
Explore our expert-made templates & start with the right one for you.
Build a Real-Time Streaming ETL Pipeline in 5 Steps
-
 Shawn Gordon
Shawn Gordon
- Use Cases
- March 11, 2022
The following article offers a practical guide to build real-time ETL pipelines. Learn more about this topic by downloading our streaming architecture white paper (free, pdf).
Stream processing must become a core competence for any data engineering team that wants to keep up with current tech. Real-time data is seeing tremendous growth as new data sources such as IoT devices, real-time applications, and mobile devices become more integrated into business operations.
From an engineering perspective, the nature of real-time data requires a paradigm shift in how you build and maintain ETL data pipelines. Streaming data is continuously generated – and while the inflow of data can be fairly predictable, the structure of the data may change in the same frequency.
In this article, we’ll cover the requirements for designing and managing a real-time streaming ETL pipeline that ingests streaming data, stores it in cloud object storage, and outputs an analytics-reedy dataset for query engines.
Streaming vs Batch Pipelines: Why You Need Streaming ETL and Why It’s Challenging
To make data useful outside of the source systems in which it is generated – such as business apps, mobile devices, or spreadsheets – you will almost always need to run some kind of ETL pipeline. Data must be extracted, normalized, joined with additional sources, cleaned, and optimized before being made available for querying in target systems – and this is true for any type of workload or data source. However, there are differences between batch and streaming ETL.
Streaming ETL is a data integration approach that involves moving data in real-time, as it is generated, from multiple sources into a target system. This is different from batch processing, where data is moved in periodic batches. A streaming ETL pipeline is typically used when data freshness is crucial, and when data is generated continuously in small bursts
Batch processing is typically used when moving data between departmental data marts (such as CRM, finance, and HR systems) to an enterprise data warehouse. A delay of a few hours or even a few days is usually acceptable in these cases.
In a batch process, we’re waiting for large volumes of data to accumulate before running a transformation or moving data into the target system. The challenge is often to do so at scale and without degrading the performance of operational databases.
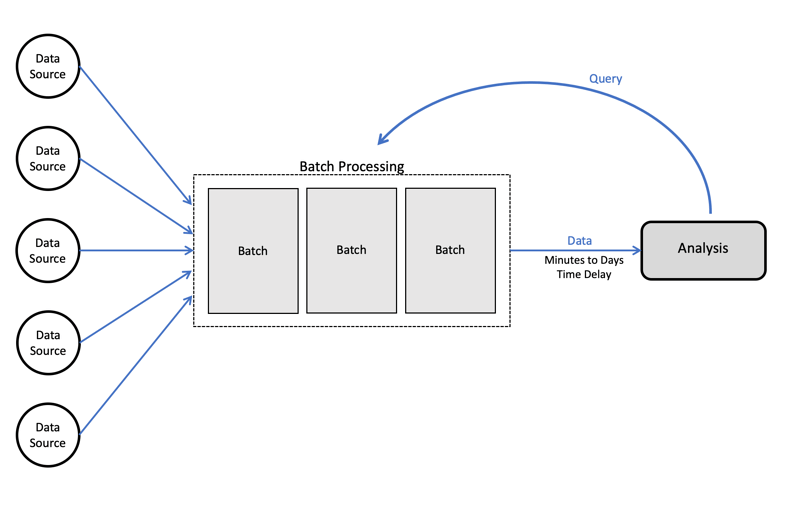
Steaming ETL is used when data freshness is of paramount importance, and when data is generated continuously in very small bursts. The data can originate from the Internet of Things (IoT), transactions, cloud applications, web interactions, mobile devices, or machine sensors.
For example, if we’re trying to analyze user behavior on a website or a mobile app, that data is going to take the form of thousands of events associated with thousands of users – easily adding up to millions of new records each hour. If organizations need to respond to changes in the data as they happen – such as to detect app outages or to offer promotions in real time – stream processing is really the only viable solution.
Benefits of stream processing
- Data freshness – since events are processed close to the time they are generated, you avoid the delays involved with batch processing and can make data available for analysis faster.
- Cost – events are processed one at a time, removing the need to run large operations on small servers. This helps keep your compute costs under control.
However, stream processing is not without challenges:
- Since you need to process data in motion, you do not have the ability to load it into a data warehouse and use familiar SQL tools to perform your transformation.
- Data schema and structure often changes, which can potentially break your pipeline or result in it returning the wrong data
- Missing and late events (such as due to poor internet connectivity on end devices) can create inconsistencies in the target dataset
You can read more about stream, batch and micro-batch processing here.
How We Define a Streaming Data Pipeline
Stream processing typically entails several tasks on the incoming series of data, such as transformations, filters, aggregations, enrichment, or ingestion of the data, before publishing the processed messages.
A streaming data pipeline flows a constant feed of data from one point to another as the data is created. It can be used to populate data lakes or data warehouses, or to publish to a messaging system or data stream. They are used for fast data that needs to be captured in real time, and when capturing large volumes of raw data is essential.
A well-architected streaming architecture can handle millions of events at scale and in real-time. This allows data engineers to compile, analyze, and store vast amounts of information. Data can then be used for applications, analytics, and synchronous reporting.
Streaming Data Pipeline Architecture
A streaming pipeline starts with a raw event stream and ends with an analytics-ready table that data analysts can query with SQL. If you want to explore this topic in-depth, you can read our guide to real-time architecture; but schematically, your pipeline might look something like this:
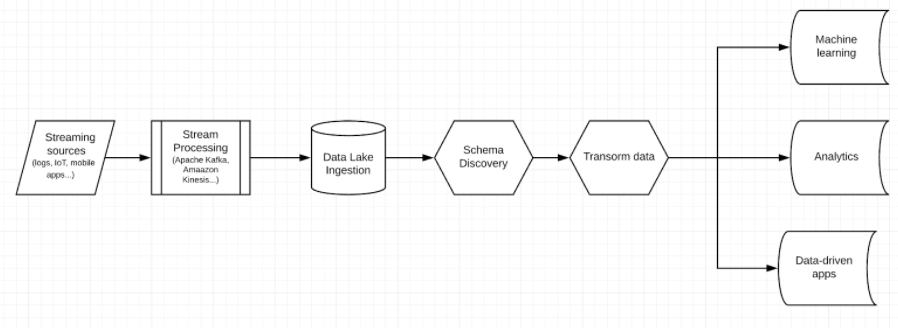
First you need to stream your real-time data into a streaming platform – a message broker that processes streaming events from client apps or devices and ensures it is sent to target storage systems.
Apache Kafka is an extremely popular message bus used in many software development environments. Amazon’s Kinesis Data Streams is also common in AWS deployments. To learn more about different streaming tools, see our comparisons of Kafka vs RabbitMQ or between Kafka and Kinesis.
Real-time Data Ingestion
Real-time data ingestion is the process of writing data collected by a message bus into a storage layer.
Like other data pipelines, a streaming pipeline delivers data from source to target; but unlike a batch system which would typically be triggered on a periodic basis, or once a certain amount of data has accumulated, a streaming pipeline runs continuously and delivers events as they are generated, in real or near-real time.
Often the source systems, such as IoT sensors, would not store the data for long, while storing it in a message bus such as Kafka or Kinesis is costly. This necessitates moving the data quickly into storage.
Storage
Once you have a stream of incoming events, you need to store it somewhere. One option would be to use a traditional database. However, choosing that option limits your flexibility (since you have to commit to a certain schema) and the storage costs would be high. There are also databases built specifically for streaming, but they have limitations as well – as we’ve covered in our previous article, 4 Challenges of Using Database for Streaming Data.
The other option would be storing your data in a data lake. Data lakes are based on object storage services such as Amazon S3 and Google Cloud Storage. These are cheap and reliable options to store data in the cloud. This is the best choice for handling high volumes of streaming data, since object storage fits in nicely with this type of fluid and often only partially-structured data.
Amazon S3 is schema-agnostic. It doesn’t care about data formats and structure – you can just store whatever data you want and it deals with it perfectly and at a low cost. It’s important to store the data in the lake in an optimal manner. For example: avoid small files and use the best optimal format for your use case (read more about dealing with small files on S3).
Schema Discovery
While S3 is an excellent and low-cost option for storage, it doesn’t give you tools to manage schema, which means you’re not always sure exactly what’s going into your lake. Maintaining a schema layer on top of your data lake helps you maintain control and avoid “data swamp” scenarios. The solution for that is either to develop a schema management tool yourself or use existing such as Upsolver to do it, which provides automatic schema-on-read.
More about using schema discovery to explore streaming data.
Data Preparation for Analytics
So you have your data ingested into a data lake, and you know how it’s structured. Nice work! However, this is probably not the end of the task; you probably want to do something with your data, such as running analytics queries, running machine learning flows, or even just storing a subset of the data in a database.
Here comes the transformation phase in the ETL process. As with every ETL, moving your data into a queryable state is a concern for the real-time use case as well.
As we’ve previously seen, streaming data comes in several forms (such as hierarchical JSON) and shapes (such as various file formats: CSV, TSC, Parquet, AVRO, and so on). And a single stream of real-time data may change over time, as well. Since we are dealing with real-time data such changes might be frequent and could easily break your ETL pipeline. So for transforming your data you need either to use a data pipeline tool such as Upsolver or code your own solution using Apache Spark, for example.
When you’re done moving your data into a queryable state, you need to distribute it to one or more targets, depending on your use case. This can be done using tools such as Apache Airflow, which requires some expertise and coding, or you can develop your own orchestration tool by yourself using Spark.
Building Real-time ETL Pipelines in Upsolver
Let’s look at an example use case in which you build a pipeline that reads from a Kinesis stream and write transformed results to an Athena table. Broadly, you do the following 5 steps:
Start building your pipeline with a connection to a data source. Then ingest that data using a copy process into a staging zone, effectively staging that raw data in a managed S3 bucket. Next transform the data, using only SQL. Lastly, create an output table and write the transformed data into the output table, which you can query using Upsolver’s built-in Amazon Athena integration. (You can also use Athena to inspect staged data while your job is in progress.)
The SQL code below is excerpted from the Kinesis-to-Athena worksheet template, which is just one of many worksheet templates available in Upsolver to help you immediately get started building always-on, self-orchestrating data pipelines.
Try Upsolver. No credit card required.
Step 1: Create the connection to Kinesis.
This serves as the source of your data.
CREATE KINESIS CONNECTION <KINESIS_CONNECTION_NAME>
AWS_ROLE = 'arn:aws:iam::<YOUR_ACCOUNT_ID>:role/<YOUR_ROLE>'
EXTERNAL_ID = '12345678'
REGION = 'us-east-1';
/* If you don't have an appropriate role, you may use the access key and secret key directly (not recommended). */
--AWS_ACCESS_KEY_ID = '<your aws access key>'
--AWS_SECRET_ACCESS_KEY = '<your aws secret key>'
/* STREAM_DISPLAY_FILTERS can be used to display specific streams or folders. If not provided, all streams will be shown. */
--STREAM_DISPLAY_FILTERS = ('stream1', 'stream2');
--COMMENT = 'My new Kinesis connection';
Step 2: Create a staging table to store your raw data from Kinesis.
This is just to establish an empty table. Upsolver creates this table inside of a default Glue data catalog that Upsolver provides.
CREATE TABLE default_glue_catalog.<DB_NAME>.<STAGING_TABLE_NAME>()
PARTITIONED BY $event_date;
-- TABLE_DATA_RETENTION = 30 days
-- COMMENT = 'My new staging table'
Note that we haven’t defined any schema here, because Upsolver creates the schema as it writes data into the table. We’ve defined only the partition method – in this case, the date the event streams in. You can define some of the target schema as needed, but you don’t have to define it fully; Upsolver dynamically modifies the schema as data is transformed.
Now load the source data into this staging table so you can subsequently work off of it within your pipeline.
Step 3: Create a job to ingest raw streaming data from your Kinesis stream to the staging table.
Essentially you’re copying raw data from the source and writing it into the staging table. We’ve used JSON for the template data type, but Upsolver natively supports dozens of content types – .csv, .xml, Avro, Parquet, and so on. If you’re uncertain what your content type is, set CONTENT TYPE = AUTO. Upsolver determines the content type and acts accordingly.
CREATE JOB <KINESIS_STAGING_JOB>
START_FROM = BEGINNING
CONTENT_TYPE = JSON
AS COPY FROM KINESIS <KINESIS_CONNECTION_NAME> STREAM = '<KINESIS_STREAM_NAME>'
/* COPY into the table you created in step #2 */
INTO default_glue_catalog.<DB_NAME>.<STAGING_TABLE_NAME>;
As this job runs and data is extracted, Upsolver automatically performs a wide range of “under the hood” activities that substantially enhance transformations further downstream:
- Creates Glue Catalog entries for the ingested data
- Partitions the data (in this case, by date)
- Compresses the data for efficient storage
- Converts the event files into Apache Parquet and merges small files for optimal query performance.
- Identifies the schema, the fields, the data types, the density, the distribution, and some predefined aggregates.
At this point you can take the opportunity to verify that the raw data in the table staged from your Kinesis stream is what you’re expecting. Upsolver makes this easy with a built-in Athena interface:
SELECT * FROM default_glue_catalog.<DB_NAME>.<STAGING_TABLE_NAME> limit 10;
Step 4: Create an output table in AWS Glue Data Catalog.
Now create the output table into which you’ll write your transformed data. This is the same process you used to create the staging table in Step 2, except that you’re also defining a key column. In this case, partitiondate is the key. (In an earlier step you defined partitiondate as a partition column of type date.) This column doesn’t yet exist in the source table; Upsolver creates it in the next step.
CREATE TABLE default_glue_catalog.<DB_NAME>.<TRANSFORMED_TABLE_NAME> (
partition_date date)
PARTITIONED BY partition_date;
Step 5: Create a job to stream transformed data to the Athena table you created in the previous step.
The table becomes available in Athena as soon as you begin adding data. You must have data in your staging table before you create this job.
CREATE JOB <ATHENA_LOAD_JOB>
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
AS INSERT INTO default_glue_catalog.<DB_NAME>.<TRANSFORMED_TABLE_NAME> MAP_COLUMNS_BY_NAME
SELECT
<source_column_name> as <target_column_name>,
MD5(<source_column_name>) as <target_column_name>,
<new_variable> as <target_column_name>,
<source_column_name> as <target_column_name>,
$commit_time AS partition_date
FROM default_glue_catalog.<DB_NAME>.<STAGING_TABLE_NAME>
WHERE <column_name> = '<filter_by_value>'
AND $commit_time BETWEEN run_start_time() AND run_end_time();
A few highlights:
- Some columns are aliased.
- One column is masked using a built-in MD5 function (this is a very common technique to use with PII).
- The commit time tells the transformation job what data to actually transform – in this case, from minute to minute.
Your pipeline is now running, bringing data from the source Kinesis stream into a staging table, transforming it, and saving it to an output table in Athena. If you now scroll down in your Upsolver worksheet, you see the Athena query that you can run to examine the data that has been transformed and pushed out to that output table. It should closely resemble what was displayed in your preview.
With that – you’re done. You’ve just built a continuous ETL pipeline that ingests, transforms, and delivers structured data for analytics. You can easily duplicate or modify this template to fit your distinct needs and keep up with changes.There’s much more to Upsolver. For more details and insight, please review the Upsolver Builders Hub, with articles on a range of use cases and techniques, or consult the Upsolver documentation.
Putting It All Together: Learn How ironSource Runs Petabyte-Scale Data Pipelines
If any company in the world knows streaming data, it’s ironSource. The mobile monetization leader works with massive volumes of data from its various networks, and that data grows and changes every day.
In the following 10 minute video, you can hear from the VP of R&D at ironSource on why he chose to move his streaming architecture from a data warehouse to a data lake.
If you want to further explore this case study and hear additional details from AWS and Upsolver about how the solution was implemented, watch the webinar recording here.
What to read next:
- Data Pipeline Architecture: Building Blocks, Diagrams, and Patterns
- Benchmark Report: Data Processing for a Near Real-Time Data Warehouse
- Upsolver Builders Hub – learn more about how Upsolver works, read technical blogs that delve into details and techniques, and access additional resources.
- If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
