Explore our expert-made templates & start with the right one for you.
Loading Semi-Structured or Unstructured Nested Data into Snowflake Using VARIANT Data Type
Ingest, Transform and Load Data into Snowflake in 4 Steps
Upsolver SQLake makes it easy to ingest raw data from a variety of sources (such as Amazon S3, Apache Kafka, and Amazon Kinesis Data Streams) into your data lake and data warehouse (such as Snowflake). Raw data could be structured in many different ways – comma or tab separated, fixed-length, or nested including structs and arrays.
Oftentimes, companies want to store the raw data in its original structure in a landing zone inside the data warehouse. Snowflake introduced the VARIANT data type for this purpose. You can store nested JSON, arrays, objects, and any other type of data inside of this versatile type. In this tutorial, you will learn how to ingest a semi-structured or unstructured dataset into Snowflake, using the VARIANT data type to store a deeply-nested data structure.
To build this pipeline, follow these 4 steps
- Create connection to the source data in S3
- Create connection to the target table in Snowflake
- Ingest raw data into the data lake staging table
- Load semi-structured/unstructured data into Snowflake
Let’s walk through them.
1. Create connection to the source data in S3
Create a connection to your source data in S3. Connections in SQLake store the credentials and access information to connect to the system in question.
CREATE S3 CONNECTION s3_conn
AWS_ROLE = 'arn:aws:iam::949275490180:role/upsolver_samples_role'
EXTERNAL_ID = 'SAMPLES'
READ_ONLY = TRUE;
2. Create connection to the target table in Snowflake
Create a connection to Snowflake. This enables SQLake to load data into the target table.
CREATE SNOWFLAKE CONNECTION sf_conn
CONNECTION_STRING = 'jdbc:snowflake://<account>.<region>.aws.snowflakecomputing.com/?db=<dbname>'
USER_NAME = '<username>'
PASSWORD = '<password>';
3. Ingest raw data into the data lake staging table
Now create a staging table in the data lake and load the source semi-structured data into it. This enables us to maintain a copy of the source data in case any corruption requires you to reprocess the events.
Create the staging table in the AWS Glue Data Catalog. SQLake automatically detects the source schema and updates the catalog with the column names, data types, and partition information.
CREATE TABLE default_glue_catalog.database_e809da.orders_raw_staging PARTITIONED BY $event_date;
Create the ingestion job that will copy raw events from the source S3 bucket and insert them into the staging data lake table.
CREATE SYNC JOB load_orders_raw
START_FROM = BEGINNING
DATE_PATTERN = 'yyyy/MM/dd/HH/mm'
CONTENT_TYPE = JSON
AS COPY FROM S3 s3_conn
BUCKET = 'upsolver-samples'
PREFIX = 'orders/'
INTO default_glue_catalog.database_e809da.orders_raw_staging;
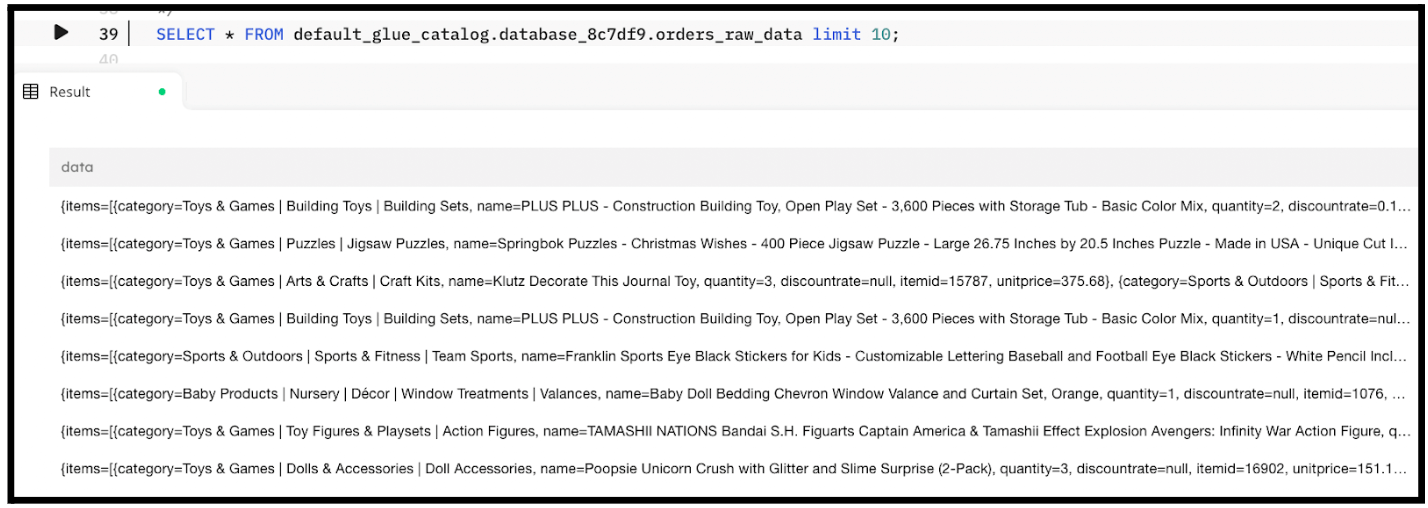
Once the job is created it will take a minute or two before the table begins to populate. You can execute a SELECT query from within SQLake to inspect the staging table as follows:
SELECT * FROM default_glue_catalog.database_e809da.orders_raw_staging LIMIT 10;
The query should return a result similar to the following.
4. Load semi-structured/unstructured data into Snowflake
Navigate to your Snowflake console and create the target table that will hold the semi-structured or unstructured data you ingested into the data lake in the previous step. You can execute the following SQL in a Snowflake worksheet:
CREATE TABLE DEMO.RAW_ORDER_DATA ( ORDER_ID VARCHAR, ORDER_DATE DATE, ORDER_TYPE VARCHAR, CUSTOMER VARIANT, SHIPPING_INFO VARIANT, ITEMS_INFO VARIANT );
Next create a job in SQLake that will read from the staging table and transform and slightly model the data before loading it into the target table in Snowflake. The customer, shippinginfo and items_info columns are stored VARIANT data types when they are loaded into Snowflake.
CREATE SYNC JOB load_raw_data_into_sf
RUN_INTERVAL = 1 MINUTE
START_FROM = BEGINNING
AS INSERT INTO SNOWFLAKE "SnowFlake Connection"."DEMO"."RAW_ORDER_DATA"
MAP_COLUMNS_BY_NAME
SELECT
orderid AS ORDER_ID,
extract_timestamp(orderdate::string) AS ORDER_DATE,
ordertype AS ORDER_TYPE,
customer AS CUSTOMER,
shippinginfo AS SHIPPING_INFO,
data.items[] AS ITEMS_INFO
FROM default_glue_catalog.database_e809da.orders_raw_staging
WHERE $event_time BETWEEN run_start_time() AND run_end_time();
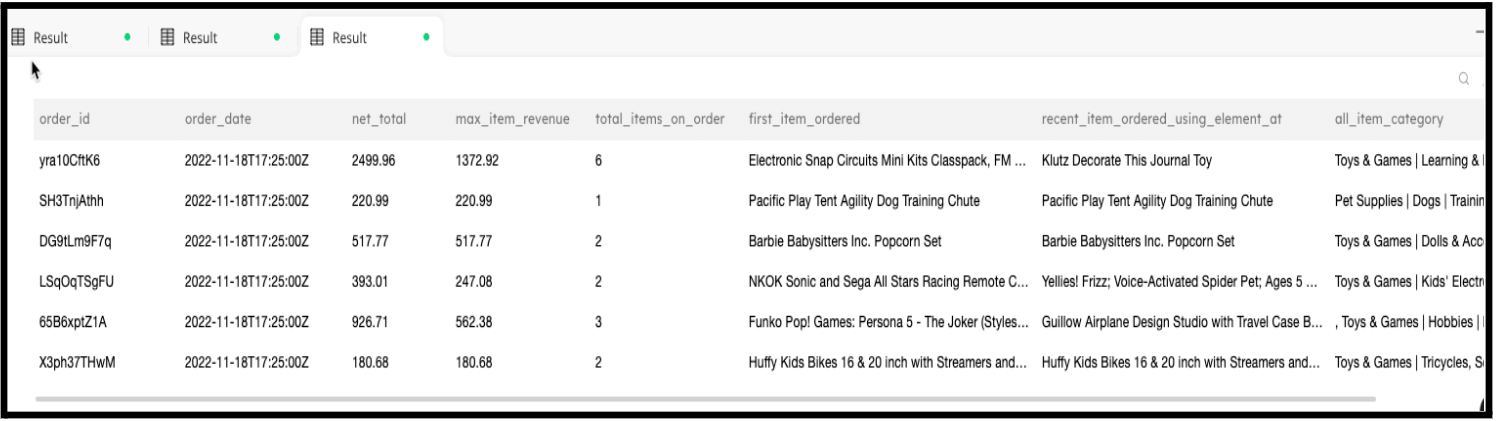
Execute the job and SQLake begins to load data into Snowflake. Give it a minute or two to process the data and then navigate to the Snowflake console and query the RAW_ORDER_DATA table. You should see an output similar to the following.
Summary
In this tutorial you saw how SQLake makes it easy to ingest semi-structured/unstructured data into your Snowflake data warehouse. Data is first staged in the data lake to maintain a historical record of the raw data in case you need to reprocess it or use it for use cases such as training an ML model. You then create a transform-and-load job that reads from the staging table and loads the data into Snowflake. We then used the Snowflake VARIANT data type to store the original nested data structures so that analysts and data consumers can manipulate it as they see fit.
Get started today for free with sample data or bring your own.
Discover how companies like yours use Upsolver
Data preparation for Amazon Athena.
Browsi replaced Spark, Lambda, and EMR with Upsolver’s self-service data integration.
Read case studyBuilding a multi-purpose data lake.
ironSource operationalizes petabyte-scale streaming data.
Read case studyDatabase replication and CDC.
Peer39 chose Upsolver over Databricks to migrate from Netezza to the Cloud.
Read case studyReal-time machine learning.
Bigabid chose Upsolver Lookup Tables over Redis and DynamoDB for low-latency data serving.
Read case study
Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products