








Explore our expert-made templates & start with the right one for you.
Product overview
Data generated by your product applications and services is your biggest lever to delivering differentiated product and user experiences.
Upsolver helps you extend your business moat by unlocking the full value of your moat data: data that’s uniquely yours provides the best looking glass into how your users benefit from your products and services—and what’s lacking.
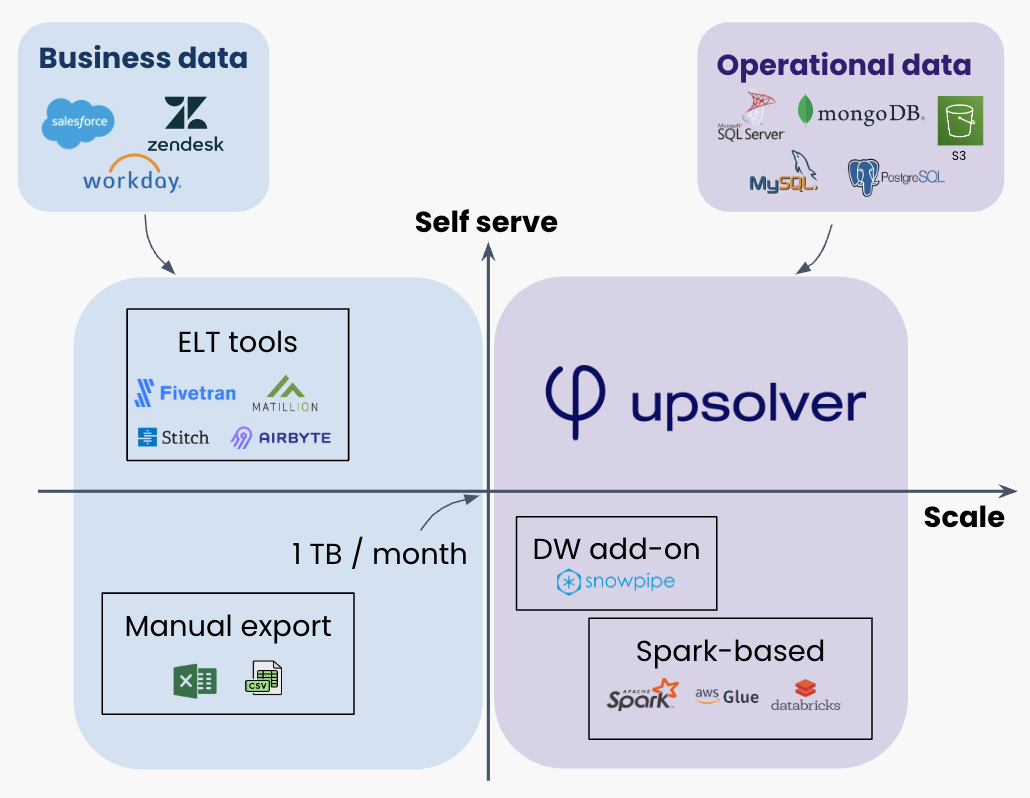
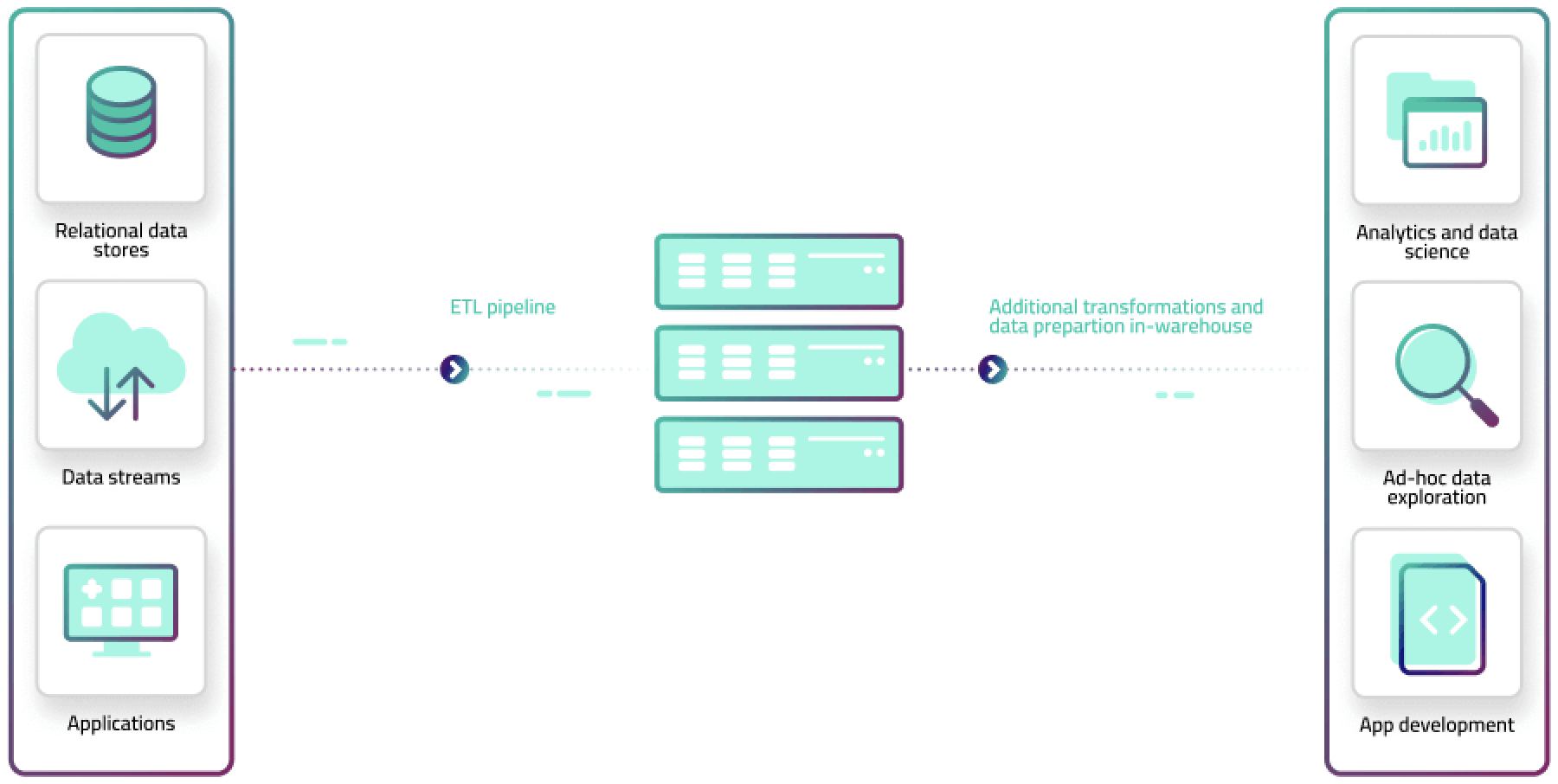
Addressing the scaling bottleneck of data movement
Level of effort and engineering complexity increase disproportionately with increasing scale of production data to be ingested. Self-serve solutions are designed for small business data obtained through third party SaaS connectors, which caps out around 1TB/month.
Beyond that, data ingestion relies on home-grown solutions leveraging low-level—often open source—software and a lot of scripting. That’s the bottleneck we’re here to open up. Upsolver provides a self-serve, flexible-development, cloud-native solution that can scale infinitely.
CDC that autoscales
- A modified debezium engine that doesn’t require Kafka Connect
- Database replication that’s live, not dependent on a batch process
- Automatic mapping of new and changed tables to the target without dev intervention
- Large coverage of operational database types: Postgres, MySQL, MSSQL Server, MongoDB and more
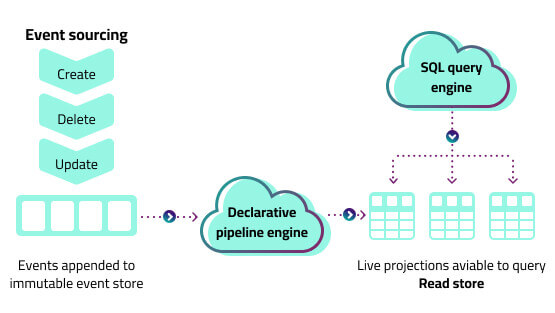
Streaming data ingestion from prod message queues
- Consume from the same message buses your services leverage to transfer operational log data and API events
- Handle any data payload—nested, evolving, sparse, massive
- Replay and reprocess data from a previous state without returning to source or rerunning pipelines
- Support for all modern streaming services including Kafka and Kinesis
Production treatment for prod data
→ Guaranteed exactly-once processing and strong ordering of data
→ Mask, redact and tag sensitive data in realtime
→ Exclude and coalesce fields to avoid writing redundant data from source
→ Set quality expectations and drop or warn in case of expectation violation
Data Observability
→ Live and historical statistics on data volume catches anomalous flow
→ Cumulative statistics by field including:
→ data density
→ uniqueness
→ type evolution
→ distinct and top values
→ Incident forwarding to incident management software
→ Live alerting on unexpected values as well as new or stale fields