Explore our expert-made templates & start with the right one for you.
Welcome Data Pipeline Practitioners
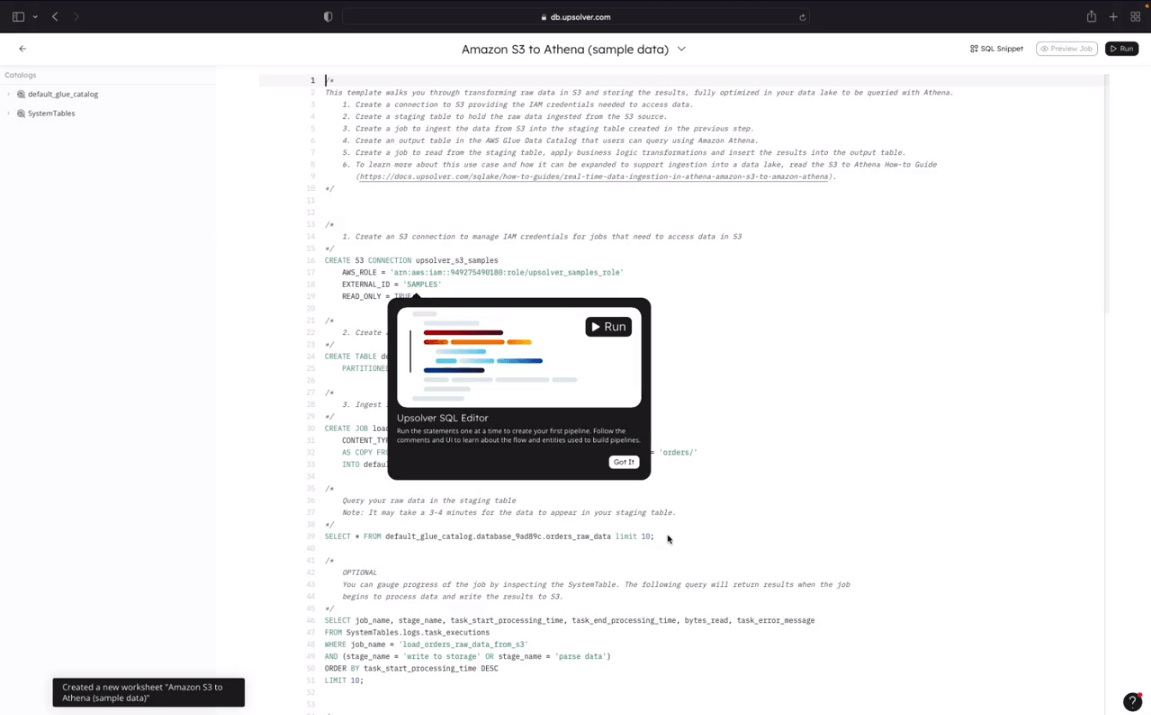
Get started quickly with these step-by-step SQLake tutorials.
Get started quickly with these step-by-step SQLake tutorials.
Explore our expert-made templates & start with the right one for you.