
Explore our expert-made templates & start with the right one for you.
Building a Real-Time Architecture: 8 Key Considerations
-
 Jerry Franklin
Jerry Franklin
- Cloud Architecture
- September 28, 2021
The need to process data in real-time has more and more organizations augmenting traditional batch processing data architectures with real-time streaming architectures. In a real-time architecture you process and analyze or serve data as close as possible to when you get a hold of it, sometimes in less than a second, or minutes later at most. While in theory any data-driven organization could benefit from zero or near-zero latency, it’s not critical in every case.
For example, higher latency is probably sufficient for:
- BI reports – Dashboards that are hours out of date are not appreciably less useful than those updated every minute, depending on the type of business, of course.
- Product analytics – Tracking behavior in digital products to understand feature use, evaluate UX changes, increase usage, and reduce abandonment.
- Data science – Usually looking for patterns across large sets of historical data; insights and actions do not usually change based on having up-to-the second data.
But as data, analytics, and AI become more embedded in the day-to-day operations of many organizations, real-time architecture is becoming essential – especially when data is being generated in a continuous stream and arriving at high velocity.
Companies benefit most from a real-time architecture when they must ask questions such as:
- Which ad or offer do we automatically serve an online customer? (clickstream analytics)
- Do we approve this transaction? (fraud detection)
- Should we block this user? (cybersecurity)
- Is this equipment in danger of failure? (predictive maintenance)
Common use cases that compel a real-time architecture include:
- Fraud detection – Combining real-time transaction analysis with complex machine-learning algorithms to identify patterns and detect anomalies that signal fraud in real-time.
- Online advertising and marketing intelligence – Tracking user behavior, clicks, and interests, then promoting personalized, sponsored ads for each user; measuring audience reactions to content in real-time to make fast, targeted decisions about what to serve visitors and customers and drive leads.
- Cybersecurity – Identifying anomalies in a data stream to isolate or neutralize threats – for example, a suspicious amount of traffic originating from a single IP address.
- IoT sensor data – Calculating streams of data in real-time – for example, to monitor mechanical or environmental conditions or inventory levels and respond almost immediately.
- Online gaming – Streaming player activity, as each player’s gaming experience improves iteratively; each successive iteration generates more data, potentially altering the gaming experience for the iteration that follows.
A Real-time Architecture Within Reach
For many organizations, achieving a real-time streaming data architecture may seem daunting – a complex project that requires substantial specialized engineering, that’s expensive to maintain, and that has a high risk of delay or outright failure. But with modern tools, this no longer need be the case. You no longer have to break your budget or have a huge engineering staff to deploy, manage, and maintain a real-time architecture.
Let’s discuss what moving to a real-time architecture looks like. Later in this blog we’ll highlight a few companies that have successfully transitioned – without a phalanx of specialized engineers – including one company whose entire real-time system is overseen by a single engineer.
So what might a real-time data architecture look like, and what are the skills involved?
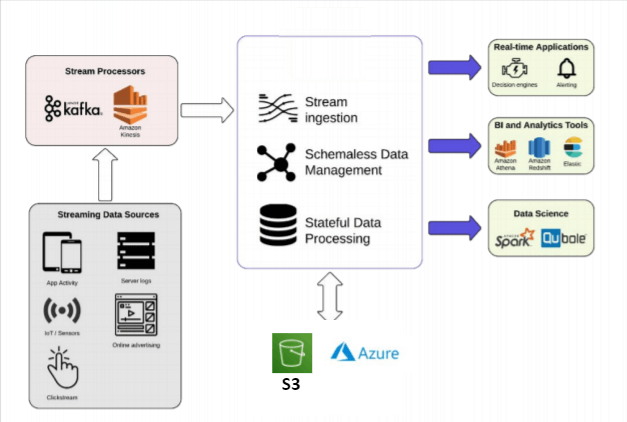
The above reference architecture is generally applicable: Data streams in from a variety of producers, typically delivered via Apache Kafka, Amazon Kinesis, or Azure Event Hub, to tools that ingest it and deliver it to a range of data stores and analytics engines. Between source and destination the data is prepared for consumption for a variety of reasons, including normalization, obfuscation of PII, flattening of nested data, filtering, and joining of data from multiple sources.
Guidelines for Building a Real-time Architecture
Keep in mind these concepts when designing a system:
Deploy a schema-on-read model.
Understand and react to the data as it is being ingested – the schema of each data source, sparsely populated fields, data cardinality, and so on. Inferring schema and data profile on read rather than specifying on write saves you much trouble down the line, because as schema drift occurs (inevitable new, deleted, and changed fields) you can build ETL pipelines that adapt based on the most recent data.
Retain raw data in inexpensive cloud object storage.
Many real-time use cases involve detecting an anomaly or divergence from historical trends. If you retain data in cloud object storage, you’ll always have your data available no matter what platform you use to manage your data lake and run your ETL.
Use a well-supported central metadata repository
Such examples include AWS Glue or a Hive metastore (for Azure systems). Since it’s practical to centrally manage all your metadata in a single location, you might as well choose one that doesn’t lock you into a specific tech stack.
Optimize query performance
The following best practices improve query performance (and therefore compute cost) for most business cases:
- Converting to efficient columnar file formats such as Parquet or Avro
- Compacting (merging) small files frequently
- Partitioning data appropriately for your use
- Indexing the data and compressing the index
One question is whether to implement these by hand or find a service that has these capabilities built in.
Choices and Costs When Considering a Real-time Architecture
There are many choices and combinations you can employ when you move to a real-time architecture. We categorize and review them below.
DIY with Open Source Components
You can certainly do this by stitching together only open-source tools – Hadoop, Spark, Kafka, and so on. While the cost of the software (zero) is attractive, as with the proverbial “free puppy” an open source solution comes with consequences – it is difficult, expensive, and time-consuming to deploy and manage. It requires many months of manual pipeline coding in Scala and Python (at least) and expertise in distributed systems. The need for heavy data engineering and DevOps (to address bugs and change requests) creates a bottleneck between the data engineers and the data end users (business analysts, data scientists). With the further cost of additional hardware, an open source deployment can easily and substantially exceed most private software license prices. There’s also the opportunity cost incurred when you use high-end developers for lower-skill data pipeline building.
Blending Open Source and Licensed Services
Many organizations have chosen instead to assemble a patchwork of open-source and licensed software tools that vary based on the particular data lake implementation. Upfront costs are manageable or predictable, but back-end costs still can vary wildly. Different systems still require significant customization and manual coding to manage, process, and structure streaming data. And it’s challenging, if not daunting, to evaluate and then assemble all the components you might need for an end-to-end real-time architecture.
The table below lists the most common platforms or components comprising a real-time streaming architecture:
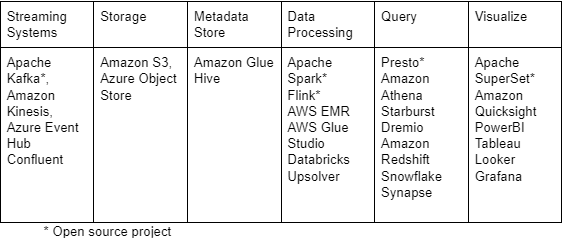
Managed Services
Managed services arose to hide the complexity of best-of-breed DIY; their uniform and proprietary technologies do handle the end-to-end deployment of a real-time architecture, and they are designed to work well together. And cloud data warehouses such as Snowflake separate storage from compute, enabling them to offer a low-latency architecture. Costs at first again appear manageable. But there are unknown costs here, as well:
- The services are usage-based (compute time) and/or storage-based (partitions/shards per hour, GB per hour). You can easily exceed your budget if you’re not careful with the amount of operational data you wish to use or store.
- There are lost opportunity costs here, as well; anything you might need outside of the service’s environment calls for manual tuning and complex customization, again requiring expensive data engineers.
- There’s also technological opportunity lost; most managed services lock you into a proprietary technology stack and data format, which can create large switching costs in the future if you want to take advantage of technological innovations occurring outside their ecosystem.
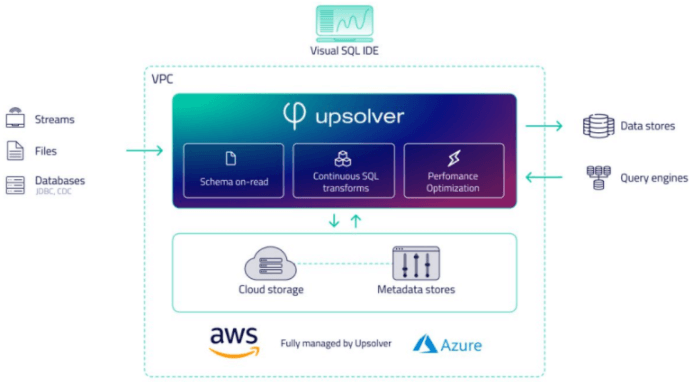
An Automated Platform – the Upsolver Approach to Real-Time Architecture
Upsolver is unique in that it automates most of the effort around building a real-time architecture. Upsolver is a data processing engine for cloud data lakes that transforms streaming and batch data into analytics-ready tables, continuously at scale. You can query these tables on the data lake or output them to cloud data warehouses and other systems. Upsolver shrinks the time to build pipelines to hours, and delivers substantial cost savings without sacrificing power or performance.
Upsolver provides:
- A visual UI for building pipelines quickly through native connectors, data profiling, and drag/drop SQL.
- Automation of time-consuming “pipeline plumbing” and table management such as compaction, orchestration, upserts, and more.
- Excellent performance on intensive operations such as high cardinality joins or window functions running continuously at scale.
- Unique index compression that provides a 10X price/performance vs. Spark ETL.
- A fully-managed service that runs in your VPC or our multi-tenant cloud.
Real-World Models: Real-time Architectures Delivering Value Quickly and Cost-Effectively
Companies of different sizes and in different industries are profiting from the real-time architectures they have recently implemented – far more quickly and efficiently than they’d first imagined. Here are just a few:
Bigabid Builds a High-Performance Real-time Architecture and Improves Modeling Accuracy 200X
Bigabid brings performance-based advertisements to app developers, so clients only pay when new users come to their application through the ad. Bigabid uses machine learning (ML) for predictive decision-making and goes beyond social media and search engine data sourcing to create an in-depth customer user profile.
Bigabid wanted to introduce real-time user profiling to its algorithmic decision engine. To do this it had to replace its daily batch processing with real-time stream processing.
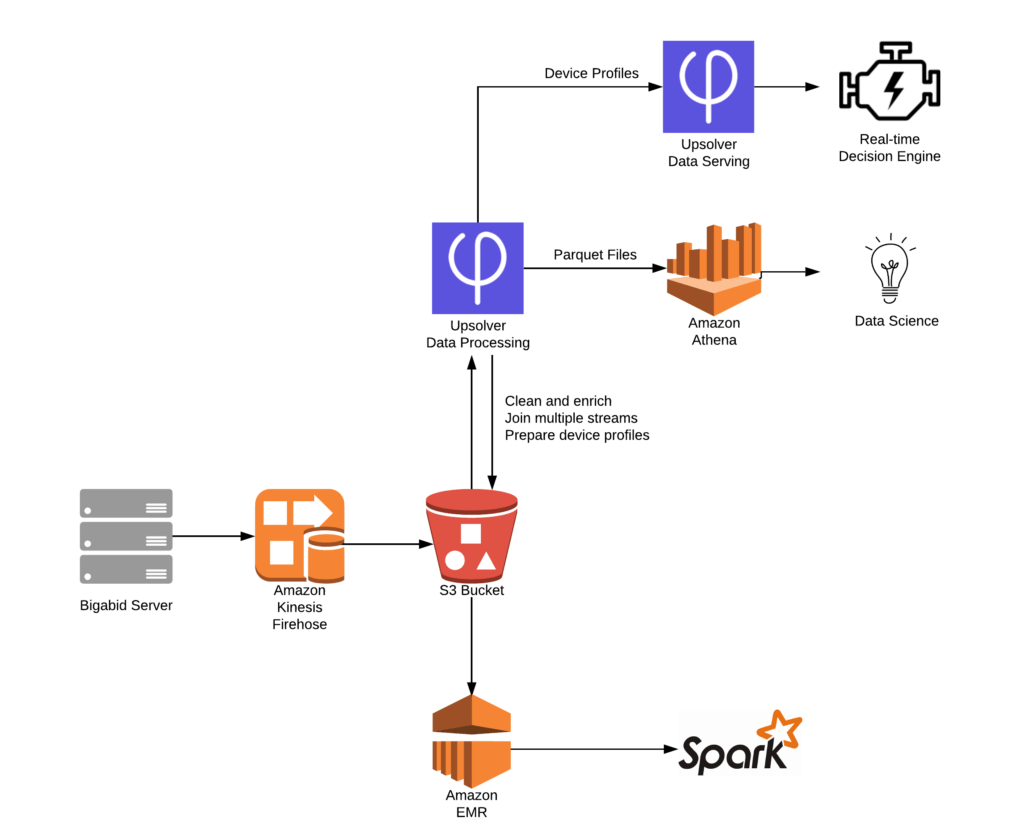
Using Upsolver’s platform, Bigabid built a working proof of concept for its real-time pipeline in just hours. That prompted Bigabid to move forward. Using Upsolver’s visual no-code UI, Bigabid built its real-time architecture so quickly, it saved the equivalent of 6-12 months of engineering work from four dedicated engineers.
What the real-time architecture looks like
- Bigabid uses Kinesis Firehose to ingest multiple data streams into its Amazon S3 data lake.
- It uses Upsolver for data ETL, combining, cleaning, and enriching data from multiple streams to build complete user profiles in real-time.
- Bigabid also uses Upsolver to prepare data for queries in Amazon Athena.
- Instead of coding ETLs, Bigabid used Upsolver’s visual IDE to easily flatten the data into tables, perform data validations, create enrichments (geo attributes from IP, device attributes from user agent) and automate the process of creating and editing Athena tables.
- In the process, Upsolver also optimizes Athena’s storage layer (conversion to Parquet format, compaction of small files) so queries run much faster.
Since using Upsolver on AWS, Bigabid has improved its modeling accuracy and its performance by 200x compared to the prior year. And it’s all maintained by a single user.
A Single Developer at Proofpoint Builds an Agile and Scalable Real-time Data Infrastructure over S3
As more and more employees work remotely, they present companies with security and accessibility challenges.
Meta Networks, acquired by Proofpoint, is a fast-growing startup that secures enterprise networks for the cloud age. Its Network-as-a-Service enables businesses to rapidly connect people, applications, clouds, and sites, and secure them with a software-defined perimeter.
The Meta NaaS collects large volumes of data in real-time: DNS, traffic, IP addresses, API access, and more; a single user visiting a single website can produce hundreds of new data points. As its customer base and operations grew, the team realized they needed a scalable way to manage, store, and structure the data streaming in, and also provide analytics and reporting to their customers. As a lean startup with limited data engineering resources, Meta preferred to avoid the complexity of an enterprise data warehouse or open-source tools such as Spark and MapReduce.
The Meta team adopted Upsolver as an integral part of the company’s real-time architecture, simplifying and improving the entire cycle of transforming raw data into valuable information for the company and its customers.
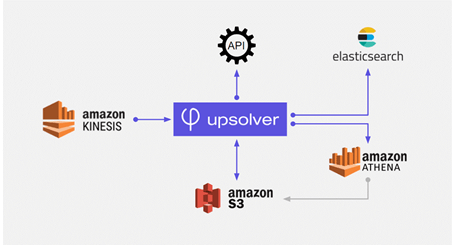
The company uses Upsolver to join multiple data streams in-flight. It combines raw data from several APIs to present enriched information to Meta Networks customers, who now have access to actionable reporting about activity on their network. The company now processes terabytes of streaming data daily with a one-second average query response time.
And it all took a single developer fewer than three weeks to implement Upsolver and fully integrate it within Meta’s infrastructure. Meta Networks saved months of development time and hundreds of thousands of dollars in developer hours that would have been required to develop an alternative solution in-house using Apache Spark.
Today the same developer continues to manage Meta’s growing data lake through Upsolver, adding new capabilities in a matter of hours – which further enables the company to continue developing its NaaS platform and rapidly introduce new analytical features for its customers.
Sisense Builds a Versatile Data Lake for User Behavior Monitoring with Minimal Engineering Overhead
Sisense is a leading global provider of business intelligence software. One of the richest sources of data the company has to work with is product usage logs, which capture all manner of users interacting with the Sisense server, the browser, and cloud-based applications.
The rapid growth in its customer base created a massive influx of data. The company accumulated more than 200bn records, with more than 150gb of new event data created daily – 20 terabytes overall.
To effectively manage this sprawling data stream, Sisense set out to build a data lake on AWS S3, from which they could deliver structured datasets for further analysis using its own software – and to do so in a way that was agile, quick and cost-effective. The team used Upsolver to avoid the complexities of a Spark/Hadoop-based project, and quickly began generating value for the business.
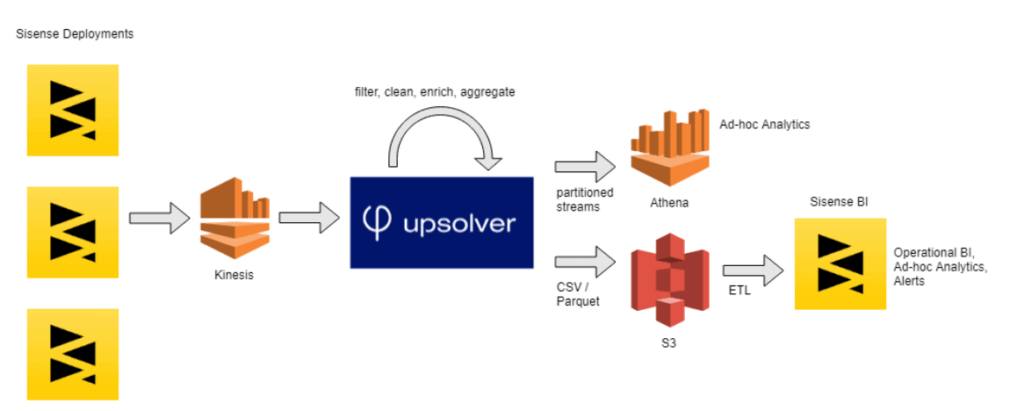
Upsolver processes the product logs that stream in via Amazon Kinesis. It then writes columnar CSV and Parquet files to S3. Sisense uses these for visualization and business intelligence via its own software. Additionally, Upsolver sends structured tables to Athena to support ad-hoc analysis and data science use cases.
Upsolver’s ability to rapidly deliver new tables generated from the streaming data, along with the powerful analytics and visualization capabilities of Sisense’s software, made it incredibly simple for the Sisense team to analyze internal data streams and gain insights from user behavior – including the ability to easily slice and dice the data and pull specific datasets needed to answer ad-hoc business questions.
More Information About the Upsolver Platform
There’s much more information about the Upsolver platform, including how it automates a full range of data best practices, real-world stories of successful implementations, and more, at www.upsolver.com.
- Download this road map to self-service data lakes in the cloud.
- Review these 7 best practices for high-performance data lakes.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
- Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Cloud Architecture
