
Explore our expert-made templates & start with the right one for you.
Comparing Amazon Athena and Traditional Databases
-
 Shawn Gordon
Shawn Gordon
- Cloud Architecture
- May 3, 2020
The following article is part of our free Amazon Athena resource bundle. Read on for the excerpt, or get the full education pack for FREE right here.
Amazon Athena is an interactive query service based on the open-source Apache Presto. It that enables you to directly analyze data stored in Amazon S3 using ANSI SQL. Athena is serverless so there is no infrastructure to manage and maintain, and you only pay for the queries you run.
To start using Athena, you need to define the schema of your data stored in Amazon S3 and then you are ready to start querying it using SQL. The schema is defined using Amazon Glue Data Catalog, which enables you to create a unified metadata repository across multiple services.
Athena can be used alongside or instead of traditional databases, depending on the specific business and technical scenario. However, it’s important to understand the differences between the two, and why you would choose one over the other.
How is Athena different from a database or data warehouse?
While some might mistakenly talk about the “Athena database,” Athena is not a database but rather a query engine. This means that:
- Compute and storage are separate – databases both store data in rest and provision the resources needed to perform queries and calculations. Each of these comes with direct and indirect overheads. Athena doesn’t store data – instead, storage is managed entirely on Amazon S3. Athena’s query service is fully managed, so resources are allocated automatically by AWS as needed to perform a query.
- No DML interface – with Athena there is no need to model the data. I/O is a bottleneck in virtually every database, but with Athena this is a non-issue. And since you don’t need to waste I/O bandwidth on modeling the data, you can focus all compute resources on query processing.
You can use Athena to replace some functionality of a data warehouse or a database – but the above still holds true.
Why use Athena? The benefits
- Serverless design reduces IT overhead: Amazon Athena is serverless, meaning there is no infrastructure to manage or configure on the user’s side. Using Athena is as simple as defining your query, and you only pay for the queries you run. There are no additional IT costs and no clusters to manage.
- SQL-based: You can use Athena to run SQL queries on the required table (which is configured in the Glue Data Catalog), or on data sources you can connect to using the Athena Query Federation SDK. For users who are already fluent in SQL, there is no learning curve for getting started.
- Open architecture (no vendor lock-in): Athena facilitates an open approach to data, rather than lock-in to a specific tool or technology. This is manifested in different ways.
- Ubiquitous access – Since your data is stored in an S3 bucket and schema is defined in the Glue Data Catalog, you can switch between query engines that can read from these sources without redefining the schema or creating a separate copy of the data.
- Separate storage and compute – In Athena there is a complete separation between compute and storage resources. The data is stored on your Amazon S3 account while Athena’s compute is provisioned by Amazon Web Services as a pooled resource among all Athena users.
- Open file formats – Unlike many high-performance databases, Athena does not use a proprietary file format but rather supports standard open-source formats such as Apache Parquet, ORC, CSV, and JSON.
What are the limitations of Athena?
- No built-in insert / update / delete operations: Because Athene is a query engine and doesn’t have a DML interface, upserts can be challenging.
- Optimization is limited to queries: You can optimize your queries, not your data. Your data is already stored in Amazon S3; performing transformations for the sake of using Athena may affect others using the same data for other purposes. This needs to be addressed as part of your ETL process.
- Multi-tenancy means pooled resources: All users of Athena receive a similar SLA for queries at any given time. In other words, the entire global user base is “competing” for the same resources – and while AWS provisions more of these as needed, it could mean that query performance fluctuates based on other people’s usage.
- No indexing: Indices are built into traditional databases, but do not exist in Athena. This makes joins between large tables a heavy operation that increases the load on Athena and negatively impacts performance, while running a query by key requires scanning all of the data and then searching for the required key in the list of results. This is solved using Upsolver lookup tables.
- Partitioning: Efficient queries in Athena require you to partition your data. It is important to keep the number of partitions in a ballpark that suits your performance needs. As a rule of thumb, every 500 partitions you scan add 1 second to your query.
Additional required products
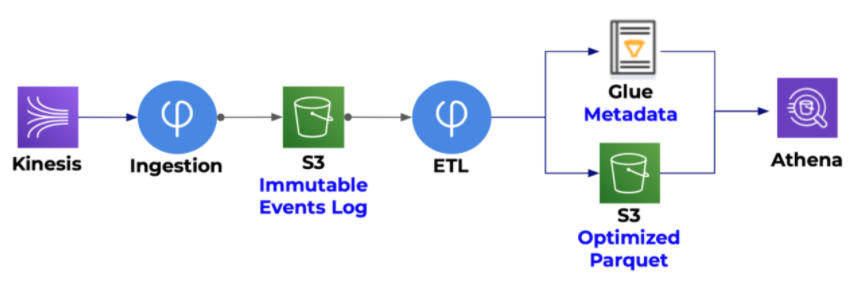
Athena is never a standalone product but rather always part of a stack that includes:
- Amazon S3: Athena queries run directly on top of Amazon S3, so this is where your data is stored.
- Glue Data Catalog: A centralized managed schema that enables you to replace or supplement Athena with additional services as needed (for example with Amazon Redshift Spectrum).
- ETL tools: While Athena can run almost any query out-of-the-box, reducing costs and improving performance requires adherence to a set of performance tuning best practices. The traditional way is to use Spark, which can process large volumes of unstructured data; however, this option requires significant coding knowledge. There are some solutions that offer managed Spark as a service, which simplifies the infrastructure aspects but do not remove the coding overhead. An alternative is to use self-orchestrating declarative data pipeline tools such as Upsolver SQLake. (You can sign up for a free unlimited 30-day trial of SQLake to try it out.)
Typical Use Cases for Amazon Athena
While Athena is a versatile analytical tool, there are certain instances where it might be your natural go-to (assuming your data is on AWS, of course). To learn more about use cases, check out these Athena architecture examples, as well as the resources linked below.
Log analysis (Athena vs ElasticSearch)
Many organizations store their system logs on Amazon S3. These can be logs generated by software applications or hardware such as servers and remote devices. Athena can then be used to query and analyze the data.
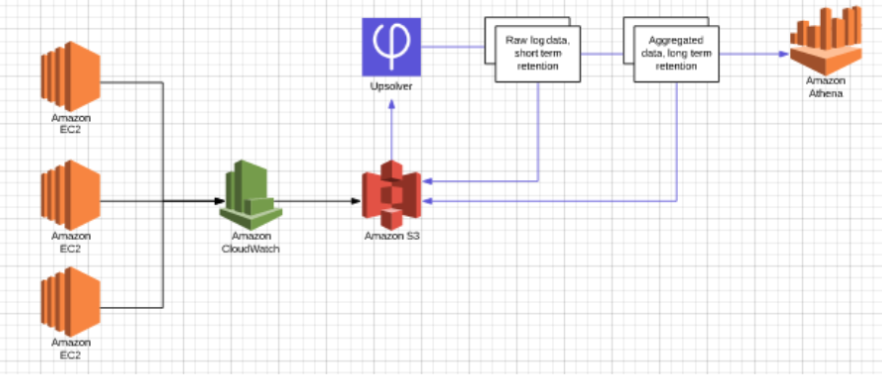
Advantages:
- Costs – can define longer retention periods due to low storage cost vs. traditional logging databases such as Elasticsearch.
- SQL – most log storages don’t offer an SQL engine for analytics, which requires analysts to use unfamiliar tools.
Examples of log analysis use case using Athena:
Business Intelligence and Online Analytical Processing (OLAP)
Athena is often used as the querying layer, with query results being used to build BI dashboards or support analytical processing.
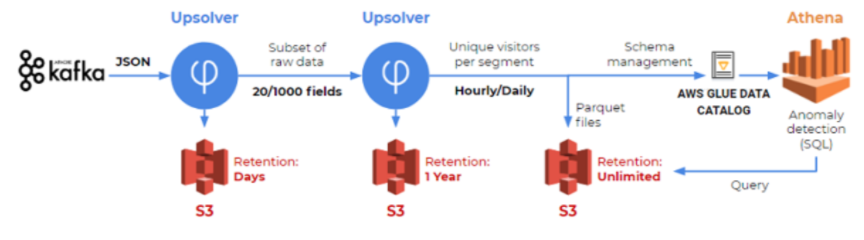
Advantages:
- Cost – avoid the ongoing compute and storage costs of a traditional database.
- Access to all data – no need to prune your data to reduce infrastructure overhead (see above).
Examples of BI and analytics using Athena:
- BI on 4bn events using Athena and Domo
- Building Athena Dashboards in Looker
- Analyzing Hundreds of Terabytes
Research
Athena enables analysts and data scientists to quickly run ad-hoc queries against large volumes of data to quickly answer a specific business question.
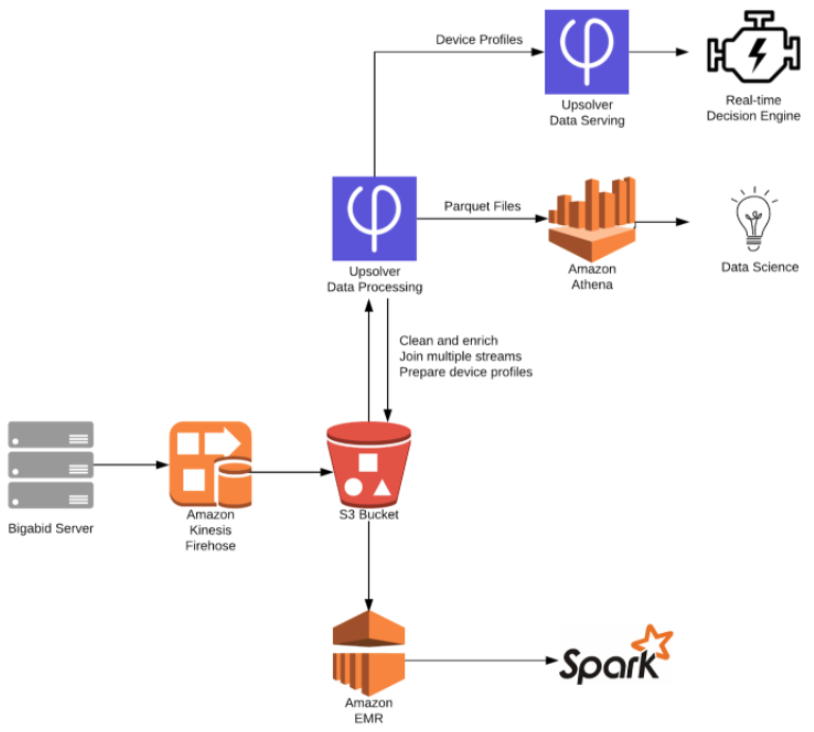
Advantages:
- 100% of the data is accessible (see above)
- No dependency on others for data modeling
- Minimal ETL
Examples of using Athena for research:
Looking for more Athena comparisons? Check out the following resources
Want to get even more in-depth into the pros and cons of Athena compared to other tools/ Check out Athena vs Google BigQuery performance and costs, or our comparison of Athena and Amazon Redshift. If you want to multiply the value your organization gets out of Athena and to easily build, manage and optimize your entire cloud data lake architecture, get a free demo of Upsolver today.
Want to master data engineering for Amazon Athena? Get the free resource bundle:
Learn everything you need to build performant cloud architecture on Amazon S3 with our ultimate Amazon Athena pack, including:
– Ebook: Partitioning data on S3 to improve Athena performance
– Recorded Webinar: Improving Athena + Looker Performance by 380%
– Recorded Webinar: 6 Must-know ETL tips for Amazon Athena
– Athena compared to Google BigQuery + performance benchmarks
And much more. Get the full bundle for FREE right here.
Published in:
Blog
,
Cloud Architecture
