
Explore our expert-made templates & start with the right one for you.
6 Data Preparation Tips for Querying Big Data in AWS Athena
-
 Eran Levy
Eran Levy
- Cloud Architecture
- October 2, 2019
Last updated: February 12, 2021
The following article is an abridged version of our recent webinar ETL for Amazon Athena: 6 Things You Must Know, presented by Upsolver Co-founder Ori Rafael. Watch the full webinar for free, or read on for the overview.
A vast majority of Upsolver customers use Amazon Athena, and their feedback is the base for this webinar today. We’ve found that effective data preparation can significantly reduce costs and improve performance.
Amazon Athena – the Basics
For those who don’t know the service, Amazon Athena is a SQL engine. It runs on top of Amazon S3, so you write this basic SQL and that runs as a query on S3.
Athena runs in a distributed manner. It’s based on an open source tool called Apache Presto that was developed in Facebook. Similarly to Presto, Athena can provide very good performance and is run in a serverless manner. So it’s very easy to use and you only pay for what you actually query, $5 dollars per terabyte scanned. What we are seeing is that using Athena for analytic workloads is often a much more cost-effective solution compared to a data warehouse and also a much easier solution when it comes to maintenance.
The use cases that companies have for Athena are usually around analytics at large scale or research. So IoT analytics, campaign performance, how your application is being used and analysis of web traffic. All of these can be done using SQL on top of the raw data that you have on S3.
Why We Need ETL for Amazon Athena
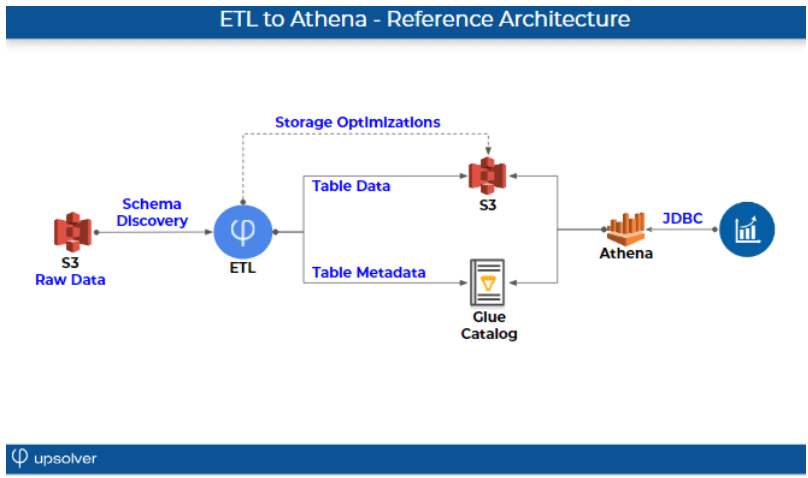
So the topic today is ETL for Athena. Above you can see the reference architectures, and those are the steps in order to do ETL to Athena. On the left hand side you can see you have raw data on S3, but it’s just a bunch of files on S3. In order to do ETL you actually need to create some kind of structure from the data.
Since we’re dealing with raw data on S3, we’ll need to connect some kind of metadata and schema. And for that we are using the AWS Glue Data Catalog. The combination of both of them allows Athena to actually run the SQL that we talked about before.
Another step, which is very important is optimization. So Athena is a compute engine, it will perform as well as you optimize your storage. So the ETL to Athena needs to actually run those performance tuning tips that we can find in Amazon documentation on top of S3, and we’ll talk about it in length today as part of the webinar (you can also check out our previous article on improving Athena performance).
I think the last thing to keep in mind, Athena is an amazing service, but sometimes people think that it’s a database. It’s actually a compute engine, not exactly a database, and that’s the reason why ETL for Athena is different than database ETL. Athena doesn’t have insert update or delete API. It queries the data that you prepared on S3. It doesn’t automatically optimize the data for performance because it’s a compute engine, and it doesn’t include indexing. So those kind of limitations are the reasons that ETL for Athena is a bit different than database ETL.
All of those are best practices that need to be implemented for Athena to work properly. So the reason we’re doing ETL and data preparation for Athena is first of all to get faster queries, and if you get faster queries probably means you’re scanning less data and therefore you are paying less for your usage of Athena.
The second is that it’s very common to add some more functionality to Athena, specifically around joins and around use cases that have updates and deletes and not append-only data. We’ll touch that as part of the webinar as well. And I think the last ones says there are many best practices you need to follow. Usually those best practices are implemented using Spark code, Hadoop and other open sources to orchestrate this kind of workflow. This creates a lot of overhead for R&D or data engineering departments.
Let’s take a look at the 6 things you need to keep in mind when building out ETL workflows for effectively consuming data in Athena.
1. Schema-on-read
So imagine that you have raw log or event data on Amazon S3. Now you want to create an ETL. It’s just a bunch of files. You don’t know the structure, you don’t know what kind of data you have for each field in the data. And the way to solve that challenge is to create a schema-on-read to understand what’s actually inside S3. And that’s something that the ETL layer should take care of.
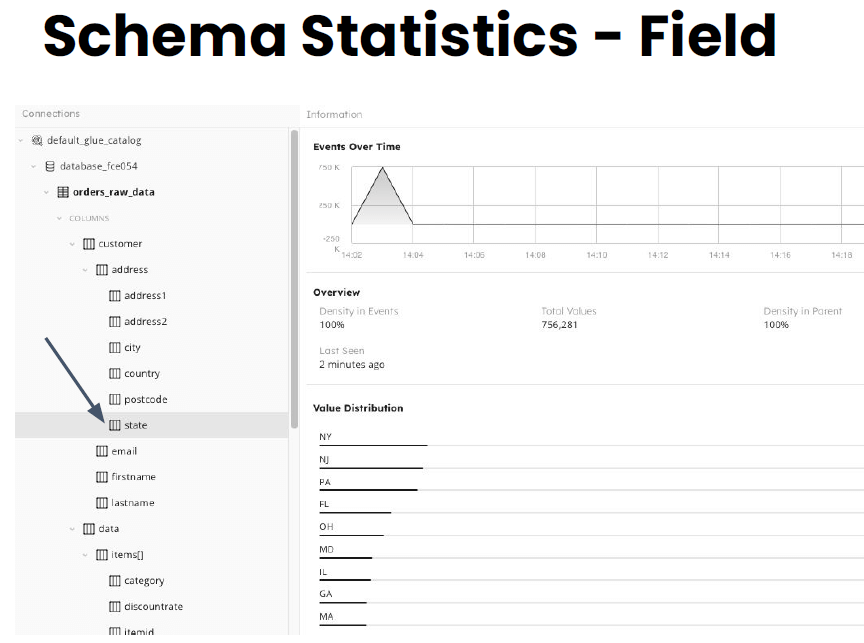
You automatically infer the schema from the raw data. The things that you need to keep in mind is nested data is usually a bit more complex to discover, especially with array kind of use cases. How are you going to collect statistics for every field? That’s what’s the value distribution per field is maybe the most common question we hear talking to customers that want to use Athena.
And the last thing to keep in mind is whether you have a live schema. It’s schema-on-read. Every time there are new fields the schema evolves. You need to change the schema, reflect that to the users, maybe they want to take those changes and add them to tables in Athena. Below you can see a screenshot of how schema is visualized in Upsolver SQLake with those statistics per field. (SQLake is Upsolver’s newest offering. It lets you build and run reliable self-orchestrating data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.)
2. Data Partitioning
The second point we wanted to cover is data partitioning. And data partitioning is similar to what you did in databases. You partition your data because it allows you to scan less data, and it makes it easier to enforce data retention. With databases we are used to just adding and removing partitions at will. With Athena the metadata actually resides in the AWS Glue Data Catalog and the physical data sits on S3.
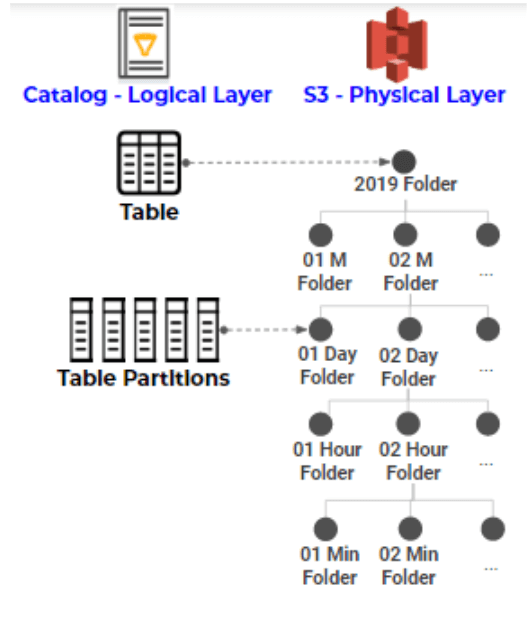
And you need to tell Glue those are also the partitions. So for example, if we’re partitioning by day. Your one day is one table partition. And that’s how Athena would know to scan less data if you filter by time. This is partitioning by time. So the synchronization of S3 and Glue Data Catalog is the thing you need to master to do partitioning in Athena.
The second thing would it be to choose your best strategy for partitioning, and that strategy would change according to the use case. And you need to be careful about the number of partitions you create. So a good rule of thumb is that every 500 partitions you want to scan, probably you’re adding one second of latency to your query. So balancing the number of partitions with the use case is the thing that you need to master.
We’ve covered this topic in-depth in a previous article: read more about partitioning data on S3.
3. Dealing with Small and Large Files
Another thing we need to consider when it comes to storage is the size of the files that you’re going to use. So, most of our customers want to see data in Athena in as fast as possible to get the best data freshness in their dashboards and analytic queries. That means that we are using one minute files. Every one minute we’re creating a file, putting it into Athena and you’re seeing your data in Athena within two or three minutes since it was generated. The challenge here is that small files create a performance problem for Athena. And the number of files dramatically impacts performance. We have seen, we have measured about a 100x difference in some cases.
So the ETL to Athena has two steps. One is to create those small files, and you already see the data in Athena. The second would be to run a process called compaction. That process take those small files, combines them into bigger files, and those bigger files improve the performance you’re getting in Athena.
This is another topic we’ve covered in a lot of depth, and you should definitely check that article out here.
4. Joins
Joining data is very basic functionality that pretty much all of our customers require. You always want to combine different sorts of data. That’s basically the purpose of analytics. And you can do some of those joins in Athena, but some of them you would need to take to the ETL layer:
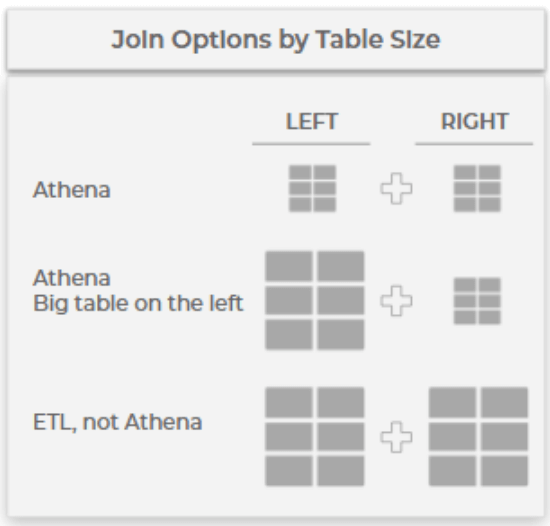
Athena doesn’t have indexes. So for each row on the left side, you would need to scan the entire table on the right side, maybe with some optimization, but that’s the basic concept without indexing.
If you have small tables, really not an issue. If you’re joining two small tables, do it in Athena. If you are joining one big table, let’s say that would be your events table and a smaller table, that would be a lookup table. You could still do it in Athena, but AWS recommend that you put the bigger table on the left side of the join, and you would get better performance still staying within the Athena realm.
The last use case in which you want to join two big tables, for example you have a funnel of events and you want to join to different stages within that funnel. That would be done in the ETL layer. The reason is that joining two big tables without indexing just is not something that can perform very well. So first of all, understand where you want to do your join, and decide if it’s in Athena or in the ETL level.
The second thing, if you are doing it in the ETL level is what are the data freshness requirements? Do you need to get the data joined in real time? So you need to take a streaming approach, or you can run those join may be once a day using a batch process. And in that case you can rely on traditional batch processing operation and do that join.
That is a very significant requirement, so if you want to do fast join you probably need to use an additionalNoSQL database to serve as your index. There’s simply no way to do a big join fast without an index. And that index is often implemented by companies using a NoSQL database like DynamoDB, Redis, Cassandra, Aerospike. All of those would be possible options.
If you’re doing the join in RAM, you need to make sure that the volume of data that you’re putting in RAM doesn’t exceed the size of the instance you have. So you might need to do some optimizations to the instances running that ETL if you are choosing the approach on the left side doing that join in RAM. We often see Spark with Cassandra for example as a combination of an ETL. And the ETL index that allows to do those kinds of joins.
5. Updates and Deletes
This is actually a very hot topic at the moment, we’re getting asked about it on a daily basis, and the reason is that companies want to take databases that they have on premise for example, and replicate them into data lakes. Often the difficulty they run into is that Athena doesn’t have an update or delete interface. You will need to rewrite the data every time you want to update or delete, which would mean performing full table scans. That’s not something that can easily be done. Definitely not at high scale, but even at medium scale it’s going to be very challenging.
Another issue is compliance with things like GDPR or the California Privacy Act, which might require companies to delete single user information from Athena. So you would need that delete operation to allow a user to delete their own personal data in a reasonable timeframe.
So how do we do it on the ETL layer, since Athena doesn’t have that update and delete interface? We are using an approach of a table and a view. So you’re using a view to create a consistent results of the data. For example, the view would return the latest information for a table.
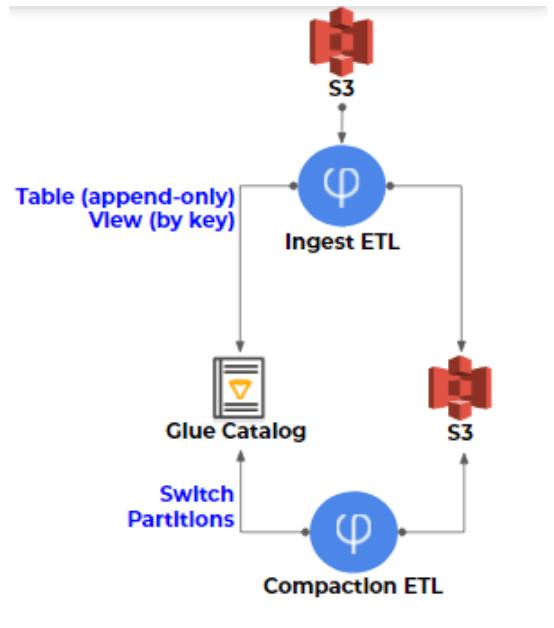
But the problem is that if the table has many different events and each event has its key, and each event could be in a different point in time, you wouldn’t get good query performance. So again, we’re returning to the same kind of solution we had for the small and big files problems.
The solution is called compaction, and you need to rewrite the historical data, apply those updates to remove the data. This is part of the solution we’ve implemented in Upsolver SQLake, in which we’ve automated all of the “ugly plumbing” of building and maintaining data pipelines; to the best of our knowledge is one-of-a-kind and not provided by any other tool on the market today.
6. Dealing with ETL Complexity
The last tip, or the last point I would like to mention is what are your ETL development options for Athena today. So if you’re using AWS, you would probably use Firehose as a service to ingest your data into S3. So now you have that copy of raw data available. You would run Glue color to discover the schema-on-read. So you would be able to actually write ETL. Then implement the ETL in Glue using Pi Spark code for transformation and use DynamoDB as the index if you want to run the joins we talked about before.
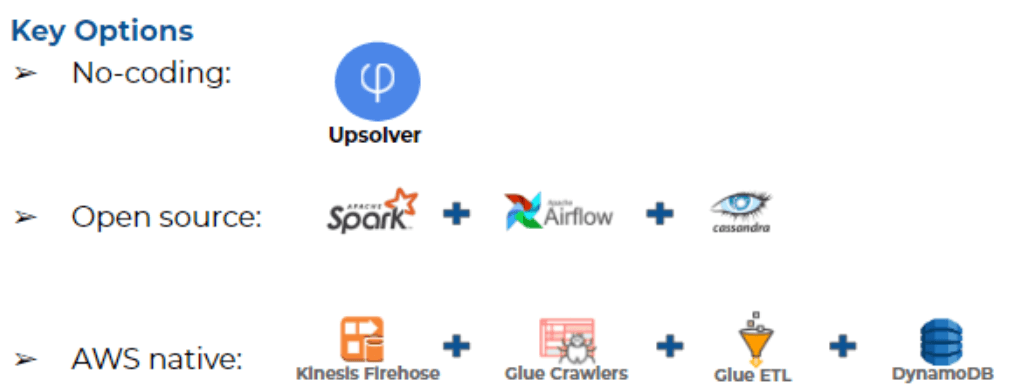
If you are taking an open source approach, the commentary that we have seen is writing an ETL job in Spark, orchestrating the ETL jobs with Airflow and using Cassandra as the NoSQL database as the index for everything – that’s something many organizations struggle with, especially if they don’t have an army of experienced big data engineers in house. The difference with Upsolver SQLake is that you don’t need to do all of that; you can use one platform that doesn’t require any coding to make the data useful in Athena.
The primary KPIs we see companies use for POCs (at least from a functional standpoint) to evaluate the different options are:
- The time it takes to create a single table
- The time it takes to change that table — for example, to add a new column (a very common use case)
- Who the actual user is who’s writing those ETLs. That is, do you need a big data engineer to run that process and use code, and that engineer then would serve all customers within the organization (developers, data analysts, and so on)? Or can you give the platform to the data analyst so they would create the table in Athena based on raw data?
To see a live demo of how we implement end-to-end ETL for Amazon Athena, watch the webinar now for free. Prefer a more hands-on approach? Try SQLake for free — no credit card required. With SQLake building and deploying a declarative data pipeline for batch or streaming data is as simple as writing a SQL query. Choose from our gallery of customizable templates to get started right away. You can also learn more about SQLake here.
Published in:
Blog
,
Cloud Architecture