Explore our expert-made templates & start with the right one for you.
Sisense: Drives New Analytical Insights from S3 by Leveraging a Data Lake Platform
CUSTOMER STORY

INDUSTRY:
Business intelligence and analytics software
SOLUTION:
Building and managing a data lake on S3; Running ad-hoc analytic queries on streaming data to better understand product data
DATA:
Product logs - over 200BN records, 150 gigabytes of new data created daily, 20 terabytes overall
Ability
to run new analytical queries on streaming data in Sisense
Additional
use cases around machine learning being rolled out
Sisense is one of the leading software providers in the highly competitive business intelligence and analytics space, and has been named a Visionary by Gartner for the past two years. Headquartered in New York and serving a global market, the company provides an end-to-end BI platform that enables users to reveal business insights from complex data. Sisense counts Nasdaq, Airbus, Philips and the Salvation Army among its customers.
Seeking to expand the scope of its internal analytics, Sisense set out to build a data lake in the AWS cloud in order to more effectively store and analyze product usage data – and following a recommendation from the AWS team, began looking into Upsolver’s Data Lake Platform.
Ability
to run new analytical queries on streaming data in Sisense
Additional
use cases around machine learning being rolled out
The Goal
As an analytics company, data-driven decision making is part of Sisense’s DNA – and this includes product usage data, which the company uses to improve processes across its Sales, Customer Success and Product departments.
However, the rapid growth in its customer base created a massive influx of data that had accumulated to over 200bn records, with over 150gb of new event data created daily and 20 terabytes overall.
To effectively manage this sprawling data stream, Sisense set out to build a data lake on AWS S3, from which they could deliver structured datasets for further analysis using its own software – and to do so in a way that was agile, quick and cost-effective.
The Solution
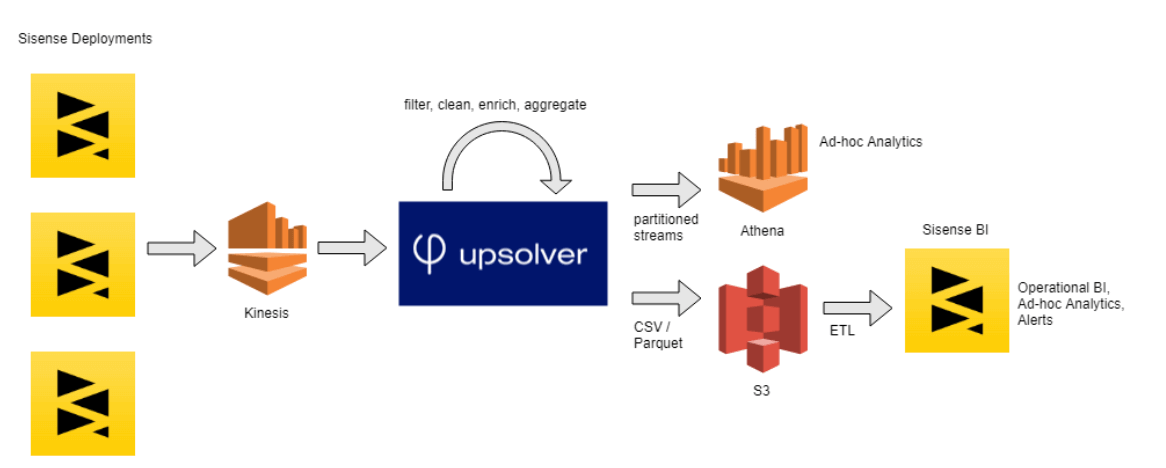
Guy began experimenting with Upsolver in his ‘spare time’ amidst a host of additional responsibilities, but was delighted to discover that this was all he needed to do to start seeing results. After previously trying to run Athena directly on the 70bn stored records, which proved to be very cumbersome, Guy now had a simple way to enrich the data and deliver structured datasets to Sisense’s analytics platform.
Upsolver’s ability to rapidly deliver new tables generated from the streaming data, along with the powerful analytics and visualization capabilities of Sisense’s software, made it incredibly simple for the Sisense team to analyze internal data streams and gain insights from user behavior – including the ability to easily slice and dice the data and pull specific datasets needed to answer ad-hoc business questions.
The Results
Upsolver is already in production, and provides powerful new querying capabilities for business analysts within Sisense. “The BI analysts are absolutely ecstatic to have this type of data, at this granularity, so easily accessible”, says Guy.
Working in tandem with Athena and Sisense’s own BI software, Upsolver will further simplify the way additional teams within the company make data-driven decisions: from product managers having a better understanding of how the software is being used, through sales representatives gaining real-time insights into prospect behavior, to data scientists working on machine learning algorithms.