
Explore our expert-made templates & start with the right one for you.
Batch vs Stream vs Microbatch Processing: A Cheat Sheet
-
 Eran Levy
Eran Levy
- Streaming Data
- January 21, 2021
Ready to take a deep dive into the world of data streams? Our comprehensive, 40-page Streaming Data eBook is a great roadmap into it, and you can get the full document here for FREE.
The digital age has given enterprises a wealth of new options to measure their operations. Gone are the days of manually updating database tables: today’s digital systems are able to capture the minutiae of user interactions with apps, connected devices and digital systems.
With digital data being generated at a tremendous pace, developers and analysts have a broad range of possibilities when it comes to operationalizing data and preparing it for analytics and machine learning.
One of the fundamental questions you need to ask when planning out your data architecture is the question of batch vs stream processing: do you process data as it arrives, in real time or near-real time, or do you wait for data to accumulate before running your ETL job? This guide is meant to give you a high-level overview of the considerations you should take into account when making that decision. We’ve also included some additional resources if you want to dive deeper.
Batch Processing Definition, Frameworks, and Use Cases
What is batch processing?
In batch processing, we wait for a certain amount of raw data to “pile up” before running an ETL job. Typically this means data is between an hour to a few days old before it is made available for analysis. Batch ETL jobs will typically be run on a set schedule (e.g. every 24 hours), or in some cases once the amount of data reaches a certain threshold.
Batch processing architecture:
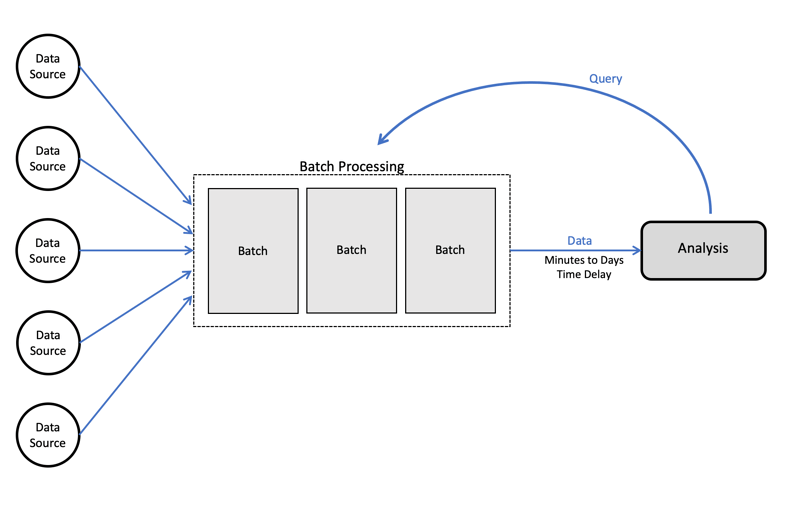
When to use batch processing?
By definition, batch processing entails latencies between the time data appears in the storage layer and the time it is available in analytics or reporting tools. However, this is not necessarily a major issue, and we might choose to accept these latencies because we prefer working with batch processing frameworks.
For example, if we’re trying to analyze the correlation between SaaS license renewals and customer support tickets, we might want to join a table from our CRM with one from our ticketing system. If that join happens once a day rather than the second a ticket is resolved, it probably won’t make much of a difference.
To generalize, you should lean towards batch processing when:
- Data freshness is not a mission-critical issue
- You are working with large datasets and are running a complex algorithm that requires access to the entire batch – for instance, sorting the entire dataset
- You get access to the data in batches rather than in streams
- When you are joining tables in relational databases
Batch processing tools and frameworks
- Open-source Hadoop frameworks for such as Spark and MapReduce are a popular choice for big data processing
- For smaller datasets and application data, you might use batch ETL tools such as Informatica and Alteryx
- Relational databases such as Amazon Redshift and Google BigQuery
Need inspiration on how to build your big data architecture? Check out these data lake examples. Want to simplify ETL pipelines with a single self-service platform for batch and stream processing? Try Upsolver SQLake today.
Stream Processing Definition, Frameworks, and Use Cases
What is stream processing?
In stream processing, we process data as soon as it arrives in the storage layer – which would often also be very close to the time it was generated (although this would not always be the case). This would typically be in sub-second timeframes, so that for the end user the processing happens in real-time. These operations would typically not be stateful, or would only be able to store a ‘small’ state, so would usually involve a relatively simple transformation or calculation.
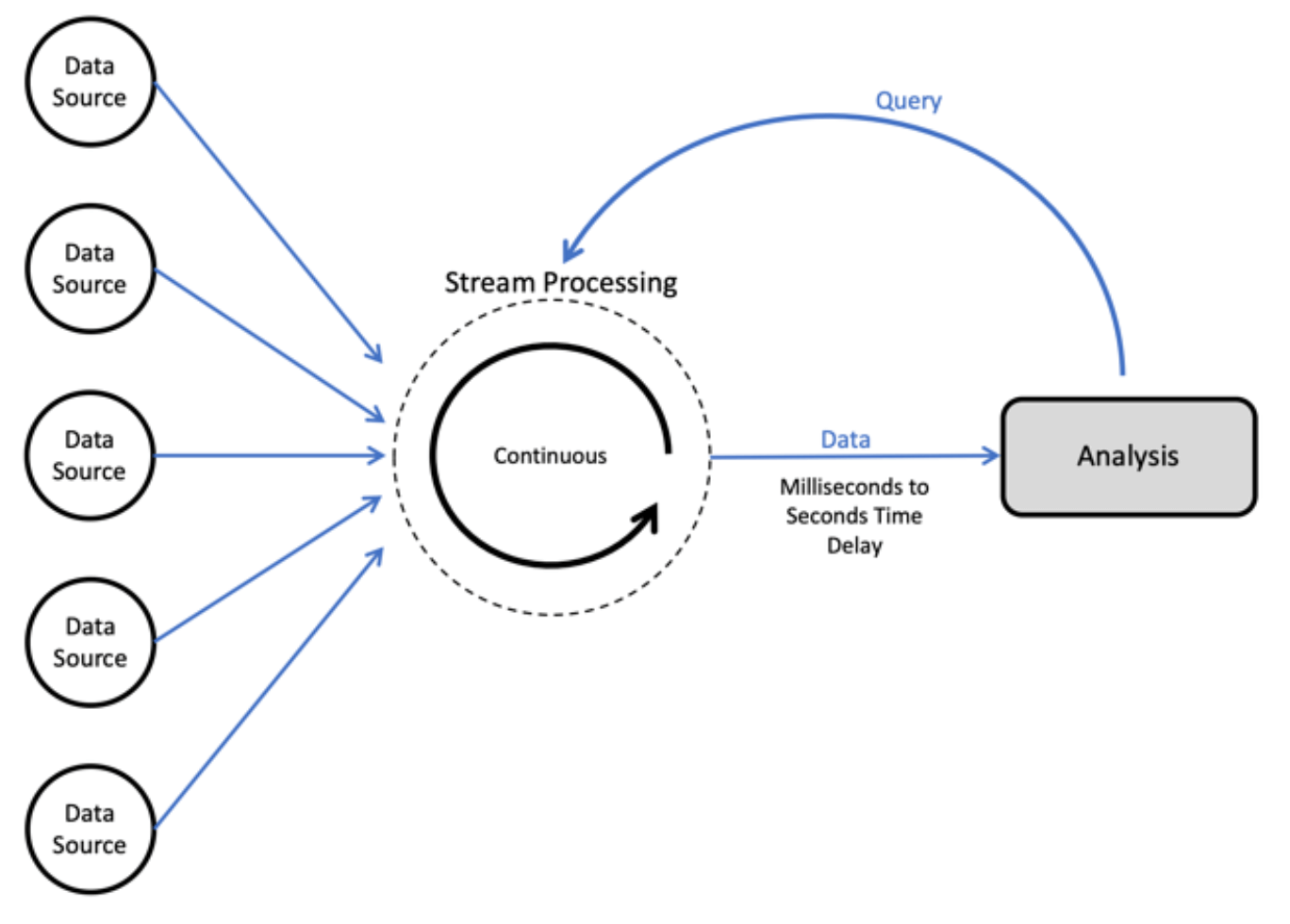
When to use stream processing
While stream processing and real-time processing are not necessarily synonymous, we would use stream processing when we need to analyze or serve data as close as possible to when we get hold of it.
Examples of scenarios where data freshness is super-important could include real-time advertising, online inference in machine learning, or fraud detection. In these cases we have data-driven systems that need to make a split-second decision: which ad to serve? Do we approve this transaction? We would use stream processing to quickly access the data, perform our calculations and reach a result.
Indications that stream processing is the right approach:
- Data is being generated in a continuous stream and arriving at high velocity
- Sub-second latency is crucial
Stream processing tools and frameworks
Stream processing and micro-batch processing are often used synonymously, and frameworks such as Spark Streaming would actually process data in micro-batches. However, there are some pure-play stream processing tools such as Confluent’s KSQL, which processes data directly in a Kafka stream, as well as Apache Flink and Apache Flume.
Learn more about how to choose the best stream processing framework for your use case.
Micro-batch Definition, Frameworks, and Use Cases
What is micro-batch processing?
Micro-batch processing is a method of efficiently processing large datasets with reduced latency and improved scalability. It breaks up large datasets into smaller batches and runs them in parallel, resulting in more timely and accurate processing.
In micro-batch processing, we run batch processes on much smaller accumulations of data – typically less than a minute’s worth of data. This means data is available in near real-time. In practice, there is little difference between micro-batching and stream processing, and the terms would often be used interchangeably in data architecture descriptions and software platform descriptions.
When to use micro-batch processing
Microbatch processing is useful when we need very fresh data, but not necessarily real-time – meaning we can’t wait an hour or a day for a batch processing to run, but we also don’t need to know what happened in the last few seconds.
Example scenarios could include web analytics (clickstream) or user behavior. If a large ecommerce site makes a major change to its user interface, analysts would want to know how this affected purchasing behavior almost immediately because a drop in conversion rates could translate into significant revenue losses. However, while a day’s delay is definitely too long in this case, a minute’s delay should not be an issue – making micro-batch processing a good choice.
Micro-batch processing tools and frameworks
- Apache Spark Streaming the most popular open-source framework for micro-batch processing.
- Vertica offers support for microbatches.
Summary: Stream vs Batch vs Micro-batch Processing
| Processing Type | Processing Description | Latency | Dataset Size | Stateful Processing | Examples |
|---|---|---|---|---|---|
| Batch Processing | Process data after a certain amount of raw data is accumulated | High | Large | Yes | Sorting entire datasets, joining tables in relational databases |
| Stream Processing | Process data as soon as it arrives in real-time or near-real-time | Low | Continuous stream of data | No or small state | Real-time advertising, online inference in machine learning, fraud detection |
| Micro-batch Processing | Break up large datasets into smaller batches and process them in parallel | Low | Small batches of data, near real-time | No or small state | Web analytics, user behavior |
Additional resources and further reading
The above are general guidelines for determining when to use batch vs stream processing. However, each of these topics warrants much further research in its own right. To delve deeper into data processing techniques, you might want to check out a few of the following resources:
- 4 Key Components of a Streaming Data Architecture
- Orchestrating Streaming and Batch ETL for Machine Learning
- A Gentle Introduction to Stream Processing (Medium)
- What is the difference between mini-batch vs real time streaming in practice (Stack Overflow)
Upsolver: Streaming-first ETL Platform
One of the major challenges when working with big data streams is the need to orchestrate multiple systems for batch and stream processing, which often leads to complex tech stacks that are difficult to maintain and manage.
Want to learn more about streaming data analytics and architecture? Get our Ultimate Guide to Streaming Data:
- Get an overview of common options for building an infrastructure
- See how to turn event streams into analytics-ready data
- Cut through some of the noise of all the “shiny new objects”
- Come away with concrete ideas for wringing all you want from your data streams.
Get the full eBook right here, for free
Whether you’re just building out your big data architecture or are looking to optimize ETL flows, SQLake enables you to easily build and run reliable, declarative data pipelines on streaming and batch data via an all-SQL experience. With SQLake, anyone who knows SQL can easily develop and deploy self-orchestrating data pipelines that bring together streaming and historical data without having to manually develop and manage complex orchestration logic or struggle to scale infrastructure to meet data volume.
Try SQLake for free for 30 days. SQLake enables you to easily develop, test, and deploy pipelines that extract, transform, and load data in the data lake and data warehouse in minutes instead of weeks. Try it for free. No credit card required.
To learn more, and for real-world techniques and use cases, head over to the Upsolver SQLake Builders Hub.
Published in:
Blog
,
Streaming Data