uses Athena for operational BI and ad-hoc analytics
- How Bigabid uses Athena to explore advertising data and improve machine learning models
- How SimilarWeb uses Athena to analyze 100s of terabytes of data
- How Browsi ETL 4bn events to power BI dashboards built on Athena
- How AppsFlyer reduced data warehouse costs using S3 and Athena
- How Clearly uses Athena to curate analytic datasets
![]()