

Explore our expert-made templates & start with the right one for you.
Streaming Data Architecture in 2023: Components and Examples
-
 Eran Levy
Eran Levy
- Streaming Data
- August 1, 2022
This article is an excerpt from our comprehensive, 40-page eBook: The Architect’s Guide to Streaming Data and Data Lakes. Read on to discover design patterns and guidelines for for streaming data architecture, or get the full eBook now (FREE) for in-depth tool comparisons, case studies, and a ton of additional information.
Streaming technologies are not new, but they have considerably matured in recent years. The industry is moving from painstaking integration of open-source Spark/Hadoop frameworks, towards full stack solutions that provide an end-to-end streaming data architecture built on the scalability of cloud data lakes.
In this article, we’ll cover the key tenets of designing cloud infrastructure that can handle the unique challenges of working with streaming data sources – from ingestion through transformation to analytic querying.
First, a bit about us. Upsolver is a group of data engineers and developers who built a product called SQLake, an all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for data in motion, whether in event streams or frequent batches. SQLake automates everything else, including orchestration, file system optimization and infrastructure management. To give it a try you can execute sample pipeline templates, or start building your own, in Upsolver SQLake for free.
Basic Concepts in Stream Processing
Let’s get on the same page by defining the concepts we’ll we be referring to throughout the article.
What is Streaming Data?
Streaming data refers to data that is continuously generated, usually in high volumes and at high velocity. A streaming data source would typically consist of continuous timestamped logs that record events as they happen – such as a user clicking on a link in a web page, or a sensor reporting the current temperature.
Common Data Streaming Examples
Data streaming is used for data that is generated in small batches and continuously transmitted – such as from IoT sensors, server and security logs, real-time advertising platforms, and click-stream data from apps and websites.
What makes streaming data unique?
In all of the scenarios above we have end devices that are continuously generating thousands or millions of records, forming a data stream – unstructured or semi-structured events, most commonly JSON or XML key-value pairs. Here’s an example of how a single streaming event would look – in this case the data we are looking at is a website session:

A single streaming source will generate massive amounts of these events every minute. In its raw form, this data is very difficult to work with as the lack of schema and structure makes it difficult to query with SQL-based analytic tools; instead, data needs to be processed, parsed, and structured before any serious analysis can be done.
Learn more about common streaming data use cases.
What is Streaming Data Architecture?
A streaming data architecture is a framework of software components built to ingest, process, and analyze data streams – typically in real time or near-real time. Rather than writing and reading data in batches, a streaming data architecture consumes data immediately as it is generated, persists it to storage, and may include various additional components per use case – such as tools for real-time processing, data manipulation, and analytics.
Streaming architectures must account for the unique characteristics of data streams, which tend to generate massive amounts of data (terabytes to petabytes) that it is at best semi-structured and requires significant pre-processing and ETL to become useful.
Stream processing is a complex challenge rarely solved with a single database or ETL tool – hence the need to “architect” a solution consisting of multiple building blocks. Part of the thinking behind Upsolver SQLake is to replace these point products with an integrated platform that delivers with self-orchestrating declarative data pipelines. We’ll demonstrate how this approach manifests within each part of the streaming data supply chain.
Why Streaming Data Architecture? Benefits of Stream Processing
Stream processing used to be a niche technology used only by a small subset of companies. However, with the rapid growth of SaaS, IoT, and machine learning, organizations across industries are increasingly adopting streaming analytics. It’s difficult to find a modern company that doesn’t have an app or a website; as traffic to these digital assets grows, and with the increasing appetite for complex and real-time analytics, the need to adopt modern data infrastructure is quickly becoming mainstream.
While traditional batch architectures can be sufficient at smaller scales, stream processing systems provide several benefits that other data platforms cannot:
- Able to deal with never-ending streams of events—some data is naturally structured this way. Traditional batch processing tools require stopping the stream of events, capturing batches of data and combining the batches to draw overall conclusions. In stream processing, while it is challenging to combine and capture data from multiple streams, it lets you derive immediate insights from large volumes of streaming data.
- Real-time or near-real-time processing—most organizations adopt stream processing to enable real-time data analytics. While real time analytics is also possible with high performance database systems, often the data lends itself to a stream processing model.
- Detecting patterns in time-series data—detecting patterns over time, for example looking for trends in website traffic data, requires data to be continuously processed and analyzed. Batch processing makes this more difficult because it breaks data into batches, meaning some events are broken across two or more batches.
- Easy data scalability—growing data volumes can break a batch processing system, requiring you to provision more resources or modify the architecture. Modern stream processing infrastructure is hyper-scalable, able to deal with gigabytes of data per second with a single stream processor. This enables you to easily deal with growing data volumes without infrastructure changes.
To learn more, you can read our previous article on stream vs batch processing.
The Components of a Streaming Architecture
Most streaming stacks are still built on an assembly line of open-source and proprietary solutions to specific problems such as data ingestion, storage, stream processing, and task orchestration. Upsolver SQLake is a modern platform that integrates these functions and offers a seamless way to transform streams into analytics-ready datasets.
Whether you go with a modern data lake platform or a traditional patchwork of tools, your streaming architecture must include these four key building blocks:
1. The Message Broker / Stream Processor
This is the element that takes data from a source, called a producer, translates it into a standard message format, and streams it on an ongoing basis. Other components can then listen in and consume the messages passed on by the broker.
The first generation of message brokers, such as RabbitMQ and Apache ActiveMQ, relied on the Message Oriented Middleware (MOM) paradigm. Later, hyper-performant messaging platforms (often called stream processors) emerged that are more suitable for a streaming paradigm. Two popular stream processing tools are Apache Kafka and Amazon Kinesis Data Streams.
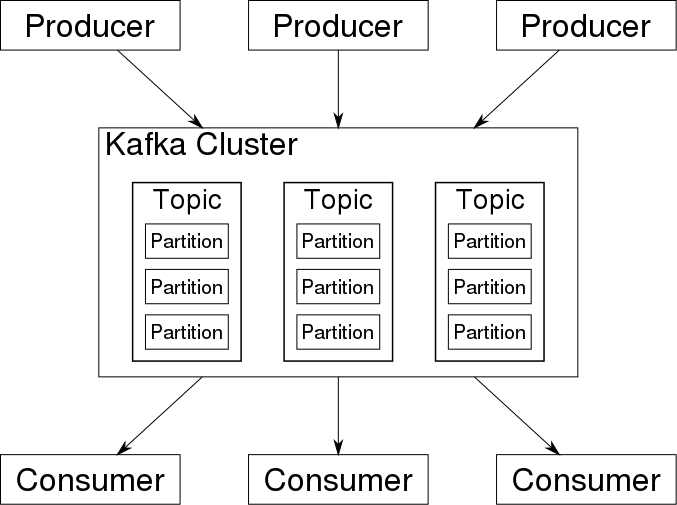
Unlike the old MOM brokers, streaming brokers support very high performance with persistence, have massive capacity of a gigabyte per second or more of message traffic, and are tightly focused on streaming with little support for data transformations or task scheduling (although Confluent’s KSQL offers the ability to perform basic ETL in real-time while storing data in Kafka).
You can learn more about message brokers in our article on analyzing Apache Kafka data, as well as these comparisons between Kafka and RabbitMQ and between Apache Kafka and Amazon Kinesis.
2. Batch and Real-time ETL Tools
Data streams from one or more message brokers must be aggregated, transformed, and structured before data can be analyzed with SQL-based analytics tools. This would be done by an ETL tool or platform that receives queries from users, fetches events from message queues, then applies the query to generate a result – in the process often performing additional joins, transformations, or aggregations on the data. The result may be an API call, an action, a visualization, an alert, or in some cases a new data stream.
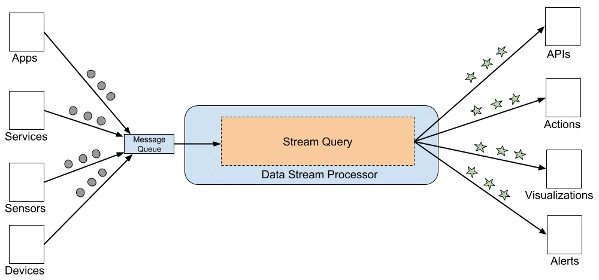
Image Source: InfoQ
A few examples of open-source ETL tools for streaming data are Apache Storm, Spark Streaming, and WSO2 Stream Processor. While these frameworks work in different ways, they are all capable of listening to message streams, processing the data, and saving it to storage.
Some stream processors, including Spark and WSO2, provide a SQL syntax for querying and manipulating the data; however, for most operations you would need to write complex code in Java or Scala. Upsolver SQLake provides a self-service solution for transforming streaming data using only SQL to define transformations declaratively and automatially, without the complexity of orchestrating and managing ETL jobs in Spark. You can try SQLake for free here. No credit card is required.
3. Data Analytics / Serverless Query Engine
After streaming data is prepared for consumption by the stream processor, it must be analyzed to provide value. There are many different approaches to streaming data analytics. Here are some of the tools most commonly used for streaming data analytics.
| Analytics Tool | Streaming Use Case | Example Setup |
| Amazon Athena | Distributed SQL engine | Streaming data is saved to S3. You can set up ad hoc SQL queries via the AWS Management Console, Athena runs them as serverless functions and returns results. |
| Amazon Redshift | Data warehouse | Amazon Kinesis Streaming Data Firehose can be used to save streaming data to Redshift. This enables near real-time analytics with BI tools and dashboards you have already integrated with Redshift. |
|
Text search | Kafka Connect can be used to stream topics directly into Elasticsearch. If you use the Avro data format and a schema registry, Elasticsearch mappings with correct data types are created automatically. You can then perform rapid text search or analytics within Elasticsearch. | |
|
Low latency serving of streaming events to apps | Kafka streams can be processed and persisted to a Cassandra cluster. You can implement another Kafka instance that receives a stream of changes from Cassandra and serves them to applications for real-time decision making. |
Streaming Data Storage
With the advent of low cost storage technologies, most organizations today are storing their streaming event data. Here are several options for storing streaming data, and their pros and cons.
| Streaming Data Storage Option | Pros | Cons |
| In a database or data warehouse – for example, PostgreSQL or Amazon Redshift | Easy SQL-based data analysis. | Hard to scale and manage. If cloud-based, storage is expensive. |
| In the message broker – for example, using Kafka persistent storage | Agile, no need to structure data into tables. Easy to set up, no additional components. | Data retention is an issue since Kafka storage is up to 10x more expensive compared to data lake storage. Kafka performance is best for reading recent (cached) data. |
| In a data lake – for example, Amazon S3 | Agile, no need to structure data into tables. Low cost storage. | High latency, makes real time analysis difficult. Difficult to perform SQL analytics. |
A data lake is the most flexible and inexpensive option for storing event data, but it is often very technically involved to build and maintain one. We’ve written before about the challenges of building a data lake and maintaining lake storage best practices, including the need to ensure exactly-once processing, partitioning the data, and enabling backfill with historical data. It’s easy to just dump all your data into object storage; creating an operational data lake can often be much more difficult.
SQLake’s data lake pipeline platform reduces time-to-value for data lake projects by automating stream ingestion, schema-on-read, and metadata extraction. SQLake automatically manages the orchestration of tasks, scales compute resources up and down, and optimizes the output data. This enables data consumers to easily prepare data for analytics tools and real time analysis. More about SQLake.
The Challenge of Streaming Data Analytics, and How Upsolver’s SQL-first Approach Works
Streaming data analytics is the process of extracting insights from data streams in real time or near-real time – i.e., while the data is still “in motion.” This requires transforming event streams into a tabular format, which can then be queried, visualized, and used to inform business processes. Examples might include monitoring app usage as it happens, or identifying and addressing website performance issues that affect online store transactions.
From what we’ve covered above, it’s easy to understand why running analytics on streaming data can be challenging:
- The nature of streaming data means that it is constantly changing and there is no “single version of the truth.” You need to define a window of time on which you run the analysis, capture all the events that occurred within that window (including ones that arrive late), and maintain a schema that will be consistent with the current data you’re analyzing as well as the future records. This can make it difficult to perform complex stateful transformations.
- The volume of data and the need to build distributed architectures using multiple tools – including code-intensive stream processing frameworks – adds a further layer of complication, as the ‘normal’ set of data analysis tools based on databases and SQL won’t work.
Some stream processors, including Spark and WSO2, provide a SQL syntax for querying and manipulating the data. But most operations still require complex code in Java or Scala when you want to move the exploratory analysis to production at scale. This creates a PipelineOps bottleneck.
With SQLake, you use only familiar SQL to perform real-time and micro-batch processing on batch and streaming data. Any data practitioners who know SQL can quickly build and deploy an always-on, self-orchestrating data pipeline themselves. This relieves the data engineering bottleneck, as they no longer must depend on engineering’s schedule. Additionally, SQLake’s automated best practices ensure that data engineers don’t need to spend months rewriting and managing the pipelines in production, further relieving their burden.
Learn about our approach to streaming SQL.
How to Approach Modern Streaming Architecture
In modern streaming data deployments, many organizations are adopting a full stack approach rather than relying on patching together open-source technologies. The modern data platform is built on business-centric value chains rather than IT-centric coding processes, wherein the complexity of traditional architecture is abstracted into a single self-service platform that turns event streams into analytics-ready data.
The idea behind Upsolver SQLake is to automate the labor-intensive parts of working with streaming data: message ingestion, batch and streaming ETL, storage management, and preparing data for analytics.
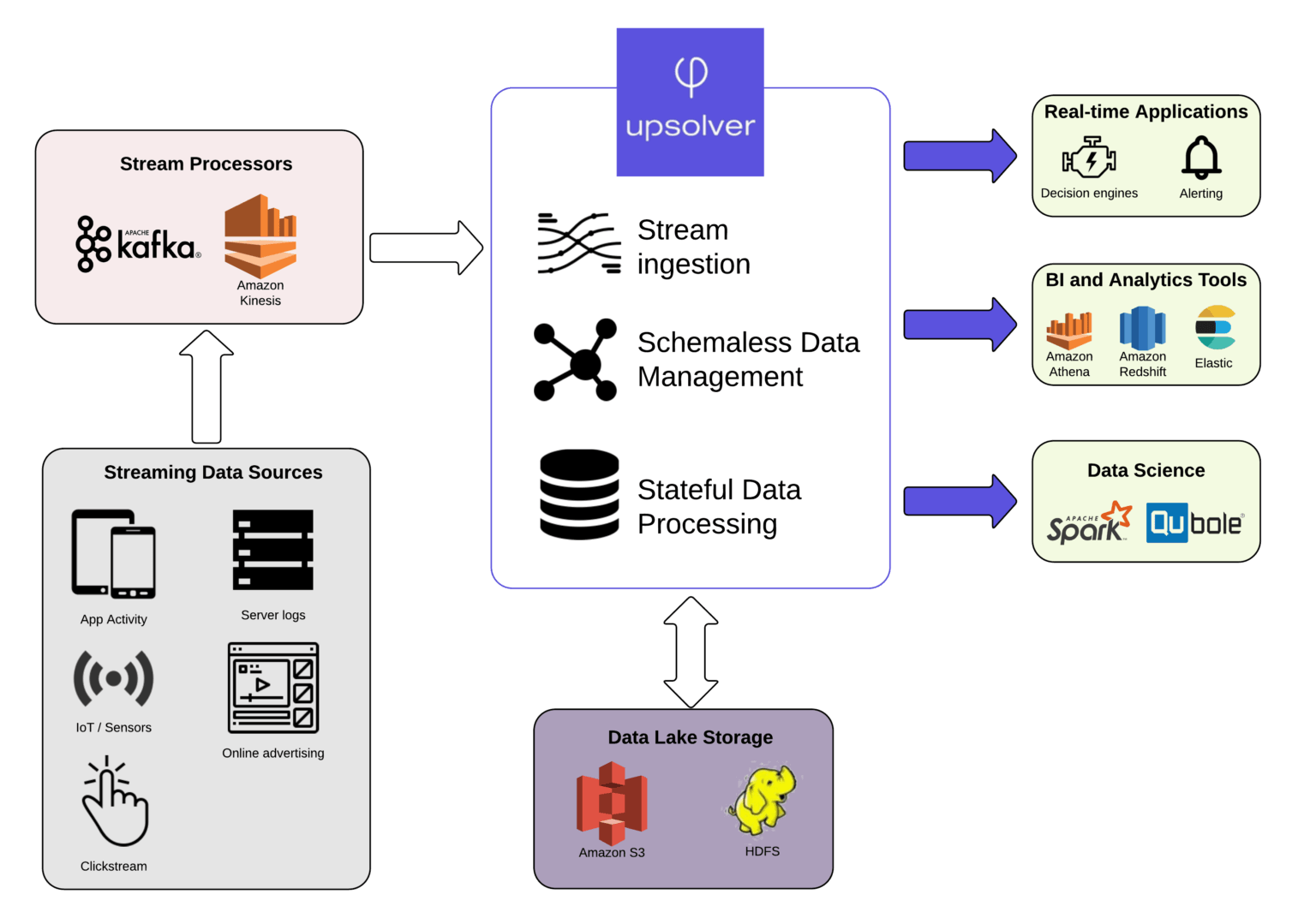
Benefits of a modern streaming architecture:
- Can eliminate the need for large data engineering projects
- Performance, high availability, and fault tolerance built in
- Newer platforms are cloud-based and can be deployed very quickly with no upfront investment
- Flexibility and support for multiple use cases
Here’s how you would use SQLake to join batch and streaming data for analysis in Snowflake.
Examples of modern streaming architectures on AWS
Since most of our customers work with streaming data, we encounter many different streaming use cases, mostly around operationalizing Kafka/Kinesis streams in the Amazon cloud. Below you will find some case studies and reference architectures that can help you understand how organizations in various industries design their streaming architectures:
Analyzing 70bn product logs at Sisense
Sisense is a late-stage SaaS startup and one of the leading providers of business analytics software. It was seeking to improve its ability to analyze internal metrics derived from product usage – over 70bn events and growing.
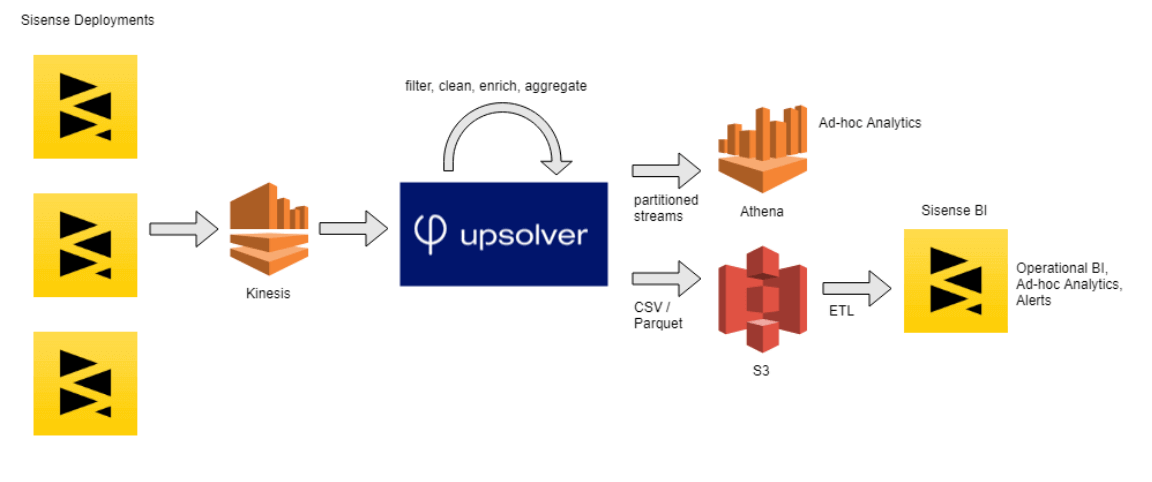
Read the full case study here.
Real-time machine learning at Bigabid
Bigabid develops a programmatic advertising solution built on predictive algorithms. By implementing a modern real-time data architecture, the company was able to improve its modeling accuracy by a scale of 200x over one year
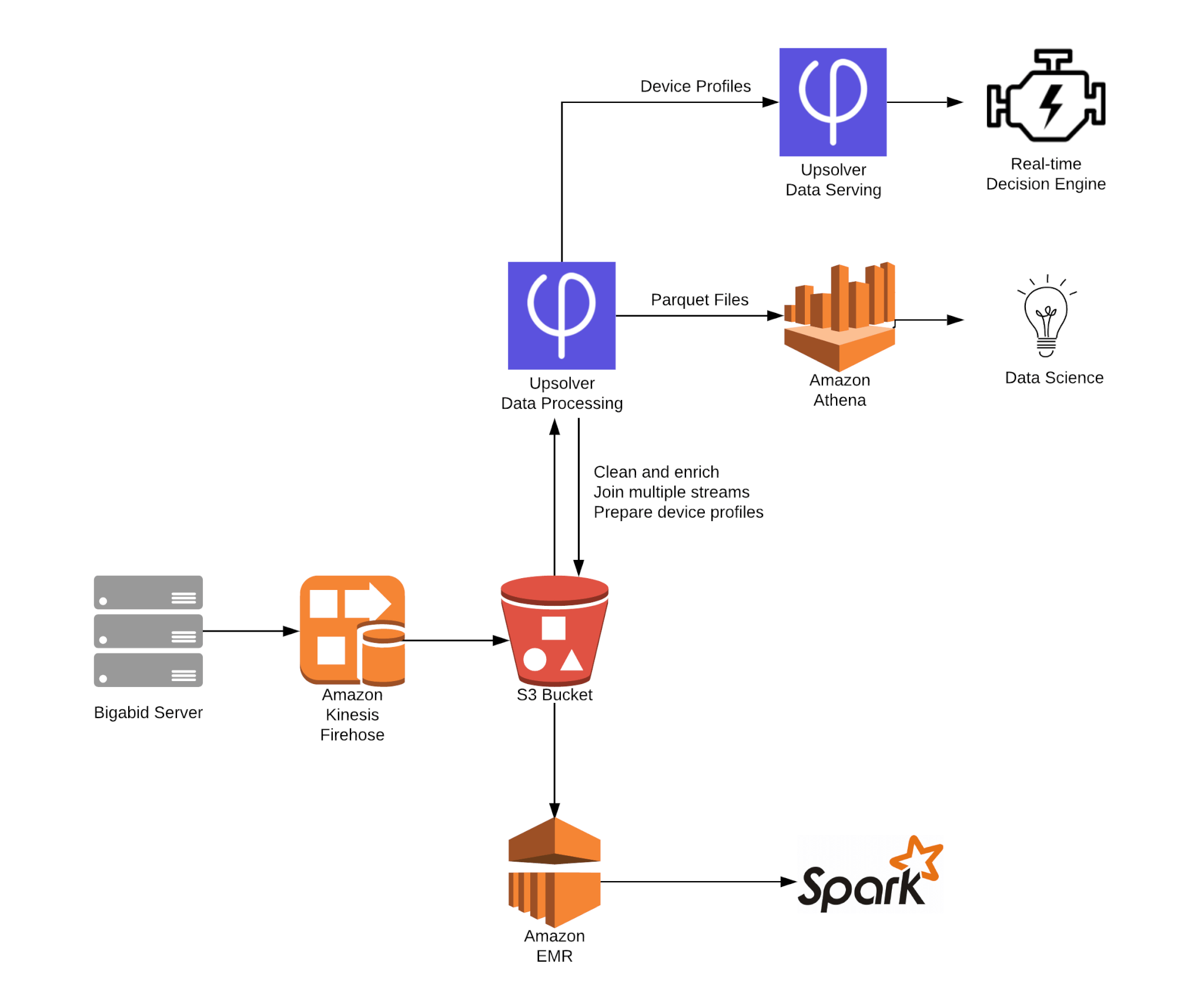
Read the full case study on the AWS website.
Multi-purpose data lake at ironSource
IronSource is a leading in-app monetization and video advertising platform. In a recent case study published on the AWS blog, we describe how the company built a versatile data lake architecture capable of handling petabyte-scale streaming data.
Read the full case study on the AWS blog.
Transitioning from data warehouse to data lake at Meta Networks
Learn how Meta Networks (acquired by Proofpoint) achieved several operational benefits by moving its streaming architecture from a data warehouse to a cloud data lake on AWS.
Read the full case study here.
Upsolver SQLake: The Future of Streaming Data
SQLake is Upsolver’s newest offering. SQLake enables you to build reliable data pipelines on batch and streaming data using only SQL. Define your processing pipelines in just a few simple steps:
- Connect to a data source.
- Ingest data from that source using a copy process into a staging zone, effectively staging that raw data in a managed S3 bucket.
- Transform the data, using only SQL.
- Create an output table and write the transformed data into the output table, which you can query using SQLake’s built-in Amazon Athena integration. (You can also use Athena to inspect staged data while your job is in progress.)
SQLake enables you to build reliable, maintainable, and testable processing pipelines on batch and streaming data via an all-SQL experience. With SQLake you can:
- Lower the barrier to entry by developing pipelines and transformations using familiar SQL.
- Improve reusability and reliability by managing pipelines as code.
- Integrate pipeline development, testing, and deployment with existing CI/CD tools using a CLI.
- Eliminate complex scheduling and orchestration with always-on, automated data pipelines.
- Improve query performance with automated data lake management and optimization.
You can try SQLake for free for 30 days. No credit card is required.
Want to learn more about streaming data analytics and architecture?
Get our Ultimate Guide to Streaming Data:
- Get an overview of common options for building an infrastructure.
- See how to turn event streams into analytics-ready data.
- Cut through some of the noise of all the “shiny new objects.”
- Come away with concrete ideas for wringing all you want from your data streams.
Get the full eBook right here, for free.
Addendum: Questions to Ask About Your Streaming Data Platform
Since we first published this post a few years ago, we’ve encountered a lot of questions about how to approach streaming analytics from a data platform perspective. While data pipeline architecture is a complex topic, here are a few questions you might want to ask when deciding how to build or buy a streaming platform:
- Will it require custom coding in languages such as Java or Scala? How will that affect other engineering work in your organization? Will it create tech debt?
- How close to real time does your data need to be? Sub-second, minutes, hours, days?
- How much are you willing to invest in cloud infrastructure, considering that volumes of streaming data tend to grow very quickly?
- What levels of data retention do you require?
- How complex is your data? Do you have nested fields and arrays in your data?
- How frequently will your data change?
- Do you need to reprocess data to “update history” when there is change to the data or transformation logic,change?
- Are you using or considering a data mesh topology or productizing output data sets for shared use?
Published in:
Blog
,
Streaming Data