Explore our expert-made templates & start with the right one for you.
How to aggregate data using SQLake
Upsolver SQLake includes a wide range of predefined mathematical functions that can be used to transform and manipulate data. In this tutorial we will go through an example using a streaming dataset containing order details. We will incorporate different aggregation functions and calculate the total number of orders placed per hour and the revenue generated.
Run it
- Create a staging table to hold raw data
- Create an ingestion job to copy raw data into the staging table
- Create the target table to hold final, aggregated data
- Create a transformation job to aggregate the data and write to the output table
Let’s walk through the steps.
- Create a staging table to hold raw data
Staging tables are used to store a raw and immutable copy of the data in your Amazon S3 based data lake. When creating the staging table you can omit defining the schema because SQLake will dynamically detect and update the AWS Glue Data Catalog as data is ingested. Furthermore, for the majority of staging tables, a best practice is to partition them table by $event_date, an automatically generated system column which records the timestamp of the incoming event.
CREATE TABLE default_glue_catalog.database_2777eb.orders_raw_data() PARTITIONED BY $event_date;
Note: We are partitioning the table based on a system column called $event_date but you can replace it with any other time/date column so that records are evenly distributed.
- Create an ingestion job to copy raw data into the staging table
The next step is to create an ingestion job which copies the raw events into a staging table. The data is copied continuously, minute by minute, with all table management (partitioning, compaction, cataloging, etc..) handled automatically by SQLake.
CREATE SYNC JOB load_orders_raw_data_from_s3 CONTENT_TYPE = JSON AS COPY FROM S3 upsolver_s3_samples BUCKET = 'upsolver-samples' PREFIX = 'orders/' INTO default_glue_catalog.database_2777eb.orders_raw_data;
The following are important parameters to consider when creating your COPY FROM job:
START_FROM = BEGINNING | NOW | TIMESTAMP ‘<timestamp>’
This parameter specifies how far back to begin reading events from the stream. The full syntax for the COPY FROM job for S3 sources is documented here.
- BEGINNING will read from the earliest event that is stored on the stream.
- NOW will start reading from the time that the job was created.
- TIMESTAMP ‘<timestamp>’ will read from the timestamp referenced.
CONTENT_TYPE = JSON | CSV | PARQUET | AVRO | …
This parameter specifies the type of content to read off of the stream. Certain content types may require additional settings, as documented here.
- Create the target table to hold final, aggregated data
At this point, SQLake is running your ingestion job, processing new data files as they arrive and loading them into your staging table. You can query the staging table by executing a SELECT query in SQLake or a data lake query engine like Amazon Athena.
Next, create an output table to hold the aggregated data that business users will analyze and visualize.
CREATE TABLE default_glue_catalog.database_2777eb.orders_aggregate_daily ( order_date date, order_hr bigint ) PRIMARY KEY order_date,order_hr;
- Create a transformation job to aggregate the data and write to the output table
As we did before, let’s create a job that reads from the staging table, aggregates the data, and writes the results to the output table. In this example, we will roll up sales records to a daily aggregation.
CREATE SYNC JOB Aggregate_orders_and_insert_into_athena START_FROM = BEGINNING ADD_MISSING_COLUMNS = TRUE RUN_INTERVAL = 1 MINUTE AS INSERT INTO default_glue_catalog.database_2777eb.orders_aggregate_daily MAP_COLUMNS_BY_NAME SELECT DATE(EXTRACT_TIMESTAMP(orderdate)) AS order_date, HOUR(EXTRACT_TIMESTAMP(orderdate)) AS order_hr, COUNT(orderid) AS total_orders, ROUND(SUM(ARRAY_SUM(data.items[].unitprice)),2) AS total_sales FROM default_glue_catalog.database_2777eb.orders_raw_data WHERE ordertype = 'SHIPPING' AND $event_time BETWEEN run_start_time() AND run_end_time() GROUP BY DATE(EXTRACT_TIMESTAMP(orderdate)), HOUR(EXTRACT_TIMESTAMP(orderdate));
Executing the above query will begin continuous data processing. Note, at startup it will take 2-3 minutes for data to be ready to query in the target table.
In the above example, we used several time and date functions to parse timestamp fields and extract relevant date parts like the full date and the hour. We also performed a few aggregations and grouped the results by order date and hour. In batch systems, users have to execute a similar query every time they need to update the aggregated view in their dashboard. By moving this query to SQLake, the output table is automatically updated as new data arrives.
Query the target table
To inspect the results of your transformation job, you can execute the following query in SQLake. Since this table is available in your data lake, any data lake compatible query engine like Amazon Athena, Amazon Redshift Spectrum or Databricks SQL can query it with ease.
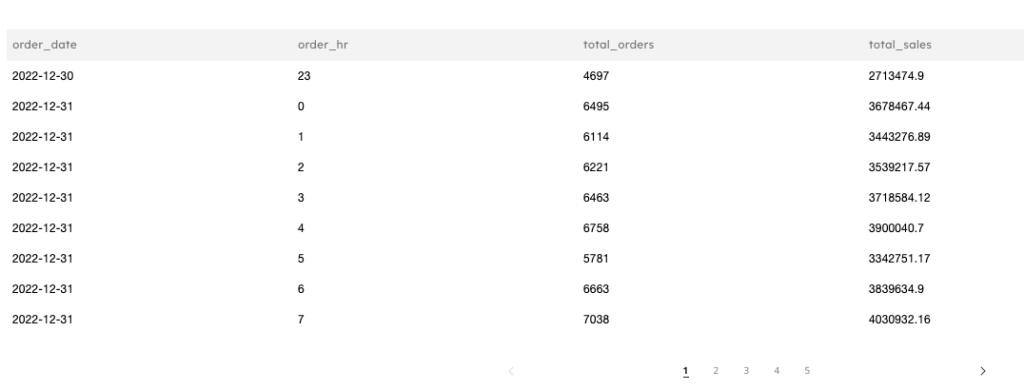
SELECT order_date, order_hr, total_orders, total_sales FROM default_glue_catalog.database_2777eb.orders_aggregate_daily LIMIT 10;
Here is a sample of the results:
Summary
That’s it!!
In just a few minutes and with a dozen lines of SQL you were able to ingest data from S3 into the data lake, perform several transformations on date fields, and provide a table suitable for analytics, reporting and additional downstream transformations.
Try SQLake for free with pre-built templates using sample data.
Discover how companies like yours use Upsolver
Data preparation for Amazon Athena.
Browsi replaced Spark, Lambda, and EMR with Upsolver’s self-service data integration.
Read case studyBuilding a multi-purpose data lake.
ironSource operationalizes petabyte-scale streaming data.
Read case studyDatabase replication and CDC.
Peer39 chose Upsolver over Databricks to migrate from Netezza to the Cloud.
Read case studyReal-time machine learning.
Bigabid chose Upsolver Lookup Tables over Redis and DynamoDB for low-latency data serving.
Read case study
Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products