
Explore our expert-made templates & start with the right one for you.
AWS Athena Pricing vs. AWS Redshift Pricing Comparison
-
 Upsolver Team
Upsolver Team
- Cloud Architecture
- September 8, 2020
With advancement in technologies, organizations can now undertake crucial business decisions by churning enormous datasets fairly quickly. Through Advanced Data Science & Analytics, organizations not only produce actionable insights by processing massive structured/unstructured datasets quickly, but also manage underlying warehouse and infrastructure seamlessly.
But it’s always easier said than done. This is where Amazon’s Athena and Redshift present themselves as leading platforms designed specifically to manage and analyze petabytes of data.
In this post, we would take a closer look at the pricing scheme of Amazon Athena and Redshift, here are the main topics:
- Amazon Athena use cases
- Amazon Redshift use cases
- Amazon Athena Pricing explained
- Scenarios of AWS Athena pricing
- Amazon Redshift pricing explained
- Scenarios of AWS Redshift pricing
Amazon Athena Use Cases
Amazon’s Athena is a managed serverless SQL query engine, that helps analyze datasets residing within AWS S3 (Simple Storage Service) through instant ad-hoc queries in SQL. Being a serverless service, you do not need to manage the underlying infrastructure. Instead, you just write your SQL and get a response.
Athena query workloads run on Amazon’s shared resources while maintaining a performance benchmark. Despite the fact that Athena is designed for both large and small datasets, it is particularly recommended for impromptu analysis, where scalability isn’t the prime requirement. Refer to the use cases below to understand different aspects of pricing better.
Amazon Redshift Use Cases
Amazon Redshift is a fully-managed cloud-based data warehouse platform specifically designed for high magnitude analysis with options to scale. Through Amazon’s Massively Parallel Processing (MPP) architecture and Advanced Query Accelerator (AQUA), huge workloads and complex queries are processed in parallel to achieve lightning-fast processing and analysis.
Unlike Athena, each Redshift instance owns dedicated computing resources and is priced on its compute hours. For ongoing high-volume queries that require consistent compute workloads, Redshift turns out to be a more reasonable choice.
Amazon Athena Pricing Explained
Athena charges are calculated based on the volume of data scanned during query execution. Athena costs $5 per TB of compressed data scanned. While you incur no additional costs for DDL statements or failed queries, standard charges of other AWS resources like S3 bucket, Lambda, Glue Data Catalog, etc., apply if provisioned.
As an added advantage, Amazon allows using columnar data formats, effective partitioning and removing historical results, to help bring down Athena costs further.
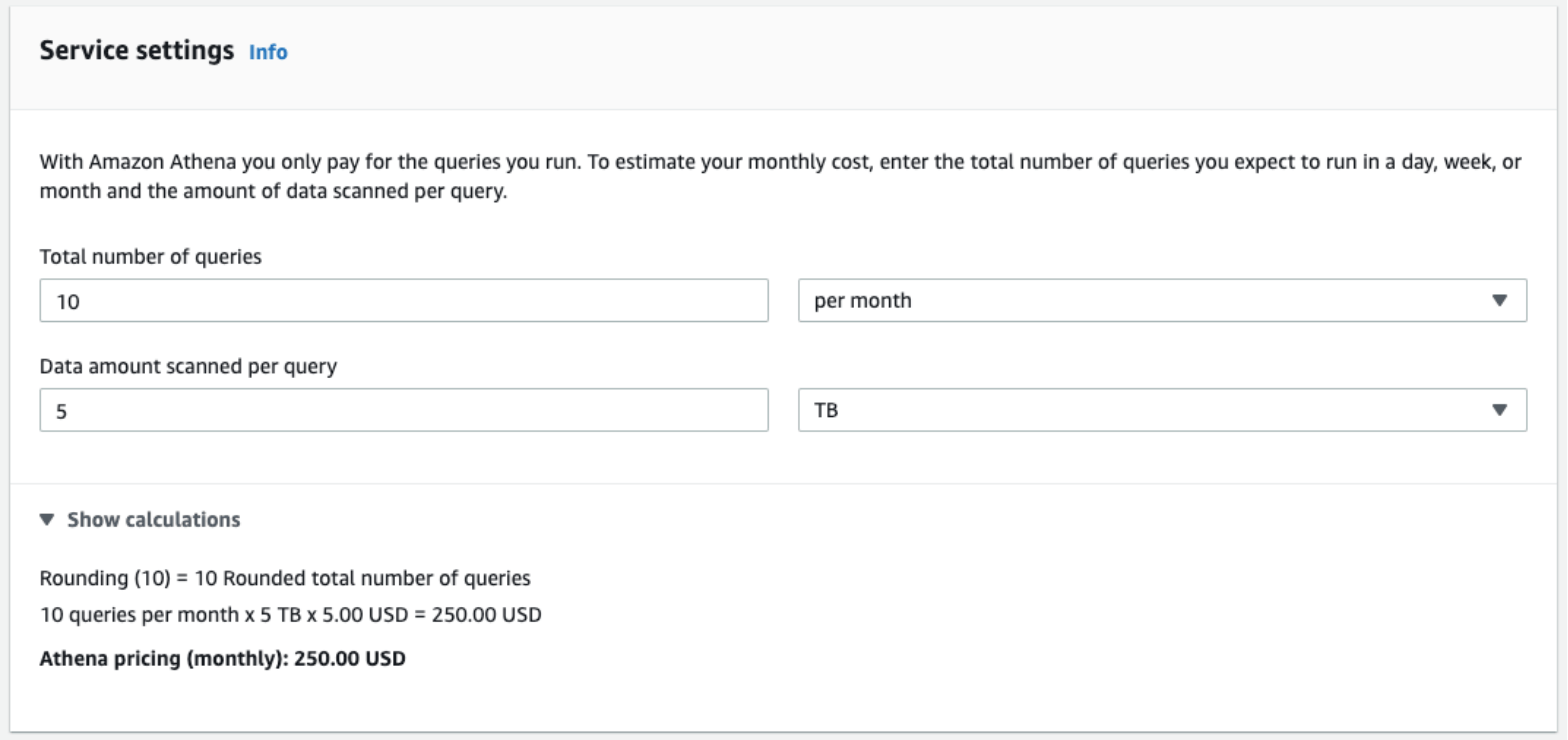
With a minimum 10MB markup per query and rounding off the scanned volume to the nearest megabyte, Amazon makes it easier to estimate Athena costs.
More details on AWS Athena pricing and query configuration can be found here.
Scenarios of AWS Athena Pricing
Here are a few instances to understand AWS Athena pricing better:
Scenario A:
Consider a requirement to execute 10 queries on 5TB of uncompressed data stored within an S3 bucket. AWS Athena pricing on successful execution of 10 queries will be $250 ($5x5TBx10).
Scenario B:
Now let us assume we have compressed the same data (5TB) to the scale of 3:1. Additionally, by provisioning columnar format on top of the compressed data, each formatted column size turns out to be 0.55TB. As Athena essentially only reads columns relevant to the query, the scan volume, in this case, is 0.55TB.
As a result, through compression and effective formatting, Athena’s cost of running a query on the same data is now $27.7 ($5×0.55TBx10).
Note: The compression ratio and formatted columns sizes are for illustration purpose only and may vary.
Scenario C:
Consider a scenario now, where we have a projection of querying on the same data (compressed and formatted) every day for a full calendar year. The cost of which turns out to be $5×0.55TBx10x365 = $10,138.
It must also be noted that as Athena queries in Amazon S3, standard rates towards S3 bucket storage and push/pull requests made against those S3 buckets are applicable.
Additionally, as Athena queries in Amazon S3, standard rates towards S3 bucket storage and push/pull requests made against those S3 buckets are applicable.
Details on Amazon S3 Pricing can be found here.
Apparently, from the above scenarios, Athena turns out to be pretty reasonable for modest ad-hoc queries. With Athena, you get the benefit of portability without being concerned about owning and managing the related infrastructure, though on-demand scaling remains a concern due to usage of pooled resources. This is where Redshift strikes in as the perfect solution.
Amazon Redshift Pricing Explained
Amazon Redshift pricing is mainly calculated on the amount of cluster resources consumed hourly. Unlike Athena, Redshift allocates dedicated resources for query throughput, enabling consistent and faster processing of datasets to the tune of petabytes.
Through Redshift’s different pricing plans, you can choose the right configuration types by opting for an On-demand or a Reserved pricing model. While the On-demand model lets you choose a cluster configuration on the fly, a Reserved instance allocates resources for a fixed term affecting significant cost savings. Also, through automatic provisioning of additional resources, you can scale performance in cases of concurrent queries.
Quick Note: With its introduction of Redshift Spectrum, Amazon now also allows you to choose a pricing model that calculates the cost based on scanned volume per query just like Athena.
More details on AWS Redshift pricing and cluster configuration can be found here.
Scenarios of AWS Redshift Pricing
To understand this better, let us consider the dataset to be similar to Athena’s Scenario C above. Here are a few instances to understand AWS Redshift pricing better:
Scenario A:
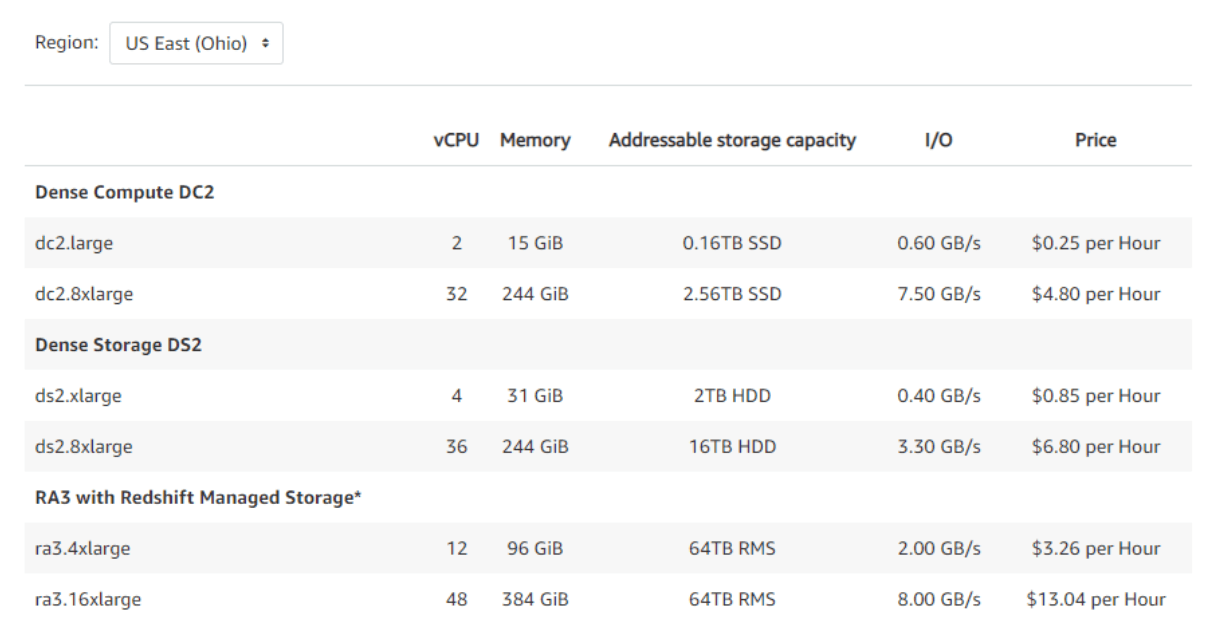
So we have a formatted and compressed dataset of 0.55TB. Based on Redshift’s pricing model, it is recommended to opt for a DC2.8XLarge Compute Node. For an On-Demand DC2.8XLarge pricing model, a successful query execution would cost $4.80 per hour. Within the billed hour, you may run single or multiple queries to make best use of the price, if the compute performance permits.
Scenario B:
Now let us assume we require a cluster with high-availability and superior performance for a full year term to execute recurring queries on the same dataset within a year.
To achieve that, let us opt for a 4-node DC2.8XLarge cluster. This amounts to $4.8x4nodesx24hrsx365days = $168,192 for a full year term.
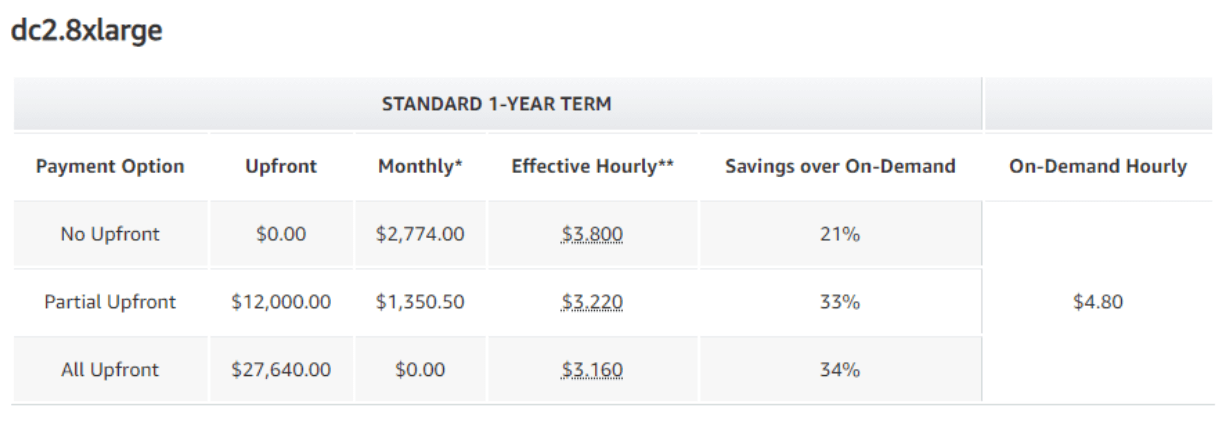
Additionally to save on costs, we may commit to use Redshift for a fixed term by choosing a Reserved pricing model. As we have a term decided, we can reserve a 1-Year Term of 4-node DC2.8XLarge cluster, which amounts to $27,640x4nodes = $110,560.
As it turns out, with Redshift, you leverage dedicated compute resources to get a high-performance engine to run unlimited queries, irrespective of the scan volume.
Conclusion
Athena is ideal for ad-hoc queries while Redshift is more suitable for on-going operational queries.
Through a dedicated set of resources and unlimited scalability, Redshift easily becomes the choice for its higher performance. Plus, the ease of adding additional clusters and instances provides Redshift higher computational capacity for concurrent query processing.
On the other hand, Athena is recommended for random manual analysis, offering a cost-effective yet powerful query platform.
The underlying recommendation for deciding between Athena and Redshift is to start with Athena and move some of the query-intensive use cases to Redshift when reaching the cost tipping point’. If Redshift is required on day 1, it might be a good idea to use Redshift with Redshift Spectrum (query external tables from S3 with the same pricing model as Athena) to combine the best of both worlds.
Whether you opt for Athena or Redshift as your preferred analytics platform, a quick note of advice is to also consider the cost and efforts required to manage other AWS resources.
Want to master data engineering for Amazon Athena S3 and Amazon Athena? Get our free resource bundle:
Learn everything you need to build performant cloud architecture on Amazon S3 with our ultimate Amazon Athena pack, including:
– Ebook: Partitioning data on S3 to improve Athena performance
– Recorded Webinar: Improving Athena + Looker Performance by 380%
– Recorded Webinar: 6 Must-know ETL tips for Amazon Athena
– Athena compared to Google BigQuery + performance benchmarks
And much more. Get the full bundle for FREE right here.
Published in:
Blog
,
Cloud Architecture