
Explore our expert-made templates & start with the right one for you.
ETL Your Kinesis Data to AWS Athena in Minutes with Upsolver SQL
-
 Eran Levy
Eran Levy
- Use Cases
- November 20, 2019
This guide describes how to create an ETL pipeline from Kinesis to Athena using only SQL and a visual interface. We’ll briefly explain the unique challenges of ETL for Amazon Athena compared to a traditional database, and demonstrate how to use Upsolver’s SQL to ingest, transform and structure the data in just a few minutes, in 3 steps:
1. Extract streaming data from Kinesis.
2. Transform the semi-structured streaming data into a table you want to create in Athena using SQL.
3. Execute the ETL job.
The Challenge: Athena ETL vs Database ETL
Analyzing high volumes of semi-structured data in Amazon Athena requires constant maintenance and optimizations of your Athena table, such as: partitioning your data, compression, splitting and dealing with small files.
Standard ETL tools load raw data to databases using insert/update/delete operations. They don’t need to concern themselves with storage. They also don’t need a powerful transformations engine since these transformations can be done once the data is already in the database (ELT approach).
Athena, on the other hand, isn’t a database but a SQL engine that queries data from S3. ETL to Athena needs to optimize S3 storage for fast queries, and must rely on a powerful transformation engine since there is no database to do the transformations instead of the ETL tool (as we covered in our recent webinar on ETL for Athena).
Upsolver’s Data Lake ETL engine is meant to address these unique challenges. Let’s see how we build our solution using UpSQL – Upsolver’s ANSI SQL language with extensions for stream processing
The Solution
Step 1: Extract Streaming Data from Kinesis
Connecting To Data Sources
Upsolver offers native connectors to several data sources for raw data ingestion, which enables us to write data from stream processors such as Kafka and Kinesis to S3 without manual configuration.
Let’s have a look at a Kinesis Stream data source in Upsolver as an example of using Upsolver’s data source preview, which allows us to immediately see schema and statistics upon ingest:
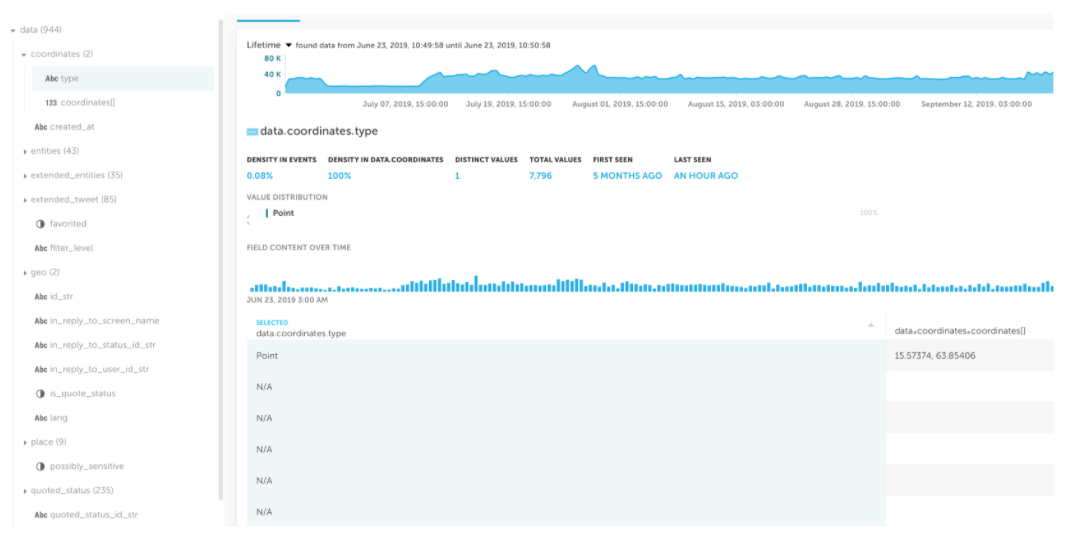
In our case we have already created a Kinesis Stream called twitter-demo and ingested the events from this stream into our data lake. Since the purpose of this article is to demonstrate the data transformation, we won’t dwell on this, but it only took a few minutes using the Upsolver UI.
In the next step we’ll use the Upsolver Output configuration to do all of the above – and more, This can be done either through the Upsolver UI (no coding required) or by using UpSQL, which is what we will be doing in our examples.
Step 2: Data transformations
Using Upsolver’s data source preview above, we can see that there are many fields in the twitter-demo data source. We can now choose what types of transformations we would like to perform, using built-in Upsolver features:
- Map fields from raw data structures (that are often nested) to columns in an Athena table – we want to map relevant fields from raw data structures such as: user activity, IoT and sensors data, application activity data and online advertisements statistics.
These sources typically contain more data than is actually needed for your analysis. Upsolver allows you to map only the required fields to columns in an Athena table.
- Join data from several data sources – we want to combine data from multiple sources to gather deeper insights and create aggregated views. Upsolver allows you to perform this with an SQL statement, similarly to a relational database.
- Perform calculations and conversions – we want to improve the quality of our data and ensure it follows standard conventions (e.g. convert time in Epoch to standard mm/dd/yyyy). Upsolver contains all the functions that exist in SQL, including special enrichment functions (e.g. IP2GEO, user agent parser) and you can add your own UDFs in Python.
Let’s look at how we would use these data transformation features in our example.
1. Map fields from raw data structures (that are often nested) to columns in an Athena table
Using UpSQL, you can choose a subset of fields from your data source to be written as output to an Athena table.
Here we’re using the SELECT clause to include only the desired fields to be written to the Athena Output:

We can also preview the query’s result before actually writing the data to avoid any mistakes along the way:
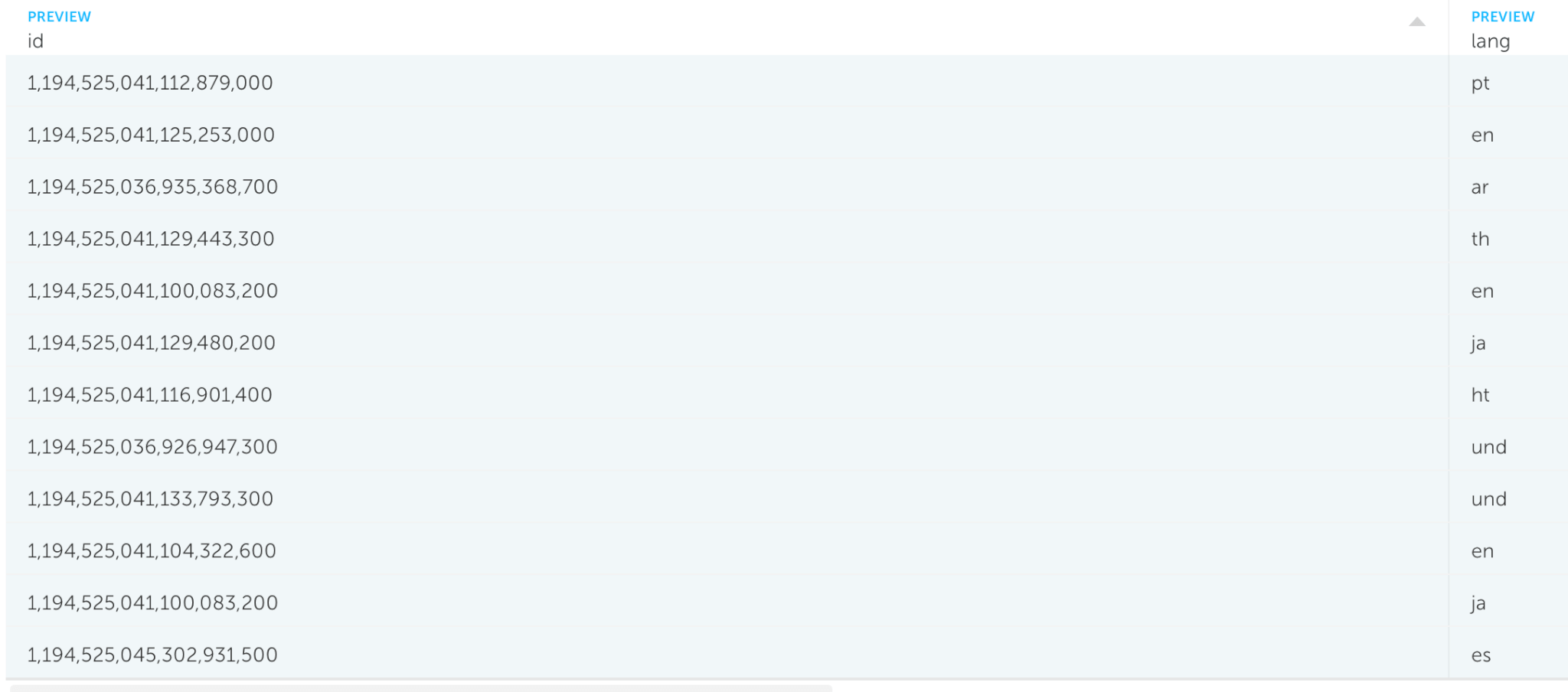
2. Join Data From Multiple Sources
Map fields from raw data

UpSQL enables you to join data from several Data Sources using the JOIN clause and perform aggregations to gather insights from your data.
The above query creates an Athena table which is being updated over time as new events belonging to each data stream arrives.
3. Perform Calculations and Conversions

The above query converts time field (which arrives as an epoch timestamp) from the “twitter-demo” stream into a human readable date format.
Step 3: Executing the ETL job
Upsolver ETLs are automatically orchestrated whether you run them continuously or on specific time frames.
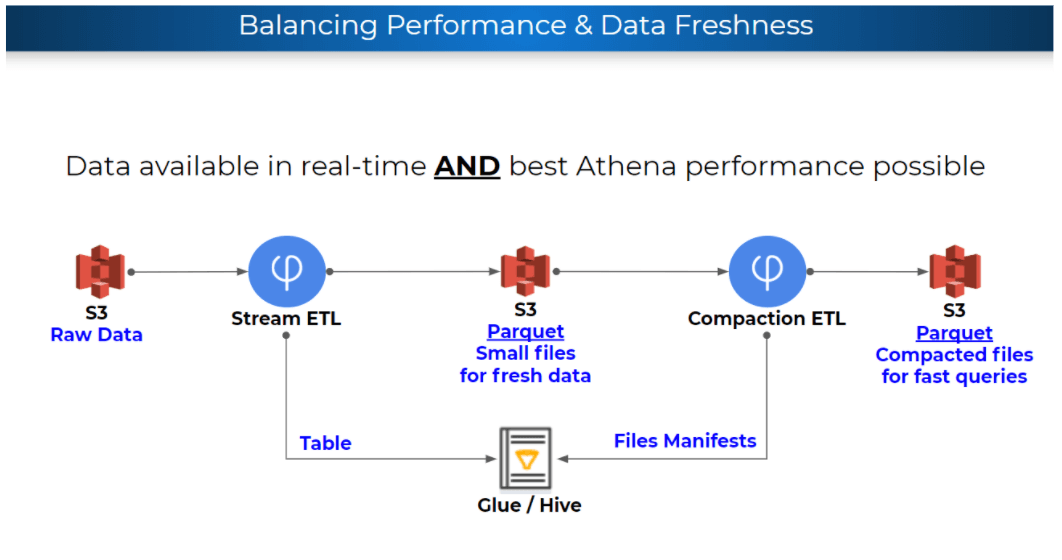
An Upsolver ETL to Athena creates Parquet files on S3 and a table in the Glue Data Catalog. There are actually 2 steps to this process. First Upsolver creates Parquet files for every minute of data so the data will be available in Athena as soon as possible. There is also an offline process (compaction) that combines small files into bigger files to improve the query performance in Athena.
Summary
In this article we explained the challenge of analyzing large volumes of stream data in Amazon Athena, which stems from the complexity of data lake ETL. Unlike traditional ETL, data lake ETL requires the user to optimize the underlying storage on S3 for Athena and it requires a robust transformation engine that can handle stateful operations.
Using Upsolver, we managed to create and deploy this ETL flow in just a few minutes using Upsolver’s visual interface and UpSQL – Upsolver’s ANSI SQL language with extensions for stream processing, which makes the data lake accessible for all SQL fluent users.
Next Steps
- Read more about using UpSQL for batch and streaming ETL
- Watch our webinar on orchestrating petabyte-scale data lake ETL at ironSource
- Get a free trial of Upsolver