Explore our expert-made templates & start with the right one for you.
Data Pipeline
Back to glossaryA data pipeline is a process for moving data between source and target systems. Data pipelines are used to replicate, move, or transform data, or simply to connect two disparate APIs, in order to ensure data is available when, where and in the form that it is needed.
Discover the power of continuous SQL pipelines with Upsolver. Start for free
Types of data pipelines
Data engineering is a rapidly growing field, and much of its focus is on making data available by maintaining a robust data pipeline architecture. Every new data pipeline is its own build vs. buy decision – do you write code to extract and transform data, or do you use a proprietary tool or system?
Open-source frameworks such as Apache Airflow and Spark, among others, offer ways to build and manage transformation pipelines. These tools offer a high degree of flexibility but also require you to write detailed execution plans. They are intricate systems that are difficult to master and thus typically require specialized engineering resources to configure and maintain.
An alternative is to choose a declarative data pipeline tool that allows you to use a common language like SQL to specify the shape of the desired output table and automates much of the engineering required to move the data and execute the transformations. While this approach sacrifices a certain level of control, it requires less time and a lower level of engineering skill to build the pipeline. It enables you to make your data engineering more productive as well as focus data engineering resources on other high-value projects such as developing new features.
Watch this video to learn why Seva Feldman, VP of R&D at ironSource, chose to use Upsolver rather than hand-code the pipeline infrastructure:
What are common examples of data pipelines?
Data pipelines are ubiquitous in analytics and software development, and can be as simple as a drag-and-drop operation or complex enough to require thousands of lines of code. Some archetypal examples include:
Delivering data to data-driven apps: Many modern applications generate value by responding to data in real time. For example, a cybersecurity application might analyze terabytes of network traffic to pinpoint anomalous behavior as it occurs and alert analysts that a breach might have occured. In order to do so, these applications require a stream of fresh, queryable data.
A real-time data pipeline would ingest a stream of logs captured from servers, networks or end devices, transform it into analytics-ready formats, and make it available for the app to query.
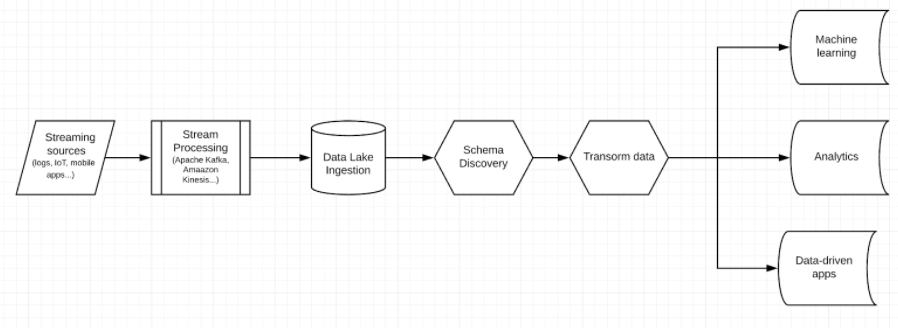
Improving performance and reducing costs of analytics architectures: The abundance of digital systems and applications make it easier than ever for organizations to accumulate large volumes of data. While much of this data might prove useful, storing it in a cloud database can prove prohibitively expensive. For example, a company that analyzes user behavior on its mobile apps might run into drastically higher storage and compute costs if a new feature drives increased app installations or more complex usage patterns.
Data lake pipelines can be used to reduce data warehouse costs as well as improve query performance by transforming raw data on a data lake into smaller analytics-ready tables that can be outputted to the data warehouse. In general, the data lake will provide much less expensive processing.
Centralizing data from disparate business systems: Nowadays, even smaller companies typically work with multiple data-generating applications. For example, a marketing department at a 100-person company might have web analytics, CRM, advertising and product log data. Data pipelines extract the data from each application and load it into a centralized repository such as a data warehouse, where it can be joined for further analysis and reporting.
This type of use case is becoming commoditized, with dozens of data integration and business intelligence tools offering solutions for common scenarios where data from several third-party sources needs to be joined.
Check our data pipeline examples for detailed, step-by-step tutorials covering real-life use cases.
ETL vs ELT data pipelines
The analytics and data management landscape has become more sophisticated over the years, and offers many different ways to work with data. The question of ETL vs ELT boils down to where you are running the transformation workload.
ETL stands for extract, transform, and load. Meaning, the transformation is happening after the data has been extracted from the source system but before it is loaded into the target system. In this case, the transformation would be handled within the data pipeline platform itself, typically by relying on an in-memory engine to aggregate, join and manipulate data.
In an ELT pipeline, the order has changed: extract, load and transform. In this case the data is loaded into the target system – typically a powerful modern database – and then transformed with the database’s compute power. Data pipeline tools can be used to ensure schema consistency and to allow developers to manage the flow of data with minimal coding.
Both ELT and ETL patterns can be found in modern data architecture. Read more about ETL pipelines for data lakes.
What are the challenges of building data pipelines?
The main challenge with data pipelines is ensuring your pipeline performs consistently at larger scales and dealing with changes to underlying data sources and requirements of data consumers. It’s simple enough to write code to move a daily batch of data from an application to a database – but what happens when you want to add additional fields, a new data source, or reduce refresh time from a day to an hour? What about changes to business rules or application logic that requires you to rerun your pipelines?
The need to constantly manage, update and troubleshoot pipelines leads to data engineers becoming overwhelmed with ‘data plumbing’ – constantly chasing the latest bug, recovering from a pipeline crash, or addressing dropped data. This can be especially painful and time-consuming when working in a data lake architecture, when dealing with schema evolution, or when working with real-time data streams.
You can learn more about data pipeline challenges and how to overcome them in this recorded talk by Upsolver CEO:
(If you prefer words to moving pictures, check out this blog instead)
What is a streaming data pipeline? How does it differ from batch?
A streaming data pipeline continuously processes data as it is being generated, allowing for real time or near-real time access to data from streaming sources such as sensors, mobile devices, and web applications. While batch processing is based on waiting for a certain amount of data to accumulate before running a workload (e.g., every hour or every day), in a streaming pipeline data is moved as it is generated at the source in order to increase availability and freshness.
Even though much of modern data is generated by streaming sources, it still poses many unique challenges for data engineers. We’ve covered most of these in our guide to streaming data architecture; you might also want to check out our previous article on stream, batch and micro-batch processing.
To learn more about data pipelines:
- Check out our ebook: Data Integration for Cloud Data Lakes
- See how Upsolver customers are building continuous SQL pipelines
- Build your own pipelines for free with the Upsolver SQLake
