
Explore our expert-made templates & start with the right one for you.
Data Architecture for AWS Athena: 6 Examples to Learn From
-
 Eran Levy
Eran Levy
- Cloud Architecture
- February 5, 2020
As we’ve covered extensively on this website, Amazon Athena is a powerful and versatile tool for querying data stored on S3. However, it is always only part of a larger big data framework used to ingest, process, store and visualize data.
In this article we’ll look at a few examples of how you can incorporate Athena in different data architectures and to support various use cases – streaming analytics, ad-hoc querying and Redshift cost reduction. For each use case, we’ve included a conceptual AWS-native example, and a real-life example provided by Upsolver customers. If you’re looking for a step-by-step guide, check out our previous article on Athena + S3.
Use Case: Streaming Analytics
In this use case, Amazon Athena is used as part of a real-time streaming pipeline to query and visualize streaming sources such as web click-streams in real-time. Streaming data is semi-structured (JSON or XML formatted data) and needs to be converted into a structured (tabular) format before querying for analysis. This process requires compute intensive tasks within a data pipeline, which hinders the analysis of data in real-time.
AWS-native architecture for small volumes of click-stream data
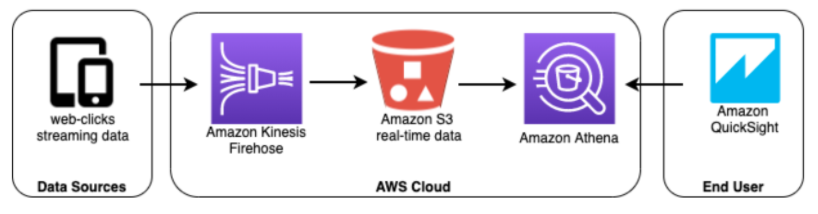
You can build a basic streaming analytics pipeline using Amazon Kinesis Firehose, which is a fully managed service for ingesting events and loading them onto S3. Firehose can further be used to convert files into columnar file formats, and to perform various aggregations. Once data is on S3 it can easily be queried in Athena using regular SQL, and then visualized using Amazon Quicksight.
The advantage of this approach is that it is very simple and you are using only native AWS services which are all closely integrated. For smaller volumes of data Athena will be able to retrieve your queries quickly and without issues.
However, for larger volumes of data this architecture will likely be insufficient since you are not optimizing the data on S3, which will cause issues when it comes to Athena performance and costs. In order to ensure queries return effectively at scale, we need to ETL the data before running our queries in Athena, as we can see in the next example.
Large-scale stream analytics at Browsi using Upsolver ETL
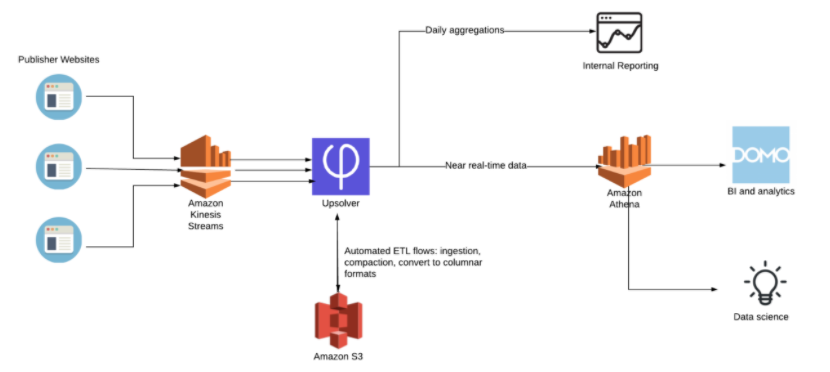
In this example taken from our Browsi case study, we are using Amazon Kinesis Streams to capture click-stream events and process them. Upsolver is used instead of FIrehose to ingest the data but also as an ETL tool to optimize the data for consumption in Athena by writing optimized Apahce Parquet, automatically partitioning the data and merging small files.
This data pipeline allows Browsi to query 4 billion daily events in Amazon Athena without the need to maintain manual ETL coding in Spark or MapReduce. Data is available in near real-time with mere minutes from the time a click is recorded in the source systems to that same event being available in Athena queries. In this case Domo is used as the dashboard visualization layer.
Use Case: Ad-hoc Analytics
The ability to analyze data in order to answer ad-hoc business or technical questions is a requirement in most data science and analytics teams, Data warehouses can enable ad-hoc data exploration with SQL; however, when dealing with disparate data sources and large volumes of data, the amount of time and compute power that would need to be spent on ETLing the data might be prohibitive. In these cases we would store raw data on Amazon S3 and create specific ETL flows per use case. Let’s look at how we would use Athena for ad-hoc analysis within this framework.
Batch processing using Amazon EMR and querying S3 directly for ad-hoc questions.
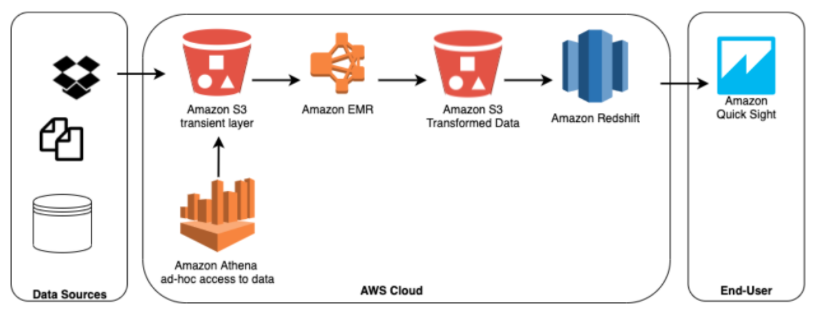
In this example, data is coming from multiple data sources to be stored into Amazon S3 as a backup and a transient data storage layer. The stored data is then processed by a Spark ETL job running on Amazon EMR. This ETL flow will allow us to store data in an aggregated format before propagating into Amazon Redshift data warehouse to be used for business analysis, reporting, visualization, or advanced analytics.
However, this transformation is done in a batch process, which would typically not run more than a few times each day (or less) in order to save resources and reduce the risk of production issues. Moreover, the way we model the data for reporting in Redshift would be based on how to most effectively answer the same questions that we ask every day or hour, but might not be suitable for the types of ad-hoc queries that arise from time to time. To avoid these limitations, we will use Athena to query the data directly on S3 and separate from the Spark ETL pipeline.
The disadvantage of this approach is again costs and performance: running Athena directly on the collection of small files stored on S3 can be almost 7x slower than querying the same dataset after merging the files; furthermore, it will result in much more data being scanned, which can make the operation very expensive to run if you’re dealing with more than a few terabytes worth of data.
Stream processing at Bigabid
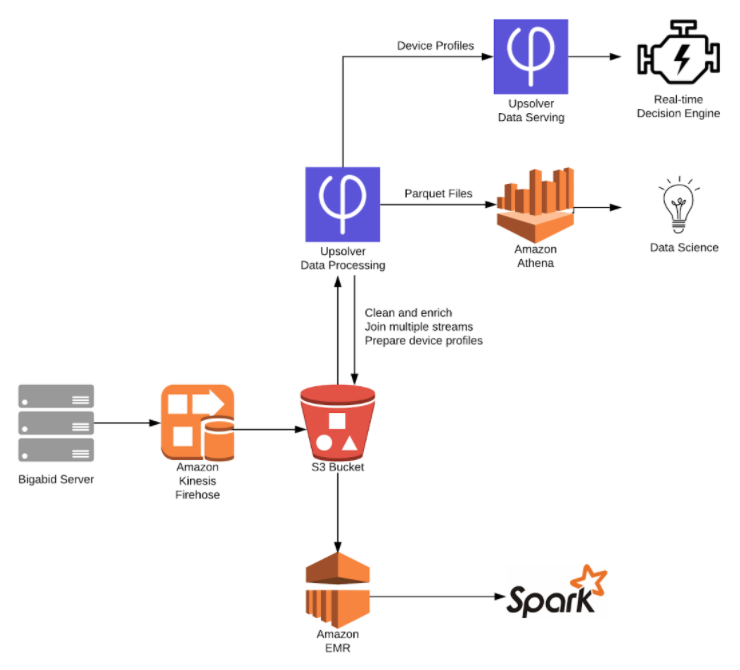
This example is taken from our case study with Bigabid, which you can read on the Amazon Web Services website. In this case data is ingested to S3 using Kinesis Firehose and processed using Upsolver, so that the data on S3 is clean, enriched and pre-aggregated by key.
This data is used in multiple flows – including a real-time decisioning model as well as for a separate advanced analytics pipeline built with Spark. For ad-hoc querying, data scientists can leverage the SQL capabilities of Amazon Athena – however, since the data runs through the Upsolver platform beforehand, these ad-hoc queries run against optimized Parquet rather than millions of event files.
Since Upsolver processes data as a stream, this architecture skips the latencies and limitations of batch processing, making data immediately available for ad-hoc querying – but we are still pre-processing the data to control costs and performance.
Redshift Cost Reduction
Amazon Redshift is an enterprise-grade data warehouse solution that leverage massive parallelism, query optimization, data compression, and columnar storage to provide high performance. However, since compute and storage resources are coupled in a data warehouse, using them to store big data can result in very high costs in hardware and human resources. In these cases we’d want to use Athena in order to reduce the costs of storing and analyzing all the data in Redshift.
Offloading OLTP queries to Athena
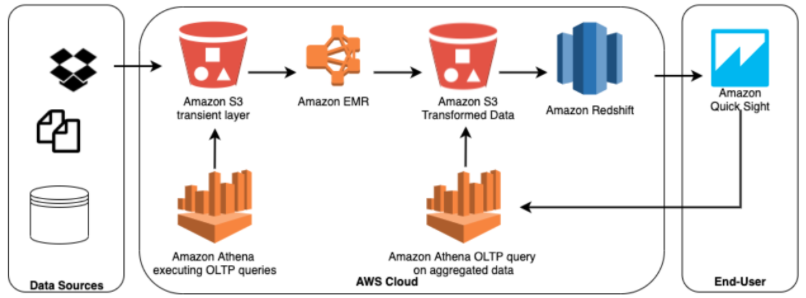
Redshift is designed as an analytical (OLAP) database, which means it is best suited to answer repetitive queries for reporting purposes. However, executing OLTP like queries on Redshift can result in slow processing, which is why in this example we are offloading them to Athena while only loading aggregated or reduced data into Redshift rather than all the transactional data.
The figure above is an extension of the previous use case, where Amazon Athena can be used on Amazon S3 transient layer for OLTP like queries as well as on top of S3 with aggregated data in order to get faster results for OLTP queries. Amazon Quicksight can be used to visualize data from both Redshift and Athena.
This approach will allow us to reduce some of our Redshift workload, but it still suffers from the same problems of reliance on batch processing – or no processing at all, which might make the same costs we avoided in Redshift resurface in Athena. Additionally, this pipeline is heavily reliant on Apache Spark. Spark has several limitations when it comes to self-service and ongoing maintenance, which might require us to spend the money we’re saving on hardware on lengthy and complex coding projects rather than new features.
Leveraging multiple query engines by use case at ironSource
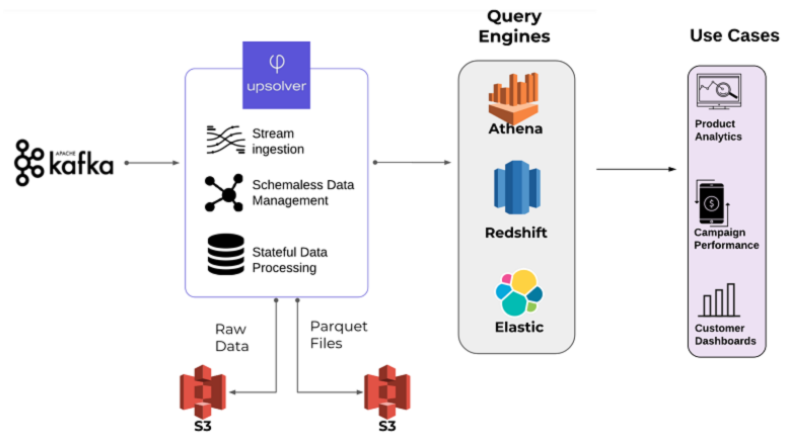
This example is taken from our case study with ironSource, which was published on the AWS big data blog. In this case Upsolver is used to ingest the data and then create ETL pipelines that support various use cases within the organization. Redshift is used for analytics and dashboard reporting (using Tableau), while other types of analysis and data exploration are performed using Amazon Athena and Elasticsearch.
In this example, Upsolver enables ironSource to only write only the relevant data to Redshift, while storing historical data on Amazon S3 (which makes it easy to backfill data and create historical lookups). Since the data volumes in this instance are ridiculously large – 500k events per second – writing all of the data to Redshift would not be viable from a cost perspective.
You can learn more about how the company uses Upsolver and Amazon S3 to control costs and support different use cases in the organization in our joint webinar with ironSource and AWS.
Want to master data engineering for Amazon Athena? Get the free resource bundle:
Learn everything you need to build performant cloud architecture on Amazon S3 with our ultimate Amazon Athena pack, including:
– Ebook: Partitioning data on S3 to improve Athena performance
– Recorded Webinar: Improving Athena + Looker Performance by 380%
– Recorded Webinar: 6 Must-know ETL tips for Amazon Athena
– Athena compared to Google BigQuery + performance benchmarks
And much more. Get the full bundle for FREE right here.
Or explore additional resources…
We’ve got a ton of additional resources on Amazon Athena that you should definitely check out. You can start with our previous post for examples of data lakes on Amazon S3, explore our solution for ETL for Amazon Athena, or watch our on-demand webinar on the same topic.
Feel ready to build your own architecture? Talk to one of our solution architects beforehand to discover how the world’s most data-intensive organizations build performant Athena architectures using Upsolver on AWS.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Cloud Architecture
