
Explore our expert-made templates & start with the right one for you.
Handling GDPR / CCPA Requests in Amazon Athena
-
 Shawn Gordon
Shawn Gordon
- Use Cases
- June 3, 2020
The following article is an excerpt from our new guide – Compliant and Secure Cloud Data Lakes: 3 Practical Solutions (available now for free).
In the last few years, the way companies handle consumer data has come under increased scrutiny. Legislators on both sides of the Atlantic have introduced strict regulations in this area: The General Data Protection Regulation (GDPR) in Europe, and the California Consumer Privacy Act (CCPA).
Both of these legislations introduced various restrictions on the way companies collect, store and make use of personally identifiable information (PII), as well as harsh sanctions for breaches of duty. Hence, the ability to respond to data protection challenges is critical for organizations that want to continue processing PII without facing significant legal risks.
In this article, we’ll discuss the challenge of ensuring GDPR compliance when using Amazon Athena and explain how you can use data lake ETL tools such as Upsolver in order to remove PII from Athena quickly and efficiently. Note that we are focusing on the technical aspects of fulfilling GDPR / CCPA requests, rather than the legal ones; we will do our best to explain the latter, but this article should by no means be taken as legal advice.
What are GDPR / CCPA Erasure Requests?
Both the GDPR and the CCPA cover many different areas of how companies deal with user data: from affirmative consent to data being stored, through opting out of data being sold to third parties, and specific stipulations on how data is stored. There are also differences in when the law actually applies – the GDPR is the broader of the two, applying to any organization that operates within the European Union or that processes information of EU citizens.
A detailed breakdown of all of these requirements and a comparison of how they differ between the two legal acts is beyond the scope of this article, but you can refer to this handy comparison table available as a PDF via bakerlaw.com.
For our purposes, we’d like to focus on the right to erasure / deletion: Both the GDPR and the CCPA grant consumers the right to deletion of the personal information a business has collected about them. While there are certain exceptions, in most cases the business must delete this data, and instruct its service providers to do the same. Personal data could include anything that can uniquely identify a user – names, email addresses, and even IP addresses.
The Challenge of Identifying and Removing PII in Athena / S3
Companies that receive an erasure request need to comply within 30 days (GDPR) or 45 days (CCPA) by removing said data from its databases. This is quite simple to do in a traditional database such as Redshift or Oracle, but more difficult in a data lake architecture where data is stored on Amazon S3 and queried via Amazon Athena.
As we’ve covered in the past, Amazon Athena is serverless and thus does not store any data, instead reading data that is stored on Amazon S3. This means that if you’re using Athena to power your analytics queries, and you’ve received a GDPR / CCPA request that obligates you to remove data from an Athena table, you will need to remove that data from S3. However, this can be challenging since: Unlike databases, data lakes do not have built-in indexes, which makes it difficult to pinpoint a specific record. For example, finding a specific IP address could require us to query the entire lake, which often might contain hundreds of terabytes or petabytes of data; we would then also need to understand every action associated with this record to identify whether any third party or service provider has been given access to it.
- Data lakes are optimized for appends, wherein every new piece of data that comes in is stored sequentially and in chronological order. Modifying tables or records without an upsert API can be a challenge that requires writing dedicated code.
These factors can make GDPR compliance more difficult to achieve in Athena compared to alternative technologies. However, by being smart about the way we handle data preparation on S3 we can easily overcome these challenges and respond to removal requests without breaking a sweat.
Removing all records from the data lake
The first thing we want to do is to delete all the records pertaining to the GDPR / CCPA requests from our data lake storage on Amazon S3. We need to identify the relevant records for that user, and then delete the events containing that ID from the S3 bucket where we ingest data.
Using Upsolver, you can specify a specific user ID, and run a ‘one-off’ operation to cleanse your data lake from records containing that ID. This happens in parallel to other ETL processes, which means there’s no negative impact on performance. This instantly removes all the user data that currently exists from S3, as well as from any Athena table that reads from S3.
Removing records from upstream data during streaming ETL
Even after we’ve complied with the GDPR request with regards to the data we currently store, we want to ensure that any future reports are also GDPR compliant and don’t contain data related to a user who has asked to be removed. To do this, we will need to continuously update and delete records as part of the ETL process that writes data from Kinesis to S3 and from there to an Athena table.
We’ve written before about how Upsolver handles data lake upserts – you can visit that link for the details, but in a nutshell:
- Upsolver ingests raw data into S3 and creates an analytics-ready version of the data, which it stores as optimized Parquet in separate partitions on S3 – which is the data that will be read in Athena. A user can define a retention period for both the raw historical data and the out Athena output.
- When creating ETLs with Upsolver, the users can set an Update or Delete key for output tables.
- As Upsolver continuously merges event files into optimized Parquet, it will use this key to either rewrite records (update) or skip them completely (delete) – so that the tables in Athena are updated accordingly.
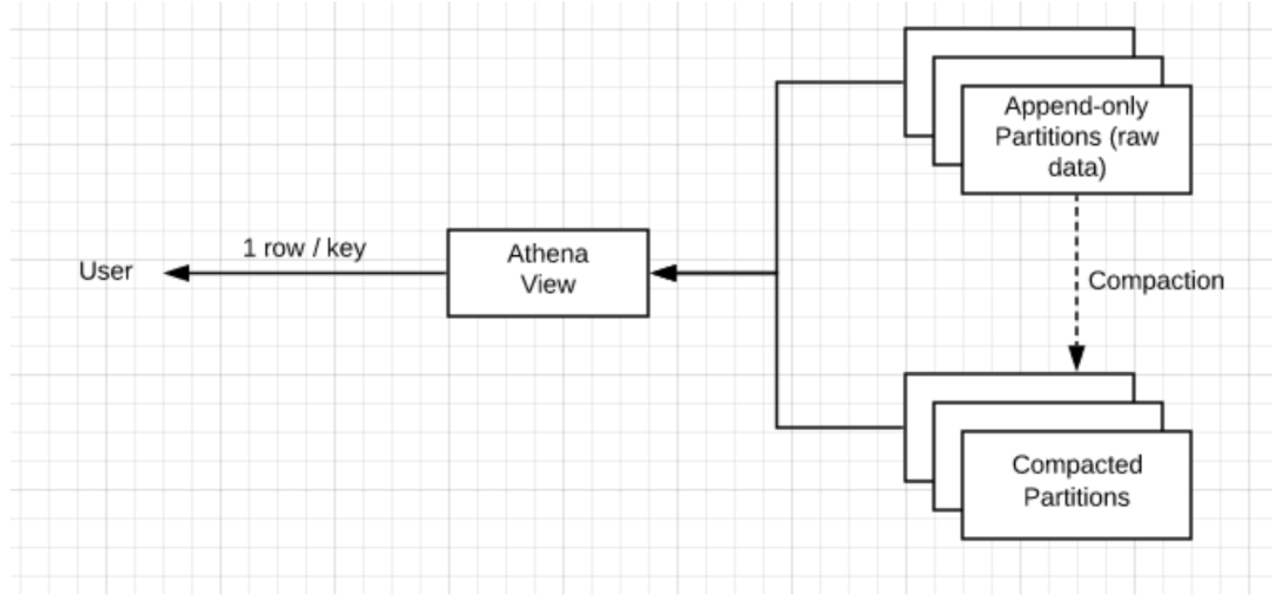
GDPR is a specific instance of this process, requiring us to delete certain data with the specific piece of PII (email or IP address, name, etc.) used as our Delete key.
We can use Upsolver SQL to create a Boolean field which indicates when an event should be deleted. For example, the following SQL transformation creates a table with a field called should_delete_user which will be used to mark an event for deletion:
SELECT user_id, user_data, should_delete_user
FROM user_events
REPLACE ON DUPLICATE user_id
Based on this query, Upsolver will set a Delete Key based on the should_delete_user field. As events stream in, Upsolver will delete relevant events marked for deletion, and store this result in the Glue Data Catalog (or other Hive Metastore). The Athena table that reads this data from Glue will only contain the GDPR-compliant version of the data, with any relevant records or events removed.
Next steps
- Another important aspect of GDPR / CCPA is the way you store user information, including encryption and tokenization. To learn more about how to achieve this, check out our guide to protecting PII and sensitive data on Amazon S3.
- Watch our recorded webinar to find out the 6 essentials of ETL for Amazon Athena.
If you want to discover how you can take your data lake to the next level and multiply the value you gain from Amazon Athena, schedule a free, no-strings-attached demo of Upsolver today.
