Explore our expert-made templates & start with the right one for you.
Bigabid: Building a Real-time Architecture to Supercharge Mobile User Acquisition with Amazon S3 and Upsolver
CUSTOMER STORY

INDUSTRY:
Mobile user acquisition, real-time bidding
USE CASE:
Creating real-time profiles of users for predictive decisioning; building datasets for machine learning
DATA:
TBs of new data generated daily from multiple streams
INTEGRATIONS:
S3, Athena, EMR, Kinesis Firehose
Real-time
processing instead of daily batches
Improved
decisioning with fresh data
Launched
and maintained by a single user
Bigabid is an innovative mobile marketing and real-time bidding company that empowers its partners to scale their mobile user acquisition efforts while lowering advertising costs through CPA and AI-based optimization.
In order to maintain a high level of performance in the competitive app advertising market, Bigabid needed to introduce real-time user profiling to its algorithmic decision engine. This case study will demonstrate how the company built a high-performance real-time architecture with minimal data engineering using Upsolver, S3 and Amazon Athena.
The Goal
The core value Bigabid delivers to its customers (mobile apps developers) is the ability acquire new users at a low cost.. Bigabid builds a profile of each user, taking hundreds of data points extracted from several streams into account; its proprietary machine learning algorithms can then predict which user is likely to download an app or make in-app purchases, and decide when and how to bid on advertising space accordingly.
These user profiles were being updated 2-3 items a day, in a batch process. However, Bigabid’s Co-founder and CTO Amit Attias wanted to replace this system with real-time stream processing in which the user profiles would be updated based on their most recent actions – as relying on fresh data could significantly improve the results delivered by Bigabid’s predictive algorithm.
The Solution
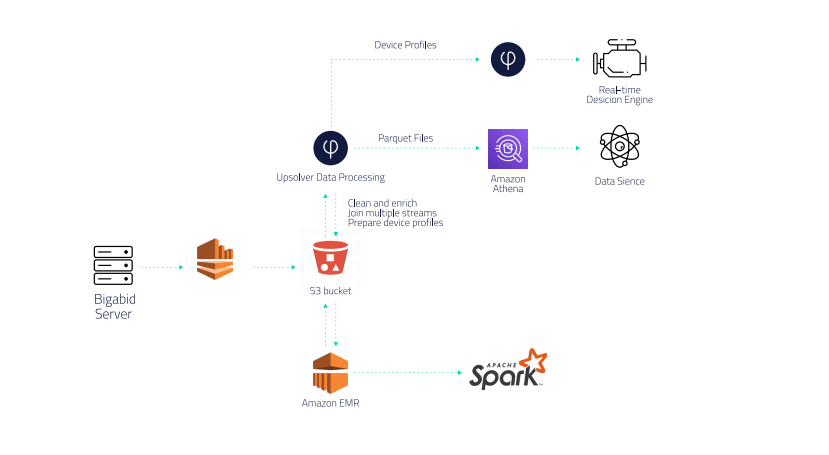
Data Preparation:
Data from multiple streams is ingested via Kinesis Firehose into Bigabid’s S3 data lake. Upsolver is then used for ETL – combining, cleaning and enriching data from multiple streams to achieve a more complete user profile.
For example, one stream might contain campaigns-per-user, while another details apps per campaign. Using Upsolver, Bigabid can easily see all the campaigns that a certain user is included in, and then pull that data in real time.
Real-time decisions:
Bigabid use an Upsolver Materialized View to build an aggregated view of each user, with data collected by the Bigabid platform as well as third party sources. These views were previously updated 2-3 times a day in a batch process, and are now produced in real time. Fresher data translates into more accurate decisions and better performance for Bigabid’s advertising partners.
Data Science / Research:
Upsolver, Amazon S3 and Amazon Athena are used for ad-hoc querying by Bigabid’s Data Science team. Insights are used to improve machine learning models that power the company’s predictive engine.
While Bigabid were already using Amazon Redshift for their business intelligence reporting, Athena has proven to be the better choice for their data science team. It enables them to query massive amounts of data at a granular level (user level) to better understand user behaviour. Storing TBs per day in Redshift would be expensive and require resources to manage a large Redshift cluster. Athena enables to query data on S3, fast, without maintenance and at a low cost.
Upsolver is used to prepare data for Athena. Instead of coding ETLs, Upsolver visual interface enabled to easily flatten the data into tables, perform data validations, create enrichments (geo attributes from IP, device attributes from user agent) and automate the process of creating and editing Athena tables. Upsolver also optimizes Athena’s storage layer (Parquet format, compaction of small files) so queries could run much faster. .
The same data is also used in a separate pipeline that sends data via Amazon EMR to Apache Spark, which is used to perform complex calculations that could not be done in SQL.
Real-time
processing instead of daily batches
Improved
decisioning with fresh data
Launched
and maintained by a single user
The Results
Working with fresher, more accurate data has played a major role in Bigabid’s ability to continuously provide exceptional performance for its customers. The real-time architecture, powered by Upsolver, is now an essential component in Bigabid’s platform.