
Explore our expert-made templates & start with the right one for you.
Data Pipeline Architecture: Building Blocks, Diagrams, and Patterns
-
 Eran Levy
Eran Levy
- Data Lakes
- February 1, 2022
Companies are constantly looking for ways to extract value from modern data such as clickstreams, logs, and IoT telemetry. This free O’Reilly report explains how to use declarative pipelines to unlock the potential of complex and streaming data, including common approaches to modern data pipelines, PipelineOps, and data management systems. Download the PDF.
Well-architected data infrastructure is key to driving value from data. As data grows larger and more complex, many organizations are saddled with the complexity and cost of independently managing hundreds of data pipelines in order to ensure data is consistent, reliable, and analytics-ready. Is there a better way?
In this article, we’ll cover some of the key concepts and challenges in big data pipeline architecture, examine common design patterns, and discuss the pros and cons of each. To make things clearer, we’ve also tried to include diagrams along each step of the way.
If you want to build reliable data pipelines faster, consider Upsolver SQLake, our all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for batch and streaming data . It automates everything else, including orchestration, file system optimization and infrastructure management. You can execute sample pipeline templates, or start building your own, in Upsolver SQLake for free.
What is a Data Pipeline Architecture?
If a data pipeline is a process for moving data between source and target systems (see What is a Data Pipeline), the pipeline architecture is the broader system of pipelines that connect disparate data sources, storage layers, data processing systems, analytics tools, and applications.
In different contexts, the term might refer to:
- The logical architecture that outlines the process and transformations a dataset undergoes, from collection to serving (see data architecture components).
- The specific set of tools and frameworks used in a particular scenario, and the role each of these performs.
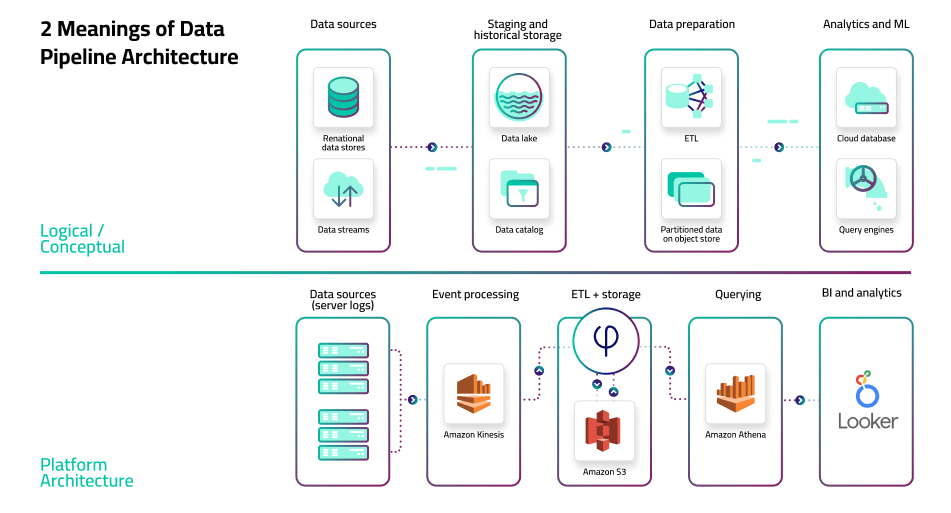
In this article, we’ll go back and forth between the two definitions, mostly sticking to the logical design principles, but also offering our take on specific tools or frameworks where applicable.
Why Does Pipeline Architecture Matter? An Example
Business appetite for data and analytics is ever-increasing. The need to support a broad range of exploratory and operational data analyses requires a robust infrastructure to provide the right data to the right stakeholder or system, in the right format.
Even a small company might develop a complex set of analytics requirements. Let’s take the example of a company that develops a handful of mobile applications, and collects in-app event data in the process. Multiple people in the organization will want to work with that data in different ways:
- Data scientists want to build models that predict user behavior and to test their hypotheses on various historical states of the data
- Developers want to investigate application logs to identify downtime and improve performance
- Business executives want visibility into revenue-driving metrics such as installs and in-app purchases
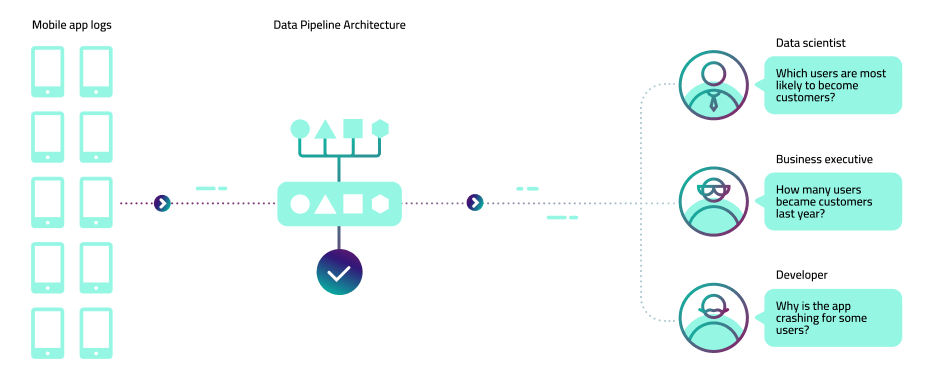
This is where the data pipeline architecture comes into play, ensuring all the relevant events are collected, stored, and made available for analysis in a way that is manageable and cost-effective, especially as the scale and number of pipelines increase. Let’s look at what that typical process is composed of, step by step:
Components and Building Blocks
Data infrastructure addresses the full scope of data processing and delivering data from the system that generates it to the user who needs it, while performing transformations and cleansing along the way. This includes:
- Collection: Source data is generated from remote devices, applications, or business systems, and made available via API. Apache Kafka and other message bus systems can be used to capture event data and ensure they arrive at their next destination, ideally without dropped or duplicated data.
- Ingestion: Collected data is moved to a storage layer where it can be further prepared for analysis. The storage layer might be a relational database like MySQL or unstructured object storage in a cloud data lake such as AWS S3. At this stage, data might also be cataloged and profiled to provide visibility into schema, statistics such as cardinality and missing values, and lineage describing how the data has changed over time. Read more about ingestion pipelines.
- Preparation: Data is aggregated, cleansed, and manipulated in order to normalize it to company standards and make it available for further analysis. This could also include converting file formats, compressing and partitioning data. This is the point at which data from multiple sources may be blended to provide only the most useful data to data consumers, so that queries return promptly and are inexpensive.
- Consumption: Prepared data is moved to production systems – analytics and visualization tools, operational data stores, decision engines, or user-facing applications.
To see how all of these components come into play, see this reference architecture take from our latest case study: How Clearly Drives Real-Time Insights.
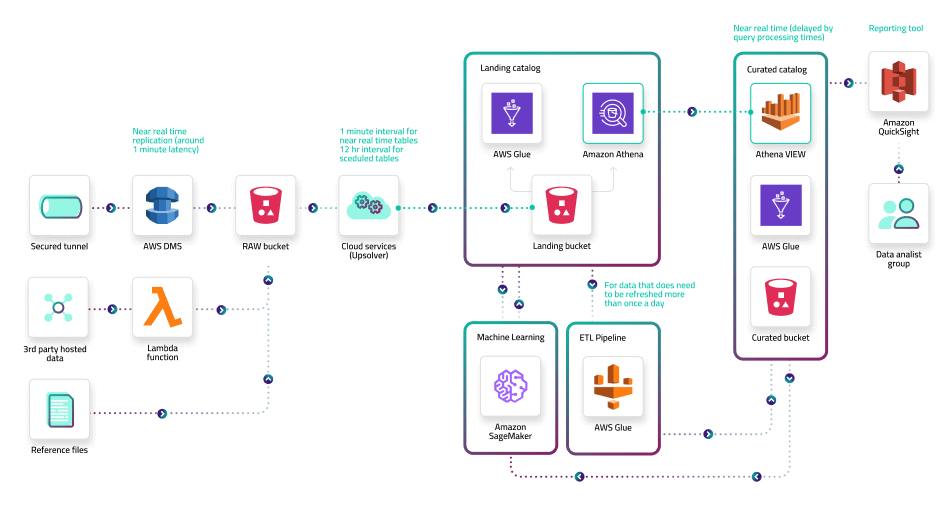
Note that multiple steps might be handled by the same tooling or code and tools may not line exactly to the four stages. For instance, preparation may occur upon ingestion (basic transformations), preparation (intensive operations like joins), and consumption (a BI tool may perform an aggregation).
Common Architecture Patterns for Data Pipelining
The number of ways to design a data architecture is endless, as are the choices that can be made along the way – from hand-coding data extraction and transformation flows, through using popular open-source frameworks, to working with specialized data pipeline platforms.
Despite this variance in details, we can identify repeating design principles and themes across data architectures:
1. ETL pipelines centered on an enterprise data warehouse (EDW)
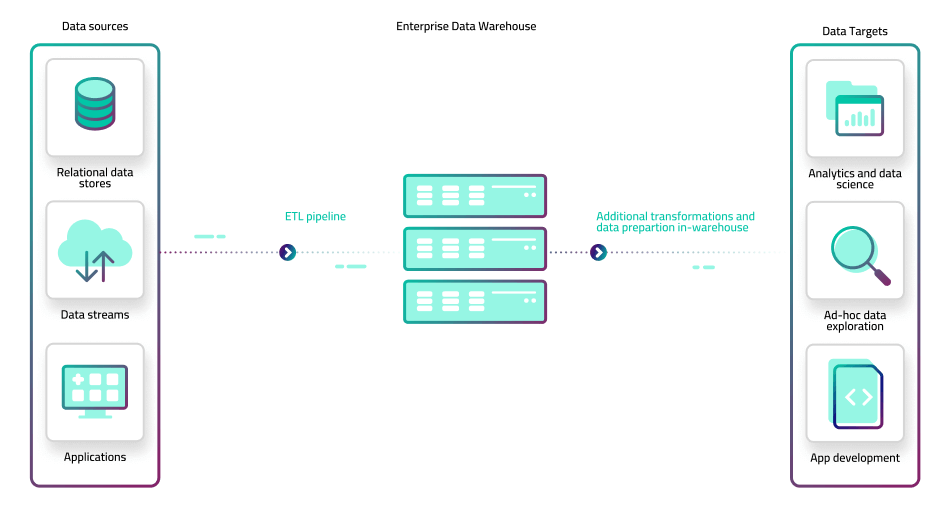
This is the traditional or ‘legacy’ way of dealing with large volumes of data. The organization rallies around a single, monolithic data warehouse, perhaps supplemented with some smaller, domain-specific data marts. Central IT and data engineering teams are responsible for building the pipelines to move data from source systems and ingest it into the warehouse in a consistent schema, as well as joining disparate datasets to enable deeper analytics.
Additional IT teams would work with analysts that query the data warehouse using SQL. Analytical or operational consumption needs to be supported while ensuring data remains available and preventing disruption to production environments. Each new use case or change to an existing use case requires changes to the data pipeline, which would need to be validated and regression tested before being moved to production.
The main advantage of this architecture is that data is highly consistent and reliable, and the organization is truly working off of a single source of truth (as there is literally a single source). However, it is a very brittle architecture that creates significant technical debt at every step of the process. ,IT bottlenecks invariably form because every change to a report or query requires a laborious process managed by the same overloaded teams.
Another drawback is that data warehouses are built for structured, batch-oriented data and much of the world is moving to streaming and complex (semi-structured) data.
2. Centralized data lake pipelines and big data platform (lake house)
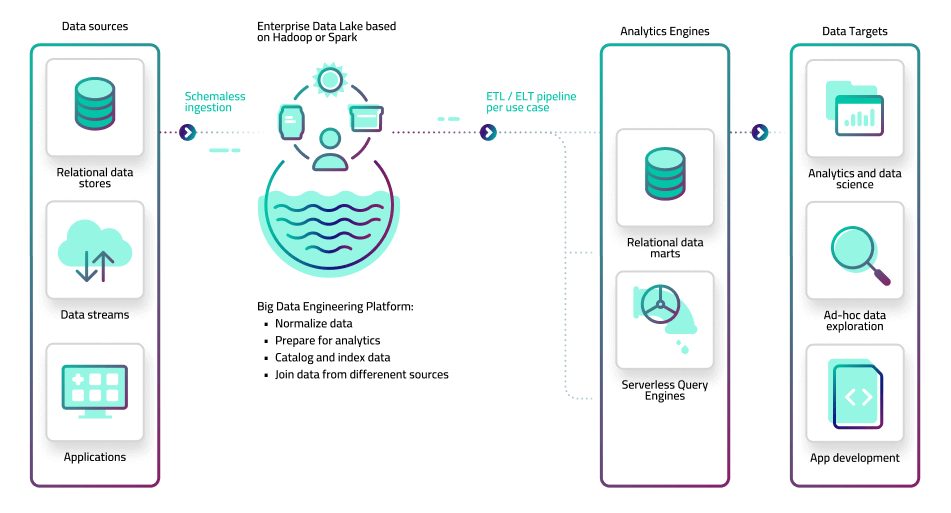
In this architecture, the monolithic data warehouse has been replaced with a data lake. Large volumes of data from different sources can now be easily ingested and stored in an object store such as Amazon S3 or on-premise Hadoop clusters, reducing the engineering overhead associated with data warehousing. The data lake stores data in its original, raw format, which means it can store complex and streaming data as easily as structured, batch files.
However, raw data in the lake is not in a queryable format, which necessitates an additional preparation layer that converts files to tabular data. The big data platform – typically built in-house using open source frameworks such as Apache Spark and Hadoop – consists of data lake pipelines that extract the data from object storage, run transformation code, and serve it onwards to analytics systems. These can be physical databases such as RDS, data warehouses such as Redshift or Snowflake, single-purpose systems such as Elasticsearch, or serverless query engines such as Amazon Athena or Starburst. BI and analytics tools would connect to these databases to provide visualization and exploration capabilities.
The advantage of this approach is that it enables organizations to handle larger volumes and different types of data than an EDW would allow for, using a ‘store now, analyze later’ approach. The drawback is that much of that complexity moves into the preparation stage as you attempt to build a data hub or “lake house” out of the data lake. It is a highly specialized engineering project toiled over by teams of big data engineers, and which is typically maintained via a bulky and arcane code base. Agility is thus rarely achieved, and data pipeline engineering is once again a time and resource sink.
3. Siloed data domains (walled gardens)
The proliferation of SaaS-based cloud databases and managed data pipeline tools have enabled business units to deploy their own data pipelines, without the involvement of a centralized IT team. For example, a marketing department might find it can answer its own data requirements using tools such as Fivetran for ingestion, Snowflake for storage and consumption, and Tableau for presentation.
Each business domain locally optimizes based on its requirements and skills, and is responsible for its own pipeline architecture, with problems often solved using proprietary technologies that do not communicate with each other, with the potential of multiple departments generating data sets from the same source data that are inconsistent due to using different logic.
The advantage of this approach is that it provides a high level of business agility, and each business unit can build the analytics infrastructure that best suits their requirements. The data engineering bottleneck is largely averted (at first) as there is no centralized organization responsible for building data pipelines and maintaining them.
This type of architecture is often seen at smaller companies, or in larger ones with poor data governance. Its main drawback is in the inconsistencies that will inevitably form when each team is working with its own copy of the data and performing further manipulations and transformations on that data. It will quickly become apparent that no two teams see the same data, and attempts to reconcile these differences often involve the same data engineering challenges as before. Also, unless the department has skilled data engineers, the pipelines will be limited to simple use cases (BI dashboard).
4. Open decoupled architecture (data mesh)
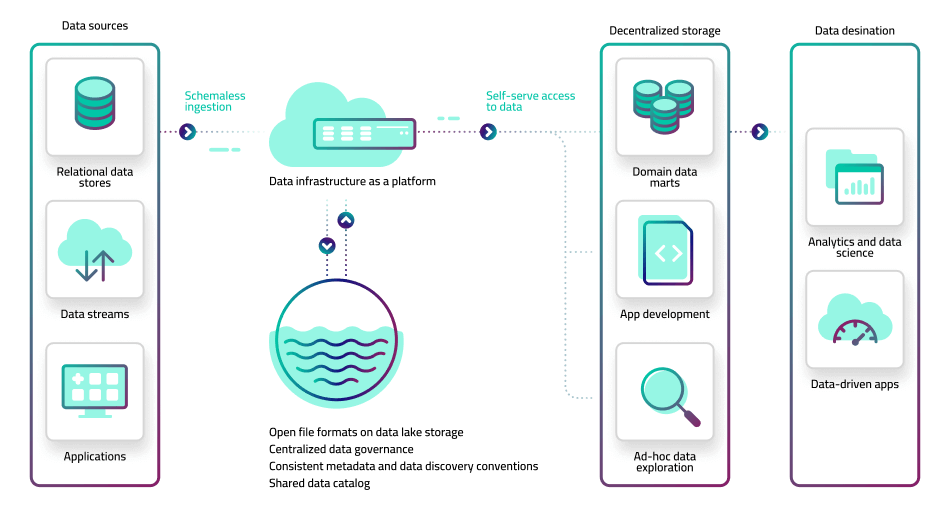
The modern approach to data pipeline engineering aims to provide a better balance between centralized control and decentralized agility. In this model, each domain area works with its own data using the best available technologies, tooling, and technical resources at its disposal; however, source data is made available via an open data lake architecture, predicated on open file formats and analytics-ready storage. This is sometimes referred to as a data mesh.
In this architecture, raw data is ingested into object storage with minimal or no preprocessing, similar to the data lake approach. Different teams can then pull the data out of the lake and run their own ETL or ELT pipeline in order to deliver the dataset they need for further analysis. Data is then written back to the lake in an open file format such as Apache Parquet, while preparing the data using consistent mandated conventions and maintaining key attributes about the data set in a business catalog. This offers the benefits of having decentralized data domains but with a level of central governance to ensure it can be discovered and used by other teams, and without forcing a centralized data team to manage every inbound or outbound pipeline.
The advantage of this approach is that it enables both business and tech teams to continue work with the tools that best suit them, rather than attempt to force a one-size-fits-all standard (which in practice fits none).
The drawback, besides the mindset change required by central teams, is that you still have decentralized data engineering which can exacerbate the bottleneck problem by spreading talent too thinly. This can be ameliorated by using low-code data pipeline tools.
Learn More About Data Pipelines and Data Architecture
The above is merely scratching the surface of the many potential complexities of data pipeline architecture. Each specific implementation comes with its own set of dilemmas and technical challenges.
To learn more about data pipelines and data architecture, check out the following resources:
- Read our streaming data architecture guidelines
- Discover best practices in data lake design
- Browse interactive data pipeline examples
- Try SQLake for free for 30 days. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes