
Explore our expert-made templates & start with the right one for you.
Apache Kafka vs Amazon Kinesis – Comparing Setup, Performance, Security, and Price
-
 Eran Levy
Eran Levy
- Streaming Data
- January 15, 2022
Whether you’re just getting into streaming data or are a seasoned architect, you should definitely check out our 40-page Ultimate Guide to Streaming Data Architecture – which covers the topics covered in this article, as well as:
- An overview of common options for building an infrastructure
- How to turn event streams into analytics-ready data
- Concrete ideas for wringing all you want from your data streams
What We’ll Cover in This Article
Apache Kafka and Amazon Kinesis are two of the more widely adopted messaging queue systems. Many organizations dealing with stream processing or similar use cases debate whether to use open-source Kafka or to use Amazon’s managed Kinesis service as data streaming platforms. This article compares Apache Kafka and Amazon Kinesis based on decision points such as setup, maintenance, costs, security, performance, and incidence risk management.
The good news is, if you are using Upsolver SQLake to build your data pipelines, it can ingest data both either. SQLake is our all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for batch and streaming data . It automates everything else, including orchestration, file system optimization and infrastructure management. You can execute sample pipeline templates, or start building your own, in Upsolver SQLake for free.
Apache Kafka – The Basics
Apache Kafka was started as a general-purpose publish and subscribe messaging system and eventually evolved to become a fully-developed, horizontally scalable, fault-tolerant, and highly performant streaming platform. Learn more about Kafka architecture.
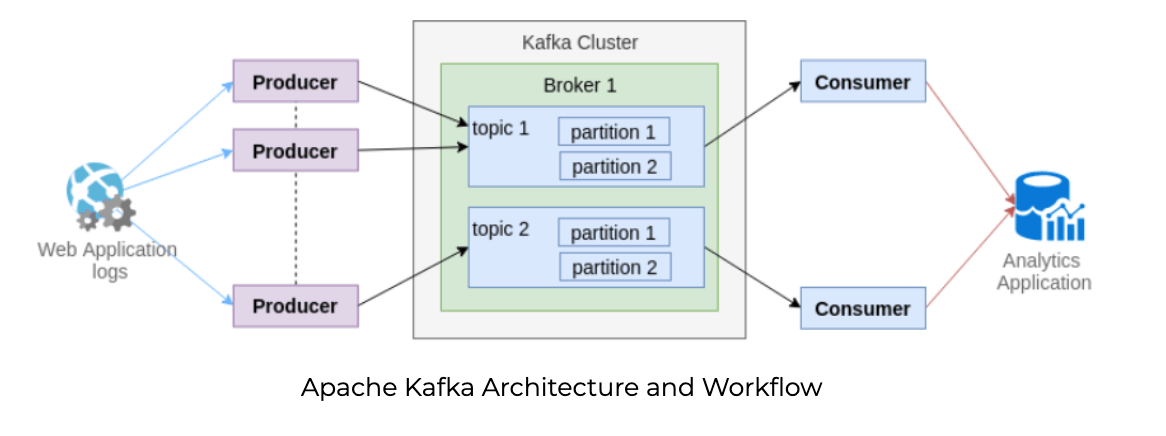
Kafka runs on a cluster in a distributed environment, which may span multiple data centers. The Kafka Cluster is made up of multiple Kafka Brokers (nodes in a cluster). A topic is designed to store data streams in ordered and partitioned immutable sequence of records. Each topic is divided into multiple partitions and each broker stores one or more of those partitions. Applications send data streams to a partition via Producers; the data streams can then be consumed and processed by other applications via Consumers – for example, to get insights on data through analytics applications. Multiple producers and consumers can publish and retrieve messages at the same time.
Q: What is the AWS equivalent of Kafka?
A: There are multiple products in the AWS cloud that can provide similar Pub/Sub functionality to Kafka, including Kinesis Data Streams, Amazon MQ, Amazon MSK, and Confluent Cloud. This article focuses on comparing Kafka and Kinesis as these are the two options we most frequently find our customers debating between.
Amazon Kinesis – The Basics
Like Apache Kafka, Amazon Kinesis is also a publish and subscribe (pub/sub) messaging solution. However, it is offered as a managed service in the AWS cloud, and unlike Kafka cannot be run on-premises.
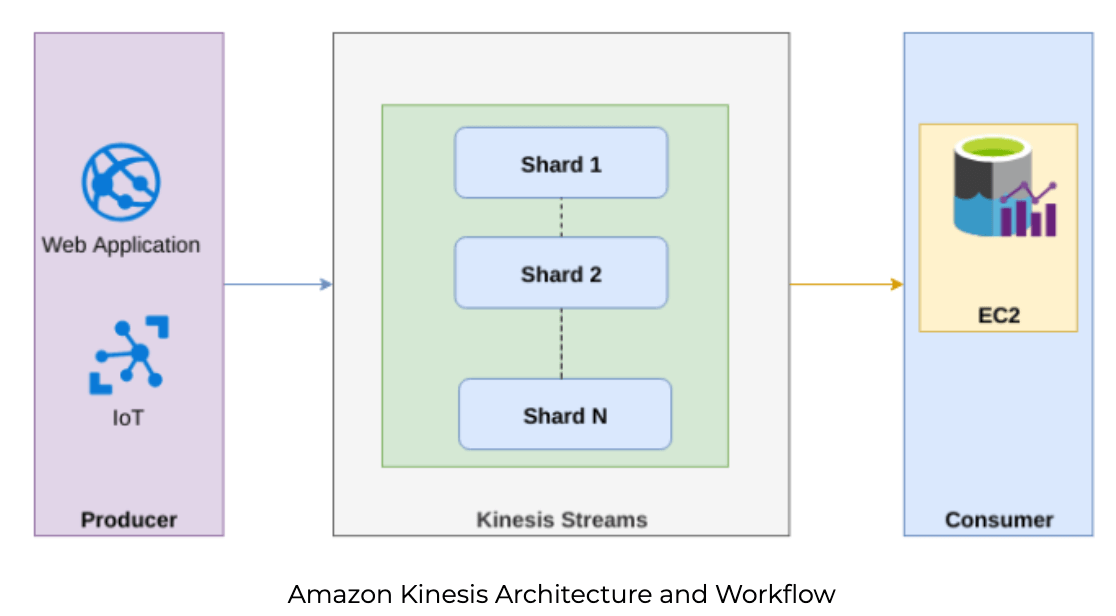
The Kinesis Producer continuously pushes data to Kinesis Streams. A producer can be any source of data – a web-based application, a connected IoT device, or any data producing system. The Consumer – such as a custom application, Apache Hadoop, Apache Storm running on Amazon EC2, an Amazon Kinesis Data Firehose delivery stream, or Amazon Simple Storage Service (S3) – processes the data in real time. Similar to partitions in Kafka, Kinesis breaks the data streams across Shards. The number of shards is configurable, however most of the maintenance and configurations are hidden from the user. There is no such thing as Kinesis topics – the parallel to a Kafka topic is a Kinesis Stream.
Q: Is AWS Kinesis the same as Kafka?
A: While both of these tools offer similar functionality and cover the same use cases, they are unrelated. Kinesis Data Streams is a proprietary product developed by AWS and is not based on open-source Apache Kafka.
Decision Points to Choose Apache Kafka vs Amazon Kinesis
Choosing a streaming data solution is not always straightforward. The decision is based on the metrics you want to achieve and the business use case. Following are some criteria and decision points to compare whether to choose Apache Kafka or Amazon Kinesis as a data streaming solution:

Setup, Management, and Administration
Because Kinesis is fully managed, it is easier to set up than open-source Apache Kafka, especially at scale.
Apache Kafka takes days to weeks to set up a full-fledged production-ready environment, based on the expertise you have in your team. Very complex deployments where resilience, performance, and resource utilization are a priority can take months. As an open-source distributed system, it requires its own cluster, a high number of nodes (brokers), replications and partitions for fault tolerance and high availability of your system.
Setting up a Kafka cluster requires learning (if there is no prior experience in setting up and managing Kafka clusters), distributed systems engineering practice, and capabilities for cluster management, provisioning, auto-scaling, load-balancing, configuration management, a lot of distributed DevOps, and more.
Kinesis is easier to set up than Apache Kafka and may take at a maximum a couple of hours to set up a production-ready stream processing solution. Since it is a managed service, AWS manages the infrastructure, storage, networking, and configurations needed to stream data on your behalf. On top of that, Amazon Kinesis takes care of provisioning, deployment, on-going maintenance of hardware, and software or other services of data streams for you. Additionally, Kinesis producers and consumers can also be created and are able to interact with the Kinesis broker from outside AWS by means of Kinesis APIs and Amazon Web Service (AWS) SDKs.
Performance Tuning – Throughput, Latency, Durability, and Availability
Tuning Apache Kafka for optimal throughput and latency requires tuning of Kafka producers and Kafka consumers. Producers can be tuned for number of bytes of data to collect before sending it to the broker and consumers can be configured to efficiently consume the data by configuring replication factor and a ratio of number of consumers for a topic to number of partitions.
In addition, server side configurations, such as replication factor and number of partitions, play an important role in achieving top performance by means of parallelism. To guarantee that messages that have been committed should not be lost – that is, to achieve durability – the data can be configured to persist until you run out of disk space. The distributed nature of the Kafka framework is designed to be fault-tolerant. For high availability, Kafka must be configured to recover from failures as soon as possible.
In contrast, Amazon Kinesis is a managed service and does not give a free hand for system configuration. The high availability of the system is the responsibility of the cloud provider, as is AWS Kinesis latency. Kinesis ensures availability and durability of data by synchronously replicating data across three availability zones. However, in comparison to Kafka, Kinesis only lets you configure number of days per shard for the retention period, and that for not more than 7 days. The throughput of a Kinesis stream is configurable to increase by increasing the number of shards within a data stream.
Kinesis Costs vs Kafka Costs – Human and Machine
Kafka has no direct licensing costs and can have lower infrastructure costs, but would require more engineering hours for setup and ongoing maintenance
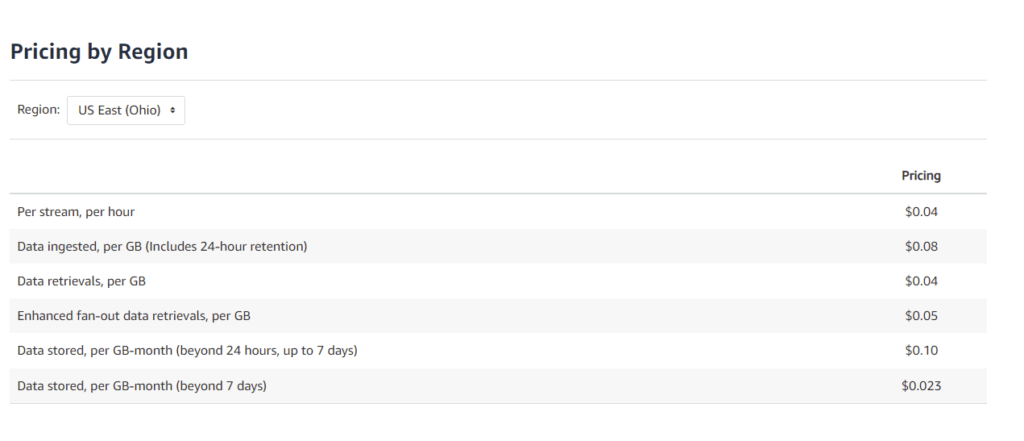
Amazon’s model for Kinesis is pay-as-you-go, with provisioned capacity also available to purchase. It works on the principle that there are no upfront costs for setting up; the amount to be paid depends on the services rendered. AWS Kinesis pricing is based on two core dimensions:
- the number of shards needed for the required throughput
- a Payload Unit – that is, the size of data the producer is transmitting to the Kinesis data streams
These costs are to some degree offset by companies saving the time and monetary expenses of building and constantly maintaining infrastructure. It is also worth considering that Kinesis costs normally are reduced over time automatically based on how much your workload is typical to that of AWS.
Apache Kafka, as an open-source product, does not bear any licensing costs. If configured properly, the associated infrastructure costs (mostly EC2 compute resources) would probably be lower as well, since AWS charges a premium the processing done in Kinesis.
On the other hand, setting up and maintaining Kafka often requires significant technical resources in the form of billed engineer hours for setup and the 24/7 ongoing operational burden of managing your own infrastructure. Moreover, there are costs associated with dedicated hardware, though these costs can be controlled or lowered by investing more labor (and cost) in optimizing the machines to operate at full capacity.
Security
As a managed service, Kinesis is less prone to human error and will be more secure ‘out of the box’. However, a well-configured Kafka implementation will also be very secure.
While both tools are considered very secure, there are some differences in the way security is handled in each one. A common feature between the two is immutability – once an entry is written, the user cannot modify or change it. This mitigates certain risks “out of the box.”
Data security in Kafka is focused on the client-side, including features for secure authentication and authorization. For companies that operate under strong compliance requirements, the ability to run Kafka on-premises might also be crucial. And as an open-source tool, you can configure it as you like and add any additional layers of security, at the cost of having to manage and monitor these additions.
Kinesis, as part of the AWS ecosystem, is covered by Amazon’s general security and compliance policies. It also offers server-side encryption, either using AWS master keys or user-provided encryption libraries. Mainly its advantage is the fact that it is a managed service – leaving less room for human error, which more often than not is the root cause of security breaches.
Resilience and Incident Risk Management
As long as a really good monitoring system is in place for Kafka that is capable of on-time alerting of any failures and a 24/7 team of DevOps taking care of potential failures and recovery, there is less risk of incidence. The main decision point here is whether you can afford outages and loss of data if you do not have a 24/7 monitoring, alerting, and DevOps team to recover from the failure. With Kinesis, as a managed-service, Amazon itself takes care of the high-availability of the system so these are less likely to occur.
Summary: Comparing Kafka to Kinesis
| Kafka | Kinesis | |
| Software costs | None | On-demand or provisions |
| Infrastructure costs | EC2 or physical infrastructure; can be optimized | Based on AWS rates |
| Engineering costs | High | Low |
| Security | Secure, but manual configuration leaves room for human error | Similar security to other AWS products |
| Ongoing management | Requires engineering effort | Managed by AWS |
| Data retention | User-defined | Up to 7 days |
| Performance tuning | Dependent on configuration and manual tuning – especially for features such as high availability | Less room for configuration, but some level of performance guaranteed by AWS |
Managed Kafka Services – Confluent Cloud, Amazon MSK
Between self-managed Kafka and fully-managed Kinesis Data Streams, you can find several options for running Apache Kafka as a managed service – including Confluent Cloud (provided by Confluent) and Amazon Managed Streaming for Apache Kafka (MSK).
Using a managed Kafka service allows you to maintain some level of control over configuration and performance tuning, while removing the need to manually manage clusters and infrastructure (if you’re on the cloud). As with any managed service, you will gain a level of predictability and reduce engineering overhead, at the cost of software usage and licensing fees.
Closing: Which is Better, Kinesis or Kafka?
As with most tech decisions, there is no single right answer to which streaming solution to use. While Kinesis might seem like the more cloud-native solution, a Kafka Cluster can also be deployed on Amazon EC2, which provides a reliable and scalable infrastructure platform. However, monitoring, scaling, managing and maintaining servers, software, and security of the clusters would still create IT overhead.
Choosing a data streaming solution may depend on company resources, engineering culture, and monetary budget, as well as the aforementioned decision points. For example, if you are (or have) a team of distributed systems engineers, have extensive experience with Linux, and a considerable workforce for distributed cluster management, monitoring, stream processing and DevOps, then the flexibility and open-source nature of Kafka could be the better choice. Alternatively, if you are looking for a managed solution or you do not have time or expertise or budget at the moment to set up and take care of distributed infrastructure, and you only want to focus on your application, you might lean towards Amazon Kinesis.
Next step: Aggregating events with SQLake
SQLake is a tool that allows you to automate data pipeline orchestration. It enables you to build reliable, maintainable, and testable data ingestion and processing pipelines for batch and streaming data, using familiar SQL syntax. Jobs are executed once and continue to run until stopped. There is no need for scheduling or orchestration. The compute cluster scales up and down automatically, simplifying the deployment and management of your data pipelines
In the following example we aggregate and output the data into Athena:
CREATE JOB group_testing
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
AS INSERT INTO default_glue_catalog.database_2883f0.kafka_orders_aggregated_data MAP_COLUMNS_BY_NAME
Want more info about streaming data analytics and architecture? Get our Ultimate Guide to Streaming Data:
- Get an overview of common options for building an infrastructure.
- See how to turn event streams into analytics-ready data.
- Cut through some of the noise of all the “shiny new objects.”
- Come away with concrete ideas for wringing all you want from your data streams.
Ready for a more hands-on experience? Build end-to-end pipelines from Kafka or Kinesis to Amazon Athena using Upsolver SQLake. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try SQLake for free for 30 days. No credit card required.
You can also schedule a free chat with our solution architects.
Published in:
Blog
,
Streaming Data