Explore our expert-made templates & start with the right one for you.
Benchmark Report: Data Processing for a Near Real-Time Data Warehouse
The advent of the cloud data warehouse (CDW) including Amazon Redshift, Snowflake, Google BigQuery and Azure Synapse Analytics has kicked off a migration of BI reporting and analytics to the cloud, primarily off-loading or replacing the on-prem data warehouse for handling structured batch data. Naturally companies who have adopted a CDW want to leverage that investment to their big data and streaming data. The question is whether the CDW offers adequate latency and price/performance to do the job.
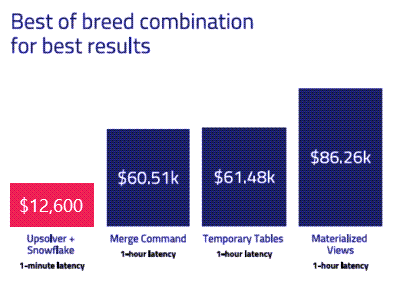
This benchmark report reviews four approaches to processing data for near real-time analytics, using Snowflake Data Platform as the destination for analytics. Our goal was to understand the differences and trade-offs across these requirements:
– Latency to obtain query-ready data
– Cloud compute cost to process the data
– Time required to develop and maintain the data pipeline
– Cost and complexity of infrastructure the data team needs to maintain as scale, velocity and consumption requirements change
Upsolver is a data transformation engine, built for data lakes, that automates complex orchestrations with SQL-based declarative pipelines. Upsolver customers deal with complex data sets, such as machine generated data, whether structured or semi-structured, that is continuously arriving as streams or small, scheduled batches. They rely on both data lakes and data warehouses in their architecture and have both internal and external data consumption use cases. We wrote this report to answer the question we frequently get asked: “What is the best way to architect our infrastructure for the future?”
Powering data lakes for data-intensive companies
