
Explore our expert-made templates & start with the right one for you.
Apache Spark Limitations & the Self-service Alternative
-
 Eran Levy
Eran Levy
- Cloud Architecture
- January 23, 2020
Apache Spark has become the de-facto standard for big data processing, and many organizations see it as the default go-to solution for large-scale ETL and analytics. But is Spark always the best choice? The reality is a bit more nuanced.
While Spark is a robust and powerful open-source framework, it is not without limitations when it comes to ease of use, cost of ownership and time to production. Spark, like Hadoop, is a complex framework that requires a lot of specialized knowledge – a major diversion from the managed, self-service software tools that data teams have grown accustomed to using. Let’s take a closer look at some of these challenges of implementing Spark, and how Upsolver can be used to sidestep them.
Watch Roy Hasson, Sr. Director of Product Management at Upsolver, explain why organizations choose self-service alternatives over Spark in our recent webinar with Proofpoint:
Example Business Scenario: Data Warehouse Migration
To understand the comparison, we’ll look at it through the prism of the following common use case: an organization has been using an enterprise data warehouse to store terabyte-scale relational and streaming data. However, as data volumes grow and the organization finds itself dealing with more streaming sources (such as web application logs and device data), the decision is made to move from the old data warehouse implementation to a data lake on AWS.
At this stage, the DBA team is tasked with migrating the existing infrastructure to the cloud, and rebuilding the ETL pipelines as part of a data lake architecture. They must now decide whether to use an Apache Spark-based solution, such as running Spark on Amazon EMR, or to use productized data lake ETL from Upsolver.
What should this hypothetical organization consider before going all-in on Spark?
Limitations of Apache Spark
1. Spark is built for big data and Scala engineers,not for analytics teams
Building data transformations in Spark requires lengthy coding in Scala with expertise in implementing Hadoop best practices. In our example, the DBAs and data analysts who are currently responsible for building ETL and analytic flows that run on the data warehouse aren’t coders and are used to working primarily with SQL.
While Spark offers some support for Python via PySpark, these user-defined functions tend to be slow and memory-intensive; performant Spark code still needs to be written in Scala. Since Spark does not have a built-in file management system, additional expertise is needed in order to implement dozens of best practices around object storage, partitioning and merging small files.
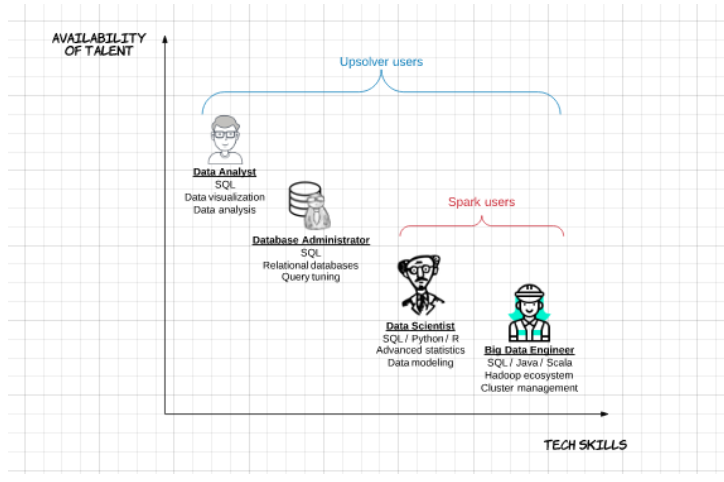
Basically, for our existing data team to implement Spark they would need to learn a whole new skillset; the more realistic possibility is to build an entire new data engineering team with the relevant background in Scala and Hadoop. This increases the costs and delivery schedule of the data warehouse migration project exponentially.
2. Spark is not a stand-alone solution
While Spark is a very robust package and its functionality has been considerably beefed up since its inception in 2009 (check out this article for a good list of current capabilities), it is still only part of a larger big data framework. What could previously be handled entirely within the enterprise data warehouse will now need to be broken up into several building blocks:
- ETL and batch processing with Apache Spark
- Stream processing with Spark Streaming or Apache Flink
- Workflow orchestration with Apache Airflow or Nifi
- State management with a separate NoSQL database such as Apache Cassandra or DynamoDB
Most of these tools require their own specialized skillset, further adding complexity and costs, and making the project more difficult to accomplish for the organization’s existing team and resources.
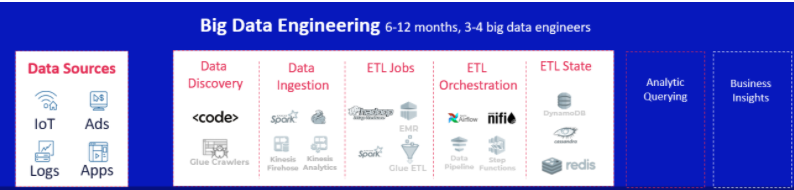
3. Expect a very long time-to-value
As we’ve explained above, a large-scale implementation of Spark is a coding project – and not a simple one to boot. The organization might need to recruit new engineers or hire consultants with the relevant expertise, which takes time; even once the necessary knowledge is available, a lot of custom development and manual tuning will be required for Spark pipeline to remain performant at scale.
The end result is that a Spark-driven project is usually measured in months or even years from inception to production. In our example this means that the organization will need to continue relying on a data warehouse that is struggling to handle the volumes of data being processed – with all the associated costs in performance, time and hardware resources.
4. Disconnect between the people who need the data and the people who can access it
Since Spark requires coding, the inevitable result is that it will be owned by the people who are experts at coding – DevOps and big data engineers. Every new dashboard or report that requires a new ETL flow, or changes to an existing pipeline, will have to run through this silo before going into production. This will be in stark difference to the previous data warehouse implementation, which analysts could query directly using SQL.
This creates a disconnect between data consumers – analysts, feature and BI developers – and the data they need to do their job. When every change request needs to be fit into the Sprint planning of a separate engineering team, the motivation to make any changes drops, and the end result is less access to data across the organization.
5. Higher costs than expected
While Apache Spark itself is open-source and so does not come with any direct licensing costs, the overall cost of a Spark deployment tends to be very high, with the major cost factors being hardware and human resources. In the previous points we’ve talked about the human costs of hiring data engineers, or diverting existing engineering resources – and with engineering salaries at an all-time high, the cost of having 3-4 engineers working solely on infrastructure can easily exceed most software license prices.
In addition to the above, and as Ian Pointer covers in his excellent piece in InfoWorld, Spark is not a memory-efficient tool out of the box, and requires a lot of configuration and trial-and-error to optimize resource utilization. In a cloud data lake, this would manifest in higher EC2 costs which can add up to hundreds of thousands of dollars or more, depending on the scale and how effectively the system is configured.
The alternative: self-service data lake ETL
So let’s say our hypothetical data migration team reaches the conclusion that a Spark-based architecture will be complex, disparate, and costly. Is there an alternative?
The Upsolver Data Lake ETL platform was initially conceived when our developers were struggling to overcome the limitations of Apache Spark, and is built to directly address these limitations by providing a fully-managed, self-service ETL tool for cloud data lakes. Upsolver abstracts the manual processes, complexities and endless gotchas of Spark and replaces them with a visual interface, SQL-based data transformations, and automated cluster management and orchestration.
Let’s look at each of these capabilities and see how they differ from Apache Spark:
SQL and visual UI instead of coding in Scala
While the Upsolver platform itself is written in Scala, you don’t need to know anything but SQL to leverage 100% of its functionality. Upsolver allows you to build ETL flows using an ANSI-SQL syntax with streaming extensions; best practices around partitioning, small files and columnar file storage, which would need to be manually implemented and tuned in Spark, are implicitly automated by the platform itself and require minimal configuration from the user.
In this way, Upsolver enables data pipelines to be built declaratively rather than imperatively.
Using Upsolver, the team of DBAs and data analysts could complete the data migration project independently and using the SQL they already know – replacing the need to devote additional engineers or hire consultants to architect a solution.
Learn more about data transformations in Upsolver:
- Transforming data with Upsolver SQL (product page)
- ETLing data from Kinesis to Athena (blog post)
Single tool for ingestion, transformation and orchestration
We’ve mentioned before that Spark will only be part of the solution – with Upsolver, this is not the case; the platform is built to provide end-to-end ETL capabilities that can power every analytic workflow in a data lake – and since Upsolver is highly optimized for these use cases rather Spark’s jack-of-all-trades nature, performance in Upsolver will typically be 10-15x better than a well-optimized implementation of Spark.
This includes ingesting data from streaming sources, storing it in object storage according to best practices, and running the necessary transformations to query the data in a variety of services (Amazon Athena, Presto, ElasticSearch, Redshift and more); as well as managing clusters, workflow orchestration, integration with popular monitoring tools, and stage management via Lookup Tables.
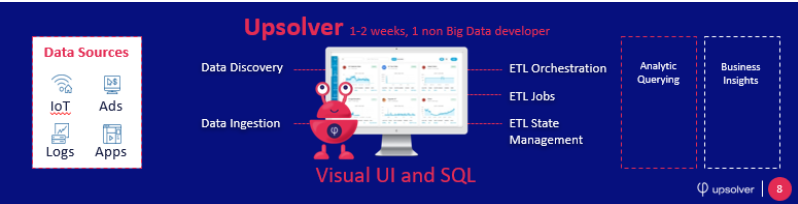
In our example, the data migration team would only need to become familiar with one new software platform, rather than 4-5 arcane open-source frameworks; this process would be further streamlined by Upsolver not requiring any coding besides SQL, as we’ve already mentioned above.
Learn more about Upsolver ETL:
- Product overview
- Upsolver Lookup Tables (product page)
- Upsolver as an alternative to Cassandra (blog)
Very short TTV (days)
Since Upsolver requires very little custom development and is deeply integrated with other tools commonly used in data lake architectures – Apache Kafka, Amazon Kinesis, Glue/Hive metastores and more – implementing Upsolver it typically a matter of days. 99% of the time we are able to have a working proof of concept on customer data in less than two hours. The data warehouse migration project from our example, which might require a lot of pipeline configuration to replicate existing workflows, might take a few weeks.
Learn more about Upsolver time-to-value:
- Bigabid gets a year jumpstart on its machine learning infrastructure (case study)
- Sisense goes from raw data to production-ready tables in weeks (case study)
Data consumers can access the data lake without going through the engineering bottleneck
With the complex coding in Scala out of the picture, Upsolver makes access to data ubiquitous for any user who can write SQL – data analysts, BI developers, DBAs etc. This breaks down the ETL silo we had with Spark and enables the people who need data in order to create reports, train machine learning algorithms, or investigate a security incident, to get the data they need independently and near-instantly.
Learn more about Upsolver for data consumers:
- Frictionless data lake ETL for petabyte-scale data (webinar)
- How a single developer manages Meta Networks’ data lake infrastructure (case study)
Low cost of ownership
While Upsolver has licensing costs, these are more than negated by the savings in human resources as engineers can focus on developing features that add value to the business, rather than pipelines (to quote our customers at ironSource). Further savings are achieved by Upsolver’s efficient use of memory resources and its optimization of the storage layer on S3.
Learn more about Upsolver pricing and cost reduction:
- Request a personalized price quote
- Upsolver on AWS marketplace
- Comparing Athena costs with and without Upsolver (blog)
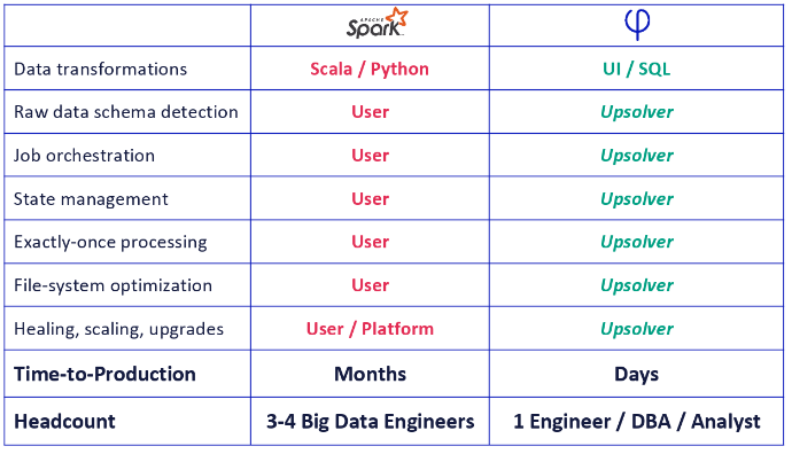
User Journey Comparison
Learn more about Upsolver
Want to see Upsolver in action? Schedule a demo here. Or try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Interested in learning more about Upsolver technology? Grab our technical white paper right here. Need more resources about Apache Spark? Check out our list of alternatives to Spark.
Published in:
Blog
,
Cloud Architecture