Explore our expert-made templates & start with the right one for you.
Parsing JSON Arrays Using SQLake
A simple way to to parse JSON arrays using SQL
Semi-structured data such as JSON often contains nested structures that make it easy to collocate related information. For example, it’s efficient to store a user’s address information in a nested structure such as:
“first_name”: “Billy Bob”
“address”: {
“street”: “1234 hollywood blvd”,
“city: “Los Angeles”,
“zip”: “90210”
}
If you query this data, instead of having to select each individual piece of information, you simply need to select first_name and address fields to get all of the information you need. Similarly, you can use arrays to store a list of items such as items in a cart, sensor readings, and so on . Here’s an example of storing items in the cart:
“first_name”: “Billy Bob”,
“address”: {
“street”: “1234 hollywood blvd”,
“city: “Los Angeles”,
“zip”: “90210”
},
“items_in_cart”: [
“Toothbrush”,
“Protein bar”,
“Water bottle”
]
Using nested structures and arrays is common in application development. These objects make their way into datasets that must be prepared, transformed, and modeled before they are published for data analysts to analyze and build dashboards. Upsolver SQLake provides several pre-built functions that make it easy to traverse, unnest, and flatten arrays. In this tutorial we share a few examples of how to parse JSON arrays using SQL and pre-built functions.
To demonstrate SQLake’s capabilities, we’ll use a dataset of orders. Each row is an array of order items that include the item’s name, category, quantity, and so on. Here is snippet of what the data looks like:
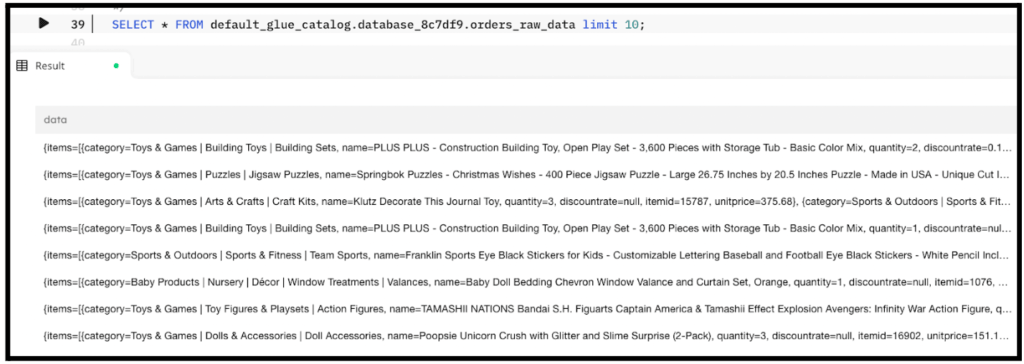
Given this dataset, we want to answer the following questions:
- What is the total revenue per order?
- What is the most expensive item per order?
- What are the total items per order?
- What are all the categories per order?
How SQLake Simplifies Parsing and Using JSON Arrays
There are four steps involved:
- Create a staging table in the data lake
- Create a job to copy the raw data into the staging table
- Create a job to parse the arrays into a modeled table
- Query the results
Let’s walk through the steps.
1. Create a staging table in the data lake
Staging tables are used to store a raw and immutable copy of the data that is read from the source system. Staging tables do not require schema to be defined in advance, since SQLake automatically detects and updates the schema. A best practice is to partition your staging table by $event_date, an automatically-generated system column which is the date of the incoming event.
CREATE TABLE default_glue_catalog.database_2777eb.stg_orders_raw_data PARTITIONED BY $event_date;
Note that we are partitioning the table based on a system column called $event_date. However, you can replace this column with any other column you think would be a good partition column for your data.
2. Create a job to copy the raw data into the staging table
Create an ingestion job to copy the raw data from the source S3 bucket and store it in the data lake staging table. The data is copied continuously, minute by minute, with SQLake automatically handling all table management (partitioning, compaction, cataloging, and so on).
CREATE SYNC JOB ingest_orders_raw_from_s3 CONTENT_TYPE = JSON AS COPY FROM S3 upsolver_s3_samples BUCKET = 'upsolver-samples' PREFIX = 'orders/' INTO default_glue_catalog.database_2777eb.stg_orders_raw_data;
After you execute the command, it takes a minute or two before data is available in the staging table. At that point you can query it from SQLake or from your favorite data lake query engine. SQLake automatically updates the schema and partition information in the AWS Glue Data Catalog so the new dataset is discoverable and accessible.
3. Create a job to parse the arrays into a modeled table
Create a final table that can hold the transformed data, which can be used by data consumers such as analysts and data scientists.
To do this, first you must create the data lake table to hold the transformed data. You’re not defining the full schema here – only those columns you intended to use as primary and partition keys. Furthermore, you are defining the order_id as the primary key to ensure that no duplicates are added into the final output table. If the order_id of a new row matches that of an existing one, the row is updated; otherwise it is inserted as a new row in the table.
CREATE TABLE default_glue_catalog.database_2777eb.arrays_with_orders( order_id string, partition_date date ) PRIMARY KEY order_id PARTITIONED BY partition_date;
Once the table has been created, you need to create a transformation job to parse the orders array, model it, and load it into the target table. Let’s create a job that does that:
CREATE SYNC JOB transform_orders_using_array_functions
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
AS INSERT INTO default_glue_catalog.database_2777eb.arrays_with_orders
MAP_COLUMNS_BY_NAME
SELECT
orderid AS order_id, -- Primary key
orderdate AS order_date,
custom_nettotal AS net_total,
total_items_on_order AS total_items_in_order,
recent_item_ordered_using_element_at AS recent_order,
all_category AS all_item_category,
max_item_revenue AS max_item_revenue,
$event_date AS partition_date -- Partition Key
FROM default_glue_catalog.db.stg_orders_raw_data
LET
data.items[].fix_discount_rate = CASE
WHEN data.items[].discountrate IS NULL THEN 1
ELSE 1 - data.items[].discountrate END,
data.items[].item_revenue = data.items[].unitprice *
data.items[].quantity *
data.items[].fix_discount_rate,
-- sums non-null elements in a array
custom_nettotal = ARRAY_SUM(data.items[].item_revenue),
total_items_in_order = ARRAY_SUM(
COUNT_VALUES(data.items[].itemid) * data.items[].quantity),
recent_item_ordered_using_element_at = ELEMENT_AT(data.items[].name, -1),
-- join array elements separated by comma
all_category = ARRAY_JOIN(data.items[].category,' , '),
-- returns the maximum value in a array
max_item_revenue = ARRAY_MAX(data.items[].item_revenue)
WHERE
$event_time BETWEEN run_start_time() AND run_end_time();
There is a lot going on in the above query, so let’s review it step by step.
Job creation – we create the job and define a few job properties. These properties tell the job how frequently to run and how far back to read data.
SELECT query – the first part of the SELECT query lists the columns to project and renames these columns to more user-friendly names.
LET keyword – SQLake uses the LET keyword to define computed fields. This is powerful because it gives you the ability to manipulate row data easily using pre-built functions, to reference other columns, and more.
There are several computed fields separated by commas.
The first statement uses a CASE/WHEN to fill in the discountrate field if it’s NULL in the original data. We use the array notation [] to check if each array element has a NULL discountrate, if it does, we insert a 1; otherwise we take the inverse and then insert it into a new field fix_discount_rate that is added into the array. Typically, reading array elements and their subfields (if the array element is a struct) requires unnesting and extracting it using JSON parsing functions. Additionally, adding new values to nested structs is very complex. But SQLake makes it very simple, as demonstrated in this example.
The second statement adds a new computed field item_revenue to the orders array by multiplying the order’s unitprice, quantity, and fix_discount_rate.
The third statement adds a top level computed column that uses the ARRAY_SUM function to add up all the item_revenue fields for each order and store the results in custom_nettotal. Note that the ARRAY_SUM is operating on the item_revenue field that was added in the previous statement. If you were to insert this statement into the top level SELECT statement, you would not be able to operate on another computed field because the query parser will not be aware of it. This is one of the reasons why using the LET statement in SQLake is very powerful.
The fourth statement uses COUNT_VALUES to count the number of items in the order and multiply each of them by their item quantity. Then it uses ARRAY_SUM to get the total items purchased.
The fifth statement gets the most recently-added item to the order using the ELEMENT_AT function, passing it -1 which accesses the array from the end.
The sixth statement concatenates the category of each item in the order using the ARRAY_JOIN function, separating them with a comma.
The seventh and last statement adds a computed field using ARRAY_MAX to extract the most profitable item in the order.
You can dive deeper into each of these functions and explore additional functions by visiting the SQLake documentation for Array Functions.
5. Query the results
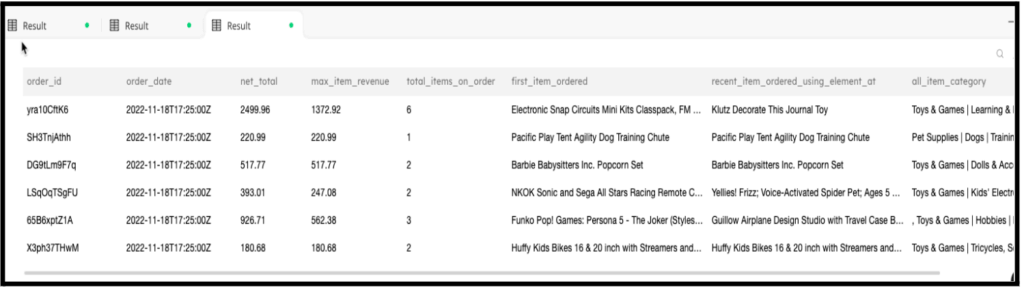
The previous step did all the heavy lifting of parsing the JSON objects inside the array of orders. It created new nested fields and top level columns, renamed other columns, and produced a user-friendly table that your analysts and data scientists can understand. You can easily query this table directly from the SQLake interface or use your favorite data lake query engine, such as Amazon Athena.
SELECT
order_id,
order_date,
net_total,
max_item_revenue,
total_items_in_order,
recent_order,
all_item_category
FROM default_glue_catalog.database_2777eb.arrays_with_orders
LIMIT 10;
The following is a screenshot of the query output.
Summary
Arrays in nested data are very common. Using them makes your data more compact and easier to co-locate related information. This reduces the number of joins required when querying the data in a normalized data model. However, parsing, manipulating, and using array elements is difficult with SQL and requires complex JSON parsing functions to get right. SQLake makes it easy to parse and use arrays so you don’t need to learn new syntax or special tricks to access your data.
Get started today for free with sample data or bring your own.
Discover how companies like yours use Upsolver
Data preparation for Amazon Athena.
Browsi replaced Spark, Lambda, and EMR with Upsolver’s self-service data integration.
Read case studyBuilding a multi-purpose data lake.
ironSource operationalizes petabyte-scale streaming data.
Read case studyDatabase replication and CDC.
Peer39 chose Upsolver over Databricks to migrate from Netezza to the Cloud.
Read case studyReal-time machine learning.
Bigabid chose Upsolver Lookup Tables over Redis and DynamoDB for low-latency data serving.
Read case study
Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products