
Explore our expert-made templates & start with the right one for you.
Yes, You Should Use SQL for Streaming Data. Learn How
-
 Jerry Franklin
Jerry Franklin
- Streaming Data
- September 16, 2021
Many businesses think that moving from batch to streaming analytics will require completely overhauling their tooling and skillset – but this doesn’t have to be the case. Learn why building your analytics infrastructure in a SQL-first approach is viable, even if you’re working with complex and streaming data.
The underlying processes for querying and deriving value from streaming data at scale are complex. But it’s not necessary to resort to arcane coding expertise or monolithic proprietary platforms to perform streaming analytics. SQL gets it done, too.
Why Use SQL To Analyze Streaming Data?
Code is powerful. It’s also complex, time-consuming, and out of the reach of most data practitioners. SQL of course is the standard for querying batch data that resides in databases. But in fact it also enables you to perform complex transformations on streaming data. And using SQL not only saves experienced developers and engineers substantial time and effort. The familiar syntax of SQL also provides data access to analysts and other data professionals who aren’t engineers. New team members can develop pipelines and complex queries without needing R&D resources.
That said, there is an important distinction to keep in mind.
Using SQL for streaming data vs. using SQL in a traditional database
You still use SQL to define what you’re doing. But it’s not the traditional one-off query. The execution model is different. When you’re doing joins and aggregations, you must define the dataset you’re joining with or aggregating on. To do this, you need a window.
(The WINDOW keyword is a simple and elegant way to analyze streamed data in near-real-time. Events found in a data stream are discretized into groups of events, known as Windows. In data streaming, just as with batch data, you set a window and a function; the function evaluates itself according to the data available in the window you’ve set.
Batch data SQL statements usually don’t require a window; they process everything. With streaming data, there’s no such thing as “everything.” For aggregations and joins you must specify a window of data to process. For instance, you can use the SQL keyword WINDOW and enter 10 days to get a 10-day sliding window; your SQL query processes all the data within that 10-day window. (Windows generally aren’t necessary to process simpler transformations – data that does not refer either to previous events, such as aggregations, or to events from other streams, such as joins.) The window slides forward each minute, and Upsolver SQLake processes only the new minute of data, referring to the specified 10-day window as needed. (Batch processors process the full 10 days of data, but only periodically – typically once a day.)
Nor must your data be in a database for you to be able to use SQL to query it. You can use a range of data stores – cloud data warehouses, data lakes, and so on, or stream in from a range of producers. This enables scale, as databases can quickly become inefficient and expensive with streams.
More on using the WINDOW keyword.
Choices for Using SQL for Streaming Analytics
If you’re reading this, you’re probably seeking an alternative to a pure code (Spark, Scala, Python, and so on) approach to streaming analytics. There are multiple choices.
- Some stream processors, including Spark and WSO2, provide a SQL syntax for querying and manipulating the data. But most operations still require complex code to write code in Java or Scala. The way you define what you want to get is using SQL, but there’s still some R and D involved. Learn more about Spark and alternative tools.
- Frameworks such as Spark Streaming also actually process data in micro-batches rather than in continuous streams.
- More “pure-play” stream processing tools such as Confluent’s kSQL or Apache Flink read data from a Kafka or Kinesis stream. But while they simplify the process of SQL analytics, they also still involve some engineering. They also do not perform updates, making them unsuitable on their own for CDC.
- A platform such as Upsolver SQLake automates a range of allied processes (such as pipeline orchestration and query optimization) to make working with SQL more powerful.
You also must consider orchestration. While tools to address this issue exist – Apache Airflow is a common choice – getting the data to the right place at the right time, while ensuring exactly-once processing , with zero or near-zero latency, still requires substantial resources to design, code, and test.
Important aspects to keep in mind when using SQL with streaming data:
It’s important to keep the following in mind you’re working in a streaming context; otherwise you can get unexpected results: What’s the desired window? Do you update a table? Append a table? When, and how often? Data may be streaming in by the megabyte per second, but you’re still dealing with one event at a time.
SQLake’s Approach to Streaming Analytics with SQL
As with other streaming SQL tools, SQLake includes some special keywords to use to define streaming data analytics.
You perform all your streaming analytics in SQL. Create joins between streams, or between a stream and historical big data; the enriched stream continuously queries your data sources and returns accurate data in near real-time. You never need to update the query.
Setting itself apart, SQLake also automates all of the orchestration, as well as a range of best practices for optimizing data for querying (compression, compaction, columnar formats, indexing metadata, and so on). This all occurs under the hood.
Performing SQL Analytics in SQLake
SQLake uses a familiar SQL syntax. It includes extensions for streaming data use cases such as time-based joins and window functions.
Defaults are designed to account for most discrepancies you might typically encounter or overlook. For joins, for example, in SQLake you can specify a join after 10 minutes, so you could do a join between two streams even if the event you’re joining with happens after the join has executed – click data, for instance, which usually arrives later than impressions.
For aggregated outputs SQLake upserts by default. In practice, the value in the destination table is replaced with the new value, whenever it gets updated. That simulates the results of what would happen if you were to query a traditional table with the same query – that is, you get one up-to-date value instead of many smaller incremental values.
Here are a few examples of what SQlake enables you to do with SQL:
- Ingest raw data structures such as user activity, IoT and sensor data, application activity data, or online advertisements statistics, and filter those data structures for just the required data. In the below example, we’re querying for the device type people used when making online purchases; we filtered for Web sales so as not to include sales from physical stores:
SET partition_date = UNIX_EPOCH_TO_DATE(time);
SET deviceType = USER_AGENT_PARSER('Device Type', data.saleInfo.web.userAgent);
// GENERATED @ 2021-05-26T21:59:21.180765Z
SELECT PARTITION_TIME(partition_date) AS partition_date:TIMESTAMP,
time AS processing_time:TIMESTAMP,
data.customer.address.city AS customer_city:STRING,
deviceType AS devicetype:STRING
FROM "orders_data_raw"
WHERE data.saleInfo.source='Web'
- Join data from several sources, such as combining data from your streaming data source with data arriving in other streams, historical aggregations, or reference data files by using the JOIN syntax. The result is a new table that is populated with the column values you specify in the SELECT statement.
- Perform calculations and conversions to improve and enrich data as it streams in. SQLake contains all common SQL functions as built-in functions, and includes special enrichment functions (for example, IP2GEO, user agent parser). You can also add your own User Defined Functions (UDFs) in Python.
SQLake also handles nested objects and arrays automatically.
By way of a detailed example, here’s a blog that details the process for using SQLake to join streaming Web impressions and streaming clicks to compare the performance of digital ad campaigns. If you sign up for SQLake (sign up for free — no credit card required) you may be able to follow along by using one of the many customizable SQL templates that SQLake makes available.
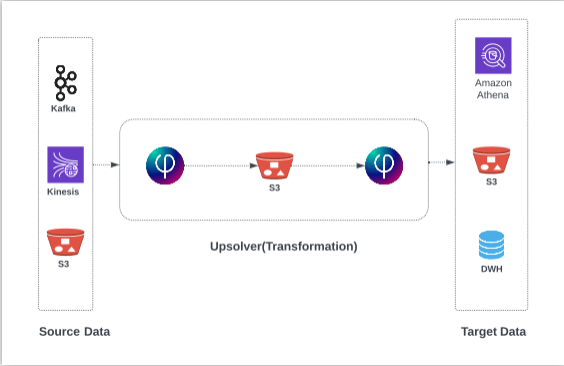
Summary: SQL-First Approach to Streaming Analytics
SQL is the standard for querying batch data in databases. But SQL increasingly is being used for real-time transformations and queries of streaming data, as well. There are considerations to keep in mind – query execution model differs in a streaming context, and the data need not reside in a database. SQL-based tools exist specifically to help you work with streaming data, though they often still require some manual coding or specialized engineering. But automated platforms such as SQLake can also help significantly with the transition from batch to streaming analytics, without requiring anything beyond SQL expertise.
More Information About Upsolver SQLake
There’s much more information about the SQLake declarative data pipeline platform, including how it automates a full range of data best practices, real-world stories of successful implementation, and more, at www.upsolver.com.
- More details on how you can improve Athena performance.
- More details on batch and streaming ETL using SQL and streaming data architecture.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
- Try SQLake for free. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Streaming Data