
Explore our expert-made templates & start with the right one for you.
Using Schema Discovery to Explore Kafka/Kinesis Streams
-
 Eran Levy
Eran Levy
- Use Cases
- November 28, 2019
One of the unique challenges of working with unstructured or semi-structured data is handling schema changes. Due to production issues, changes in development workflows or the way data ingestion pipelines are built, the same Kafka or Kinesis stream can become radically different over time – it might have new fields added, or fields that were previously populated for every event might only sparsely contain data.
When data is stored in unstructured object storage (i.e. in a data lake), schema changes can break or significantly slow down analytic workflows as data consumers struggle to find the data they need. Let’s take a closer look at this issue and see how it can be addressed by introducing visibility into streaming data using automated schema discovery.
Example Scenario: App Activity Analysis
To understand where schema discovery comes into play, we can think of a scenario from the app development world: The Product team wants to understand which new feature to introduce, based on existing app usage data. In order to do so, a data analyst is asked to build a dashboard that breaks-down product feature activity be Geo, paid/free user, subscription type and other features.
The data that the analyst needs in order to build this dashboard is coming from a Kinesis stream that records user activity on the app; however, this stream contains hundreds of keys, many with similar names – e.g. for Geo, our analyst is debating between city, state, country, city/state, and zip code. For some of these keys, data exists in 100% of events, for others it might be 50% or even less, but it is impossible to know that by looking at a single event. The data type is also often unclear, with some time-based fields arriving as a string, others as epoch timestamp, and others as human readable date.
At this stage, the analyst needs to go to the DevOps team in order to make sense of the data, figure out which fields are actually populated, extract and transform the relevant events – before any actual analysis can begin. This means creating an ETL pipeline to pull random samples and infer the data structure, which becomes another backlog item that could take weeks or months to address. Meanwhile the Product team is still waiting on the data – eventually either giving up and making the decision without data, or delaying new feature development for months on end.
What causes this type of conundrum, and how can it be prevented?
The challenge: why streaming data is often opaque
Streaming data is, by definition, dynamic and continuously generated. Capturing data as a stream gives us a much more granular view of a series of small ‘events’ – such as user activity in our example – but the absence of predefined schema and the fact that the same data would often be used for multiple production environments can make it difficult to understand the contents of a particular stream, and to create ETL and analytics pipelines that rely on that data.
Common obstructions to data stream visibility include:
- Data changes over time: this could be due to completely benign reasons – different developers add fields to capture some new type of data, content becomes irrelevant in newer version releases, naming conventions change or calculations are performed differently. It could also be due to production issues with data collection or ingestion, resulting in failure to capture data that used to be available.
- Data consumers aren’t familiar with the data: following the previous point, the people who are making schema changes are often DevOps or R&D teams, while analytics and data science teams have little visibility into the process until they actually need the data. This disconnect between different groups that rely on the same data can often make the data difficult to access for the people who need to consume data.
- Solutions are manual and error prone: in order to understand the contents of our Kafka or Kinesis stream, DevOps or data engineers need to either perform full table scans or write code that constantly pulls samples and indexes the metadata in-memory. This is time-consuming and resource-intensive to do on a continuous basis; while ad-hoc sampling for a particular query can be error prone,.
These issues and others can make it incredibly difficult to understand what data we are actually ingesting into our data lake, Debugging ETL pipelines becomes a nightmare of guesswork trying to understand which of dozens of possibly relevant fields could be the cause of the issue; and the lack of visibility makes data under-utilized throughout the organization.
The solution: discover schema-on-read to create visibility and enable self-service analytics
To overcome the challenges we’ve listed in the previous section, data visibility needs to be enforced as early as possible – i.e., when the data is being ingested – rather than waiting until it becomes a necessity. This means creating an automated process for discovering schema on read, and understanding the structure and basic composition of the data as it is being written to object storage.
If you’re using Upsolver SQLake, this would be covered by the Data Source Discovery feature, which auto-detects schema, data types, ingestion errors, and statistics as data is read and persisted to S3; otherwise you would need to code a similar system in-house or use an open-source solution.
The benefits of automating schema discovery include:
- Faster time-to-production for data initiatives: when analysts and data scientists have a clear idea of the schema and contents of a particular stream, and are no longer reliant on data engineering teams to write ad-hoc ETL jobs for this purpose, data initiatives can move much faster on both sides: data consumers have more independence, while data providers have more time to pursue other mission-critical initiatives.
- No coding: automated schema discovery reduces the need to maintain an ETL job for sampling the data and inferring schema, which saves engineering and infrastructure resources.
- Easier to identify production issues: visibility into data allows you to see when certain data stops coming in, or which fields might be affecting errors in a certain pipeline.
Example: Using SQLake’s schema discovery on Kinesis Stream data
SQlake automates schema discovery for supported data sources – including Apache Kafka, Amazon Kinesis, and existing data lakes such as Amazon S3. This is achieved using SQlake’s data lake indexing technology, which enables the platform to extract metadata, schema, and statistics as the data is being ingested; this can then be used to create various transformations and enrichments, which removes the need to rely on ad-hoc sampling or ‘blind’ ETL jobs.
Here’s how schema discovery on a live Kinesis stream would look in SQlake:
Schema detection on-read
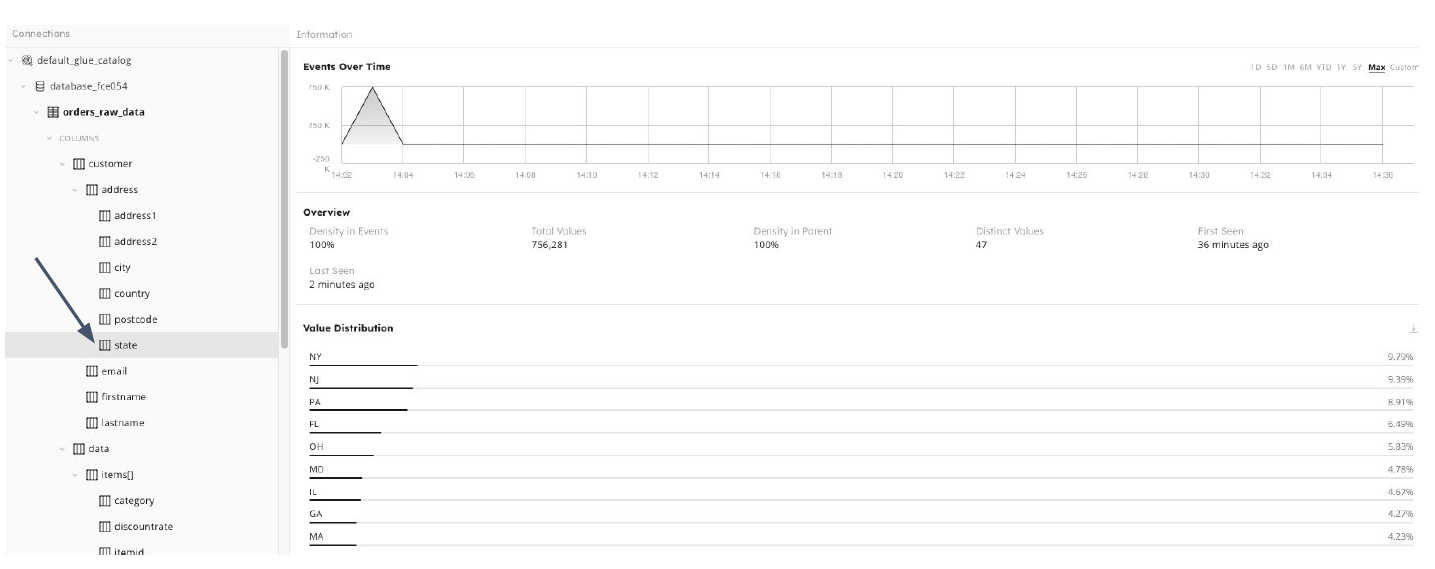
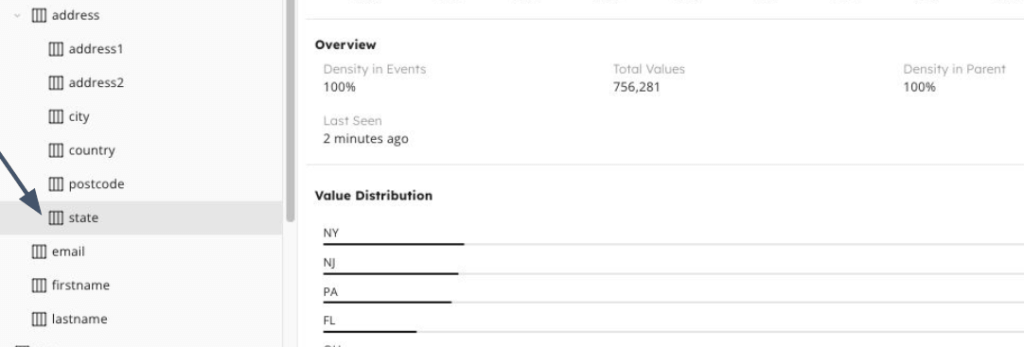
When adding a new data source, SQlake automatically indexes the data and makes the schema instantly viewable, including nested data structure and the data type contained in each field. You can also use the search function to find a specific key within your data source:

Data Source visualization
The graph displays the amount of data streamed over time with relation to a selected field, as well as statistics such as density in events, and unique values, It also allows you to see values distribution within that field. In the table underneath we can see a preview of the data pulled from events within the stream.
Using schema-on-read to create transformations
Since SQLake is an end-to-end declarative data lake ETL platform, we can easily verify that the field we want to use in a transformation will be viable, for example to ensure that this field contains data in a significant amount of events (density) and that the data is stored in the format we need (value distribution).
Next Steps
- Learn more about streaming data management and transformation by watching our recent webinar with Amazon Web Services.
- Read about how to address schema evolution automatically.
- Get instant visibility into your Kafka or Kinesis streams by trying SQLake for free. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
- Schedule a demo to learn how you can bridge the gap between the data analyst and the data lake.
