
Explore our expert-made templates & start with the right one for you.
Custom Partitioning for Embedded Analytics with Athena
-
 Eran Levy
Eran Levy
- Use Cases
- February 13, 2020
The following article is an excerpt from our new guide: Compliant and Secure Cloud Data Lakes: 3 Practical Solutions (available now for FREE).
Almost any software or technology company offers some kind of built-in reporting to its customers. Embedded analytics is the term often used to describe customer-facing dashboards and analytics capabilities that allow end users of a company’s software to analyze data within that software.
In this article we will present a solution for building performant embedded analytics on streaming data using Amazon Athena. Upsolver will be used to ETL and partition the data on S3, which will help us run more efficient queries in Athena and ensure there is no intermingling of customer data in the dashboard that each customer sees.
The Challenge: Embedded Analytics for Multiple Customers
Let’s take a hypothetical scenario of an advertising technology company that programmatically places ads in real-time. The company works with many different advertisers and its ad units appear on different publisher websites. Apache Kafka is used to process ad-impression and ad-click streams generated by the ad unit on publisher websites, and the data is then written to S3.
The company would like each advertiser to be able to see a dashboard of overall ad unit performance per publisher website. Amazon Athena is used to query the data, while customers eventually interact with interactive dashboards that are embedded into the company’s SaaS product.
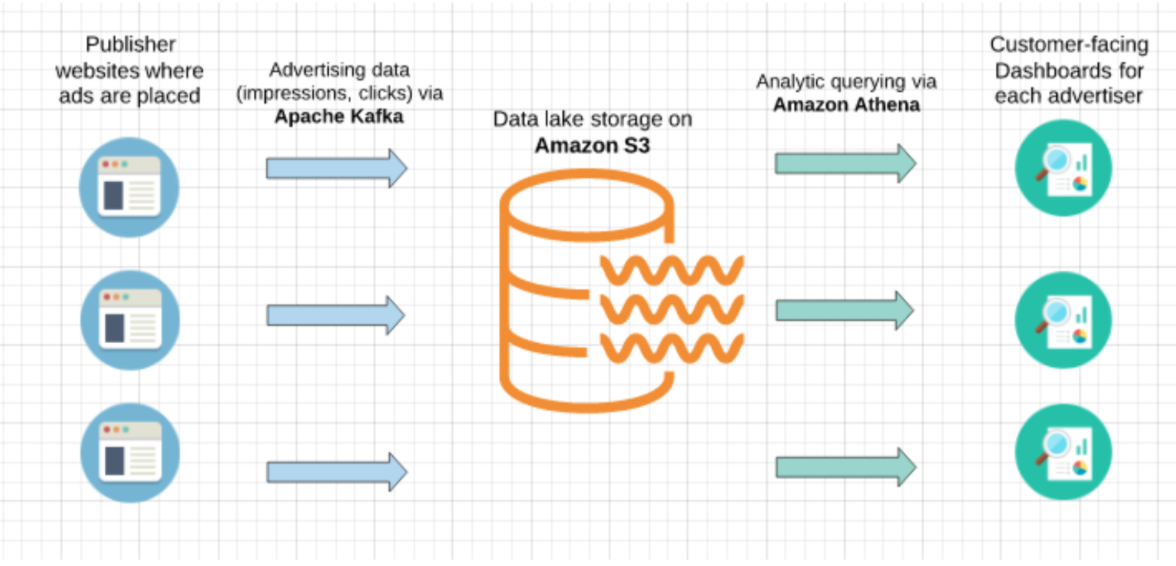
The challenge:
- Each customer should only have access to their own data
- Customers expect the embedded dashboards to show data in near real-time in order to understand how their campaigns are performing and pause or increase spend
The Solution: Custom Partitioning
Our solution is built on separating each customer’s data into its own partitions on S3, and then querying only that data in Amazon Athena.
Data partitioning for Athena
If you’re unfamiliar with how partitioning works in Athena, you should check out our previous article about partitioning data on S3. In short, folders where data is stored on S3, which are physical entities, are mapped to partitions, which are logical entities, in the Glue Data Catalog. Athena leverages partitions in order to retrieve the list of folders that contain relevant data for a query.
The most common way to partition data is by time – which is definitely what we will be using for time-series data such as ad impressions and clicks:
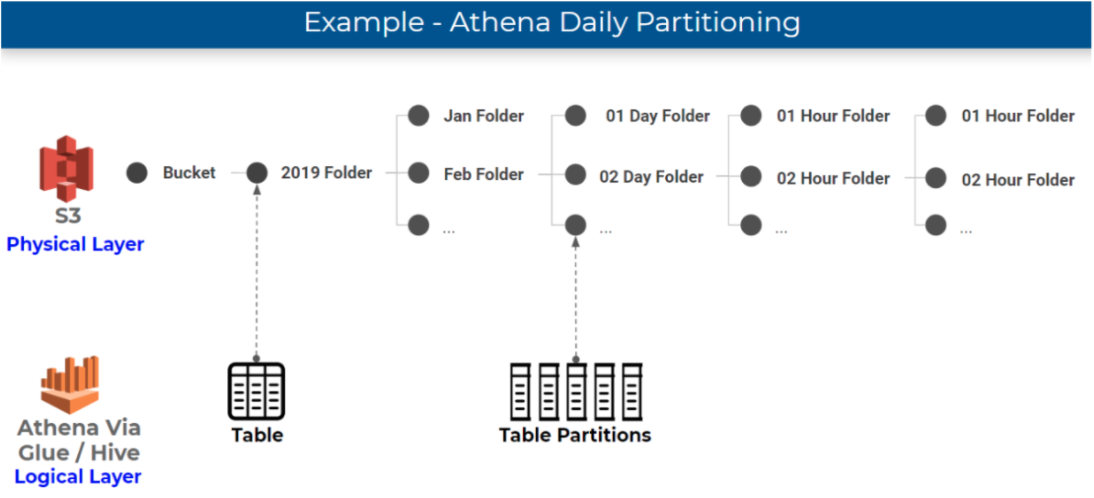
Efficient partitioning allows Athena to scan only the relevant data in order to retrieve a particular query, which reduces costs and improves performance. If the company in our example wants to see what was our average clickthrough rate for ad unit for a certain period in February, having the data partitioned by day allows us to ‘point’ Athena in the direction of that data using an SQL WHERE clause.
Custom partitioning by Customer ID
In our case we have another requirement – which is to separate each customer’s data. Each advertiser is exposed to a different dashboard, which sits on top of a different set of queries in Athena. Since we still want to minimize the amount of data scanned and ensure performance, each of these queries should only scan the data that is pertinent to that customer – which we will achieve by adding another layer to our partitioning strategy:
We’ll create custom partitions for each report we want to build in Athena so that each customer dashboard only queries that customer’s data: This is easy to do using Upsolver’s self-service data lake ETL, but if you’re not using Upsolver you can do it with whatever ETL code you are writing to ingest and partition data. Here’s how it would work:
- In addition to partitioning data by time, we will also be partitioning events by Customer ID – so that each ad impression and ad click is associated with a specific advertiser.
- As we are ingesting the data to S3, we will be writing each advertiser’s events to a separate partition.
- To ensure each advertiser only sees their own data, we will only give them permission to view the data in ‘their’ S3 partitions
- We’ll use the Customer ID in Athena to only query the relevant partitions for each dashboard.
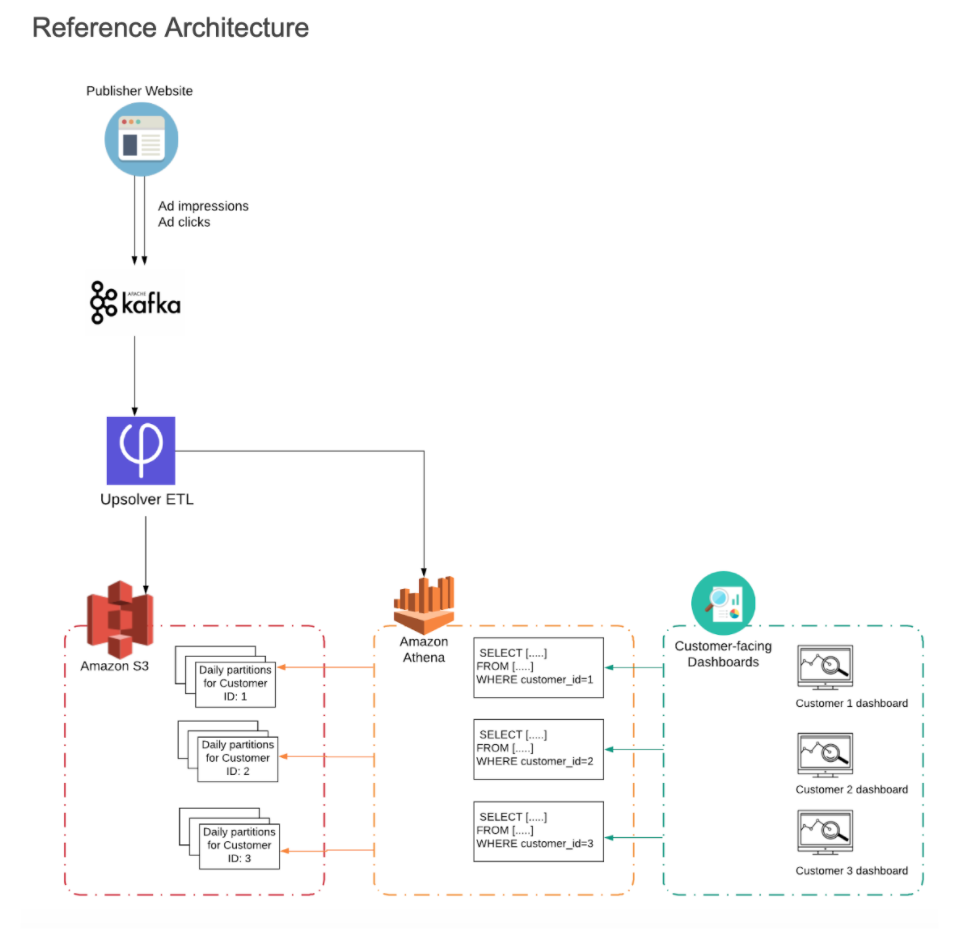
Building the Solution using Upsolver, S3 and Athena
In this section we’ll present a quick walkthrough on how to create custom partitions for embedded analytics in Athena, using Upsolver on AWS.
Step 1: Partition the data on S3
In the Data Source, we will tell Upsolver to partition the data by date as well as by a field within the data which will be Customer ID. As Upsolver ingests the data from Kafka, it will be partitioned by Customer ID and event time.

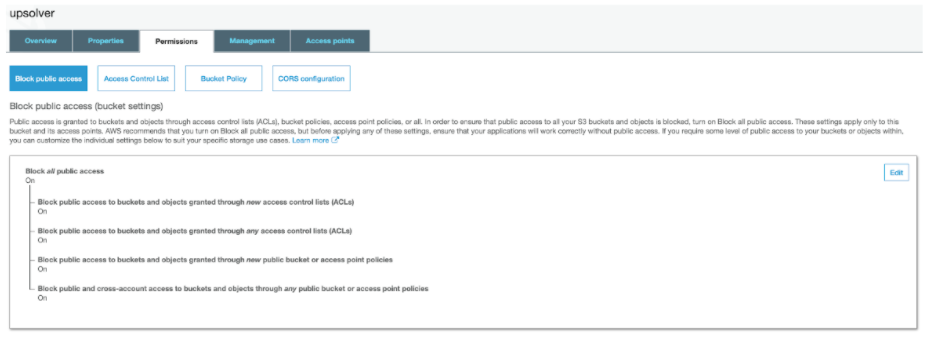
Step 2: Set S3 permissions
To prevent any possibility of ‘data leakage’ and ensure each customer only sees their own data, we will only grant each customer permission to read data from the partition that stores their data, based on the customer_id identifier. This is done in the S3 management console:
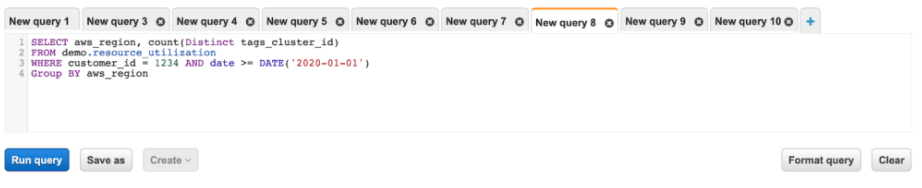
Step 3: Running the query in Athena
For each customer-facing dashboard, the Athena query that retrieves the relevant dataset will be specified to fetch the data from the partitions storing the relevant time-period as well as the relevant customer_id.
Step 4: Sharing data with customers
Typically customers would interact with a dashboard that sits ‘on top’ of Athena and visualizes the relevant dataset per customer_id. These dashboards might be developed in-house or using an embedded analytics solution such as Looker, Sisense, Tableau etc.
Want to learn more?
Find out more about partitioning strategy for Athena by watching our on-demand webinar: ETL for Amazon Athena: 6 Things You Must Know, or by reading our previous guide on ETLing Amazon Kinesis to Athena using SQL. Want to skip the coding in Spark/Hadoop and partition your data with just a few clicks? Schedule a demo of Upsolver.
Try SQLake for free (early access)
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
