

Explore our expert-made templates & start with the right one for you.
AWS Serverless Showdown: Redshift Spectrum or Athena – Which Should You Choose?
-
 Shawn Gordon
Shawn Gordon
- Cloud Architecture
- November 1, 2022
The following article is part of our free Amazon Athena resource bundle. Read on for the excerpt, or get the full education pack for FREE right here.
It’s easy to get confused when comparing Amazon Athena and Amazon Redshift Spectrum. Ostensibly, both of these services are used to query data from Amazon S3 using SQL, without managing infrastructure.
However, a closer look will reveal key differences between these two services – which could manifest in cost, performance and functionality. Let’s proceed to take a closer look at Athena and Spectrum, with the aim of understanding when you should choose each tool for a specific analytical workload.
The Contenders
 Amazon Redshift Spectrum: The Basics
Amazon Redshift Spectrum: The Basics
Amazon Redshift Spectrum was launched in April 2017 as a feature within Amazon Redshift. Spectrum enables you to query data stored on Amazon S3 using SQL, and to run the same queries on tabular data stored in your Redshift cluster and data stored in S3 – all using the Redshift SQL query editor.
 Amazon Athena: The Basics
Amazon Athena: The Basics
Amazon Athena was introduced in 2016 as a standalone, serverless SQL query engine used to query data stored on Amazon S3. It is fully managed so there is no infrastructure to maintain – simply define and run your query. We’ve written quite a lot about Athena in the last few years, so you can check out our Amazon Athena resources here.
Both Spectrum and Athena are similar in that they both enable you to query data stored on S3. However, there are differences in how they work under the hood. so choosing one over the other will produce different results in many cases. Let’s look at some of these differences.
Redshift Spectrum vs. Athena Cost
Spectrum and Athena are both charged based on the amount of data scanned when running a query – although there is 10MB minimum per query and AWS rounds up to the next megabyte. The price is the same across both services – $5 per compressed terabyte scanned.
Additional costs to take into account would be storage on S3, which is relatively much less costly than a database. Since both services operate in a decoupled manner that separates between storage and compute, you can leverage inexpensive S3 to work with petabyte or exabyte-scale data without racking up massive cloud bills.
While in Athena these costs would be all-inclusive, for Spectrum you would also need to consider Redshift compute costs – as we cover in the next section, you would need to allocate these based on your Redshift cluster.
Athena vs. Redshift Spectrum: Performance
While both Spectrum and Athena are serverless, they differ in that Athena relies on pooled resources provided by AWS to return query results, whereas Spectrum resources are allocated according to your Redshift cluster size.
This means that using Redshift Spectrum gives you more control over performance. If you need a specific query to return extra-quickly, you can allocate additional compute resources (needless to say, this can get expensive over time). This is not the case with Athena, where your query will only receive the resources allocated automatically by AWS, which might differ during peak usage times.
Both Spectrum and Athena use virtual tables when querying data stored on Amazon S3. This is done using the Glue Data Catalog for schema management. Athena is designed to work directly with table metadata stored in the Glue Data Catalog. When using Redshift Spectrum, external tables need to be configured per each Glue Data Catalog schema.
Whether you’re using Athena or Spectrum, performance will be heavily dependent on optimizing the S3 storage layer. We’ve written about this topic extensively, and you can check out our guide to Athena performance here; as well as our benchmarks for Athena and benchmarks for Redshift Spectrum.
Redshift Spectrum vs. Athena Functionality
The basic functionality offered by Athena and Redshift Spectrum is similar: querying S3 using standard SQL, and storing the results of that query. The main difference is the resource provisioning, which we’ve covered in the previous section, and loading data into Redshift: Athena stores query results on S3, and they can be loaded into Redshift from there; whereas Spectrum can be used to join tables stored on Redshift directly.
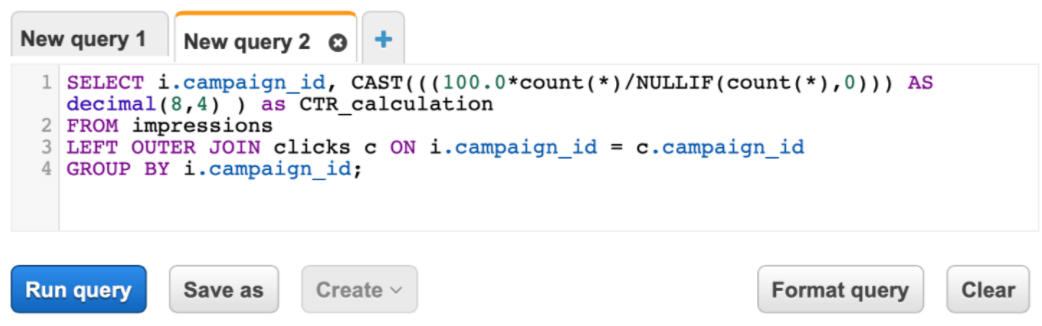
Athena SQL interface:
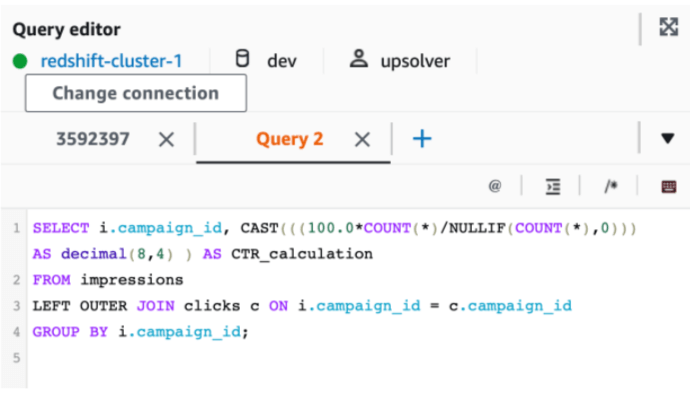
Redshift Spectrum SQL interface:
Integrations
Joining tables
Both Athena and Redshift Spectrum are serverless and read data stored on Amazon S3. Unlike traditional databases, there aren’t indexes that can be used for joins. If you’re joining two high-cardinality tables, you should consider performing joins in the ETL layer rather than in the query, in order to reduce latency.
Connectors to external services
Athena offers built-in connectors for loading data from various external sources other than S3., which enables you to query these sources in Athena without having to copy that data to S3 beforehand. You can find the full list of connectors here.
Redshift Federated Query allows you to run a Redshift query across additional databases and data lakes, which allows you to run the same query on historical data stored in Redshift or S3, and live data in Amazon RDS or Aurora.
Federated Query can also be used to ingest data into Redshift. As the service queries operational databases, it allows you to perform transformations and then load data directly into Redshift tables.
Choosing between Redshift Spectrum and Athena
As we’ve seen, Amazon Athena and Redshift Spectrum are similar-yet-distinct services. While both are serverless engines used to query data stored on Amazon S3, Athena is a standalone interactive service, whereas Spectrum is part of the Redshift stack. How do you decide where a particular workload belongs?
For queries that are closely tied to a Redshift data warehouse, you should lean towards Redshift Spectrum. Spectrum makes it easier to join data on S3 with data in Redshift, and to load those results into a Redshift table.
If all your data is on S3, lean towards Athena. If you’re not looking to analyze Redshift data, you probably don’t want to add the effort and cost of spinning up a Redshift cluster just to use Spectrum. Athena should be your go-to for reading from S3.
If you are willing to pay more for better performance, lean towards Redshift Spectrum. As we’ve covered in the previous sections, Spectrum doesn’t rely on pooled resources, so it can provide more consistent performance. However, this might increase your Redshift compute usage and require you to pay more for a larger cluster.
| Feature | Redshift Spectrum | Athena |
|---|---|---|
| Launch Year | 2017 | 2016 |
| Service | Part of Redshift | Standalone |
| Main use case | Joining S3 data with Redshift | Querying data stored on Amazon S3 |
| SQL Interface | Redshift SQL query editor | Athena SQL interface |
| Resources | Dedicated from Redshift cluster | Pooled |
| Query Cost | $5 per compressed terabyte scanned | $5 per compressed terabyte scanned |
Athena vs. Redshift Spectrum: Frequently Asked Questions
What is the difference between Athena and Redshift?
Although both services are used to query data stored on Amazon S3 using SQL, they work differently under the hood. Athena relies on pooled resources provided by AWS to return query results, whereas Spectrum resources are allocated according to your Redshift cluster size. Also, Athena is a standalone interactive service, while Spectrum is part of the Redshift stack.
Is Redshift Spectrum faster than Athena?
Redshift Spectrum can potentially be faster than Athena since it allows for more control over performance through the allocation of additional compute resources, whereas Athena relies on pooled resources provided by AWS. However, the actual performance of both services will heavily depend on optimizing the S3 storage layer and the specific workload being executed.
When should I use Redshift Spectrum?
- You have a large amount of data stored in Amazon S3, and you want to query it using SQL without loading it into a Redshift cluster.
- You have complex queries that require filtering and aggregation across multiple tables.
- You need to join data from your S3 data lake with your existing Redshift cluster data.
- You want to save costs by only paying for the queries you run, rather than running and maintaining a full Redshift cluster.
Improve Performance and Reduce Costs with Data Lake ETL
Whether you’re using Athena or Spectrum, the way you build and operationalize your data lake – from ingestion to storage to schema management – will have a major impact on how fast your queries run and your total cost of ownership. Learn how to optimize your data infrastructure using a modern data platform by scheduling a call with our solution architects.
Want to master data engineering for Amazon Athena? Get the free resource bundle:
Learn everything you need to build performant cloud architecture on Amazon S3 with our ultimate Amazon Athena pack, including:
– Ebook: Partitioning data on S3 to improve Athena performance
– Recorded Webinar: Improving Athena + Looker Performance by 380%
– Recorded Webinar: 6 Must-know ETL tips for Amazon Athena
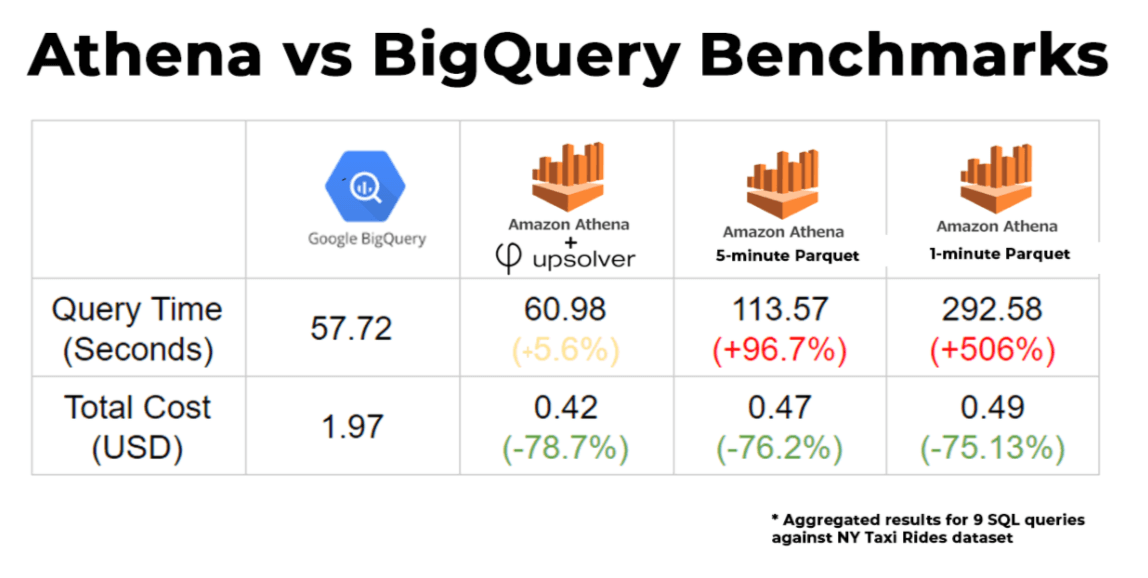
– Athena compared to Google BigQuery + performance benchmarks
And much more. Get the full bundle for FREE right here.
Try SQLake for free for 30 days. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Cloud Architecture