
Explore our expert-made templates & start with the right one for you.
What is the Parquet File Format? Use Cases & Benefits
-
 Eran Levy
Eran Levy
- Cloud Architecture
- April 20, 2023
The following is an excerpt from our guide to big data file formats. Download this paper to gain a thorough understanding of the fundamental concepts and benefits of file formats in the big data realm, including best practices and ideal use cases. Read it here.
Since it was first introduced in 2013, Apache Parquet has seen widespread adoption as a free and open-source storage format for fast analytical querying. When AWS announced data lake export, they described Parquet as “2x faster to unload and consumes up to 6x less storage in Amazon S3, compared to text formats”. Converting data to columnar formats such as Parquet or ORC is also recommended as a means to improve the performance of Amazon Athena.
It’s clear that Apache Parquet plays an important role in system performance when working with data lakes.
In fact, Parquet is one of the main file formats supported by Upsolver, our all-SQL platform for transforming data in motion. It can input and output Parquet files, and uses Parquet as its default storage format. You can execute sample pipeline templates, or start building your own, in Upsolver for free.
Now, let’s take a closer look at what Parquet actually is, and why it matters for big data storage and analytics.
Basic Definition: What is Apache Parquet?
Apache Parquet is a file format designed to support fast data processing for complex data, with several notable characteristics:
1. Columnar: Unlike row-based formats such as CSV or Avro, Apache Parquet is column-oriented – meaning the values of each table column are stored next to each other, rather than those of each record:
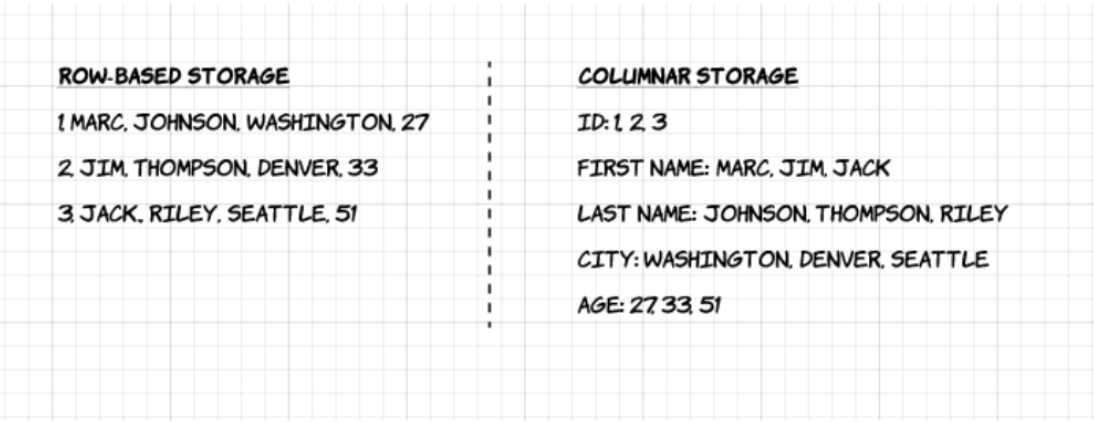
2. Open-source: Parquet is free to use and open source under the Apache Hadoop license, and is compatible with most Hadoop data processing frameworks. To quote the project website, “Apache Parquet is… available to any project… regardless of the choice of data processing framework, data model, or programming language.”
3. Self-describing: In addition to data, a Parquet file contains metadata including schema and structure. Each file stores both the data and the standards used for accessing each record – making it easier to decouple services that write, store, and read Parquet files.
Advantages of Parquet Columnar Storage – Why Should You Use It?
The above characteristics of the Apache Parquet file format create several distinct benefits when it comes to storing and analyzing large volumes of data. Let’s look at some of them in more depth.
Compression
File compression is the act of taking a file and making it smaller. In Parquet, compression is performed column by column and it is built to support flexible compression options and extendable encoding schemas per data type – e.g., different encoding can be used for compressing integer and string data.
Parquet data can be compressed using these encoding methods:
- Dictionary encoding: this is enabled automatically and dynamically for data with a small number of unique values.
- Bit packing: Storage of integers is usually done with dedicated 32 or 64 bits per integer. This allows more efficient storage of small integers.
- Run length encoding (RLE): when the same value occurs multiple times, a single value is stored once along with the number of occurrences. Parquet implements a combined version of bit packing and RLE, in which the encoding switches based on which produces the best compression results.

Performance
As opposed to row-based file formats like CSV, Parquet is optimized for performance. When running queries on your Parquet-based file-system, you can focus only on the relevant data very quickly. Moreover, the amount of data scanned will be way smaller and will result in less I/O usage. To understand this, let’s look a bit deeper into how Parquet files are structured.
As we mentioned above, Parquet is a self-described format, so each file contains both data and metadata. Parquet files are composed of row groups, header and footer. Each row group contains data from the same columns. The same columns are stored together in each row group:
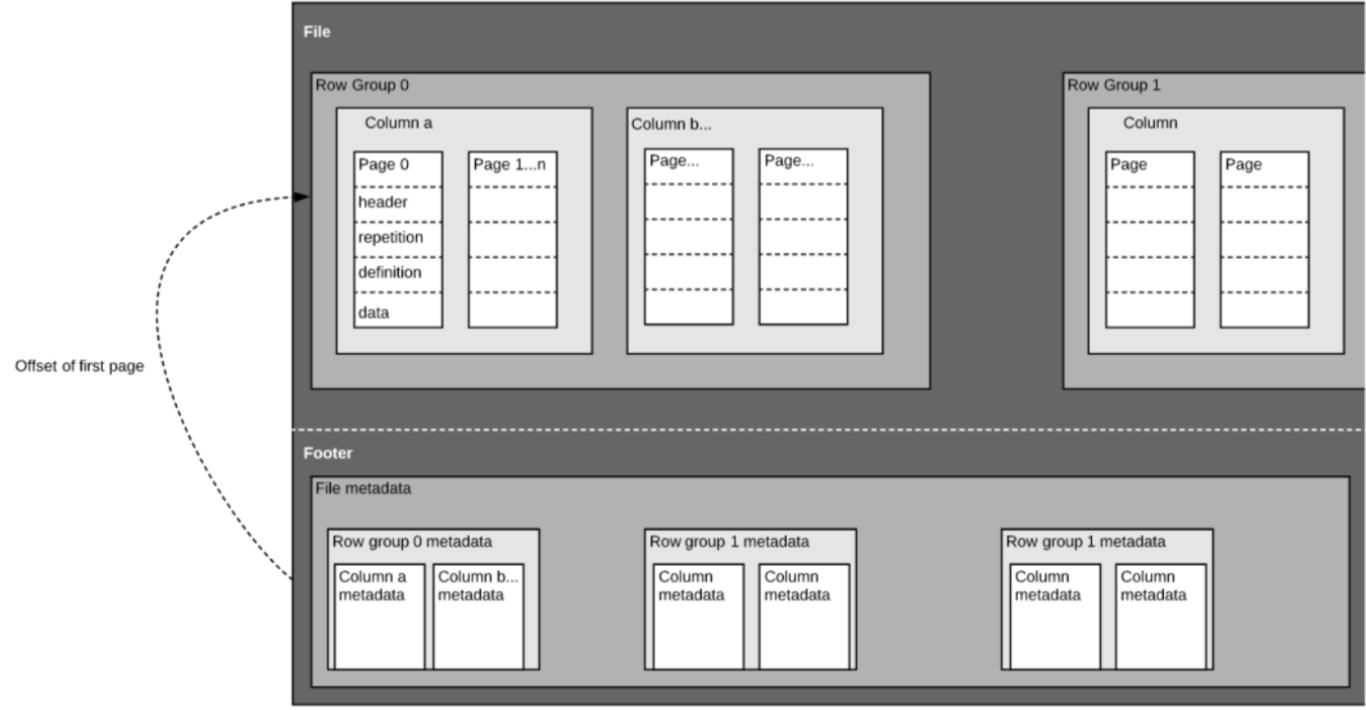
This structure is well-optimized both for fast query performance, as well as low I/O (minimizing the amount of data scanned). For example, if you have a table with 1000 columns, which you will usually only query using a small subset of columns. Using Parquet files will enable you to fetch only the required columns and their values, load those in memory and answer the query. If a row-based file format like CSV was used, the entire table would have to have been loaded in memory, resulting in increased I/O and worse performance.
Schema evolution
When using columnar file formats like Parquet, users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. In these cases, Parquet supports automatic schema merging among these files.
Open source and non-proprietary
Apache Parquet is part of the open-source Apache Hadoop ecosystem. Development efforts around it are active, and it is being constantly improved and maintained by a strong community of users and developers.
Storing your data in open formats means you avoid vendor lock-in and increase your flexibility, compared to proprietary file formats used by many modern high-performance databases. This means you can use various query engines such as Amazon Athena, Qubole, and Amazon Redshift Spectrum, within the same data lake architecture, rather than being tied down to a specific database vendor.
Column-Oriented vs Row-Based Storage for Analytic Querying
Data is often generated and more easily conceptualized in rows. We are used to thinking in terms of Excel spreadsheets, where we can see all the data relevant to a specific record in one neat and organized row. However, for large-scale analytical querying, columnar storage comes with significant advantages with regards to cost and performance.
Complex data such as logs and event streams would need to be represented as a table with hundreds or thousands of columns, and many millions of rows. Storing this table in a row based format such as CSV would mean:
- Queries will take longer to run since more data needs to be scanned, rather than only querying the subset of columns we need to answer a query (which typically requires aggregating based on dimension or category)
- Storage will be more costly since CSVs are not compressed as efficiently as Parquet
Columnar formats provide better compression and improved performance out-of-the-box, and enable you to query data vertically – column by column.
Apache Parquet Use Cases – When Should You Use It?
While this isn’t a comprehensive list, a few telltale signs that you should be storing data in Parquet include:
- When you’re working with very large amounts of data. Parquet is built for performance and effective compression. Various benchmarking tests that have compared processing times for SQL queries on Parquet vs formats such as Avro or CSV (including the one described in this article, as well as this one), have found that querying Parquet results in significantly speedier queries.
- When your full dataset has many columns, but you only need to access a subset. Due to the growing complexity of the business data you are recording, you might find that instead of collecting 20 fields for each data event you’re now capturing 100+. While this data is easy to store in a data lake, querying it will require scanning a significant amount of data if stored in row-based formats. Parquet’s columnar and self-describing nature allows you to only pull the required columns needed to answer a specific query, reducing the amount of data processed.
When you want multiple services to consume the same data from object storage. While database vendors such as Oracle and Snowflake prefer you store your data in a proprietary format that only their tools can read, modern data architecture is biased towards decoupling storage from compute. If you want to work with multiple analytics services to answer different use cases, you should store data in Parquet. (Read more about data pipeline architecture)
Parquet vs ORC
Apache Parquet and Optimized Row Columnar (ORC) are two popular big data file formats. Both have unique advantages depending on your use case:
Operating efficiencies:
- Write efficiency: ORC is better suited for write-heavy operations due to its row-based storage format. It provides better writing speeds when compared to Parquet, especially when dealing with evolving schema.
- Read efficiency: Parquet excels in write-once, read-many analytics scenarios, offering highly efficient data compression and decompression. It supports data skipping, which allows for queries to return specific column values while skipping the entire row of data, leading to minimized I/O. This can make ORC useful in scenarios where you have a large number of columns in the dataset, and a need to access only specific subsets of data.
- Compatibility: ORC is highly compatible with the Hive ecosystem, providing benefits like ACID transaction support when working with Apache Hive. However, Parquet offers broader accessibility, supporting multiple programming languages like Java, C++, and Python, making it usable in almost any big data setting. It is also used across multiple query engines such as Amazon Athena, Amazon Redshift Spectrum, Qubole, Google BigQuery, Microsoft Azure Data Explorer, and Apache Drill.
- Compression: Both ORC and Parquet offer multiple compression options and support schema evolution. However, Parquet is often chosen over ORC when compression is the primary criterion, as it results in smaller file sizes with extremely efficient compression and encoding schemes. It can also support specific compression schemes on a per-column basis, further optimizing stored data.
To learn about how Parquet compares to other file formats, check out our comparison between Parquet vs Avro vs ORC
Example: Writing Parquet Files to S3 –
We’ve explored this example in far greater depth in our recent webinar with Looker. Watch the recording here.
To demonstrate the impact of columnar Parquet storage compared to row-based alternatives, let’s look at what happens when you use Amazon Athena to query data stored on Amazon S3 in both cases.
Using Upsolver, we ingested a CSV dataset of server logs to S3. In a common AWS data lake architecture, Athena would be used to query the data directly from S3. These queries can then be visualized using interactive data visualization tools such Tableau or Looker.
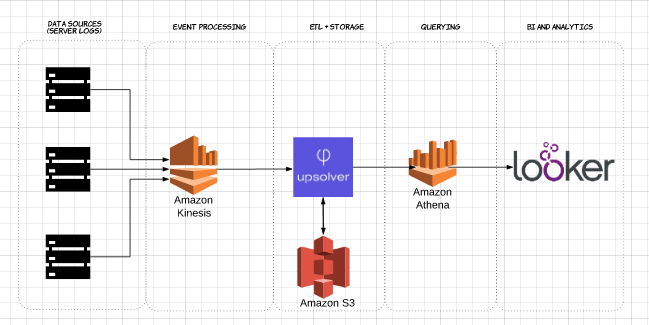
We tested Athena against the same dataset stored as compressed CSV, and as Apache Parquet.
This is the query we ran in Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage FROM server_usage GROUP BY tags_host HAVING AVG(fields_usage_active) > 0 LIMIT 10
And the results:
| CSV | Parquet | Columns | |
| Query time (seconds) | 735 | 211 | 18 |
| Data scanned (GB) | 372.2 | 10.29 | 18 |
- Compressed CSVs: The compressed CSV has 18 columns and weighs 27 GB on S3. Athena has to scan the entire CSV file to answer the query, so we would be paying for 27 GB of data scanned. At higher scales, this would also negatively impact performance.
- Parquet: Converting our compressed CSV files to Apache Parquet, you end up with a similar amount of data in S3. However, because Parquet is columnar, Athena needs to read only the columns that are relevant for the query being run – a small subset of the data. In this case, Athena had to scan 0.22 GB of data, so instead of paying for 27 GB of data scanned we pay only for 0.22 GB.
Is Using Parquet Enough?
Using Parquet is a good start; however, optimizing data lake queries doesn’t end there. You often need to clean, enrich and transform the data, perform high-cardinality joins and implement a host of best practices in order to ensure queries are consistently answered quickly and cost-effectively.
Upsolver lets you build and run reliable self-orchestrating data pipelines on streaming and batch data via an all-SQL experience. You can use Upsolver to simplify your data lake pipelines, automatically ingest data as optimized Parquet, and transform streaming data with SQL or Excel-like functions. Try it for free for 30 days. No credit card required. You can also schedule a demo to learn more.
Next Steps
- Check out some of these data lake best practices.
- Read about building big data ingestion pipelines
- Learn about the advantages of storing nested data as Parquet.
- Read our new guide to compliant and secure data lakes.
Published in:
Blog
,
Cloud Architecture