
Explore our expert-made templates & start with the right one for you.
Apache Kafka with and without a Data Lake
-
 Eran Levy
Eran Levy
- Data Lakes
- November 16, 2021
Apache Kafka is a cornerstone of many streaming data projects. However, it is only the first step in the potentially long and arduous process of transforming streams into workable, structured data. How should you design the rest of your data architecture to build a scalable, cost effective solution for working with Kafka data? Let’s look at two approaches – reading directly from Kafka vs creating a data lake – and understand when and how you should use each.
The following article is a summary of a recent talk by Upsolver’s CTO Yoni Eini. You can check out the slides below or keep reading for the full version.
Kafka: The Basics
Let’s start with an (extremely) brief explanation of how Apache Kafka works. You can get the full overview of Kafka here.
Apache Kafka is open-source software used to process real-time data streams, designed as a distributed transaction log. Streams can be produced by any number of tools or processes, with each record consisting of a key, a value and a timestamp. Records are stored chronologically in partitions, which are then grouped into topics. These can be read by various consumer groups:
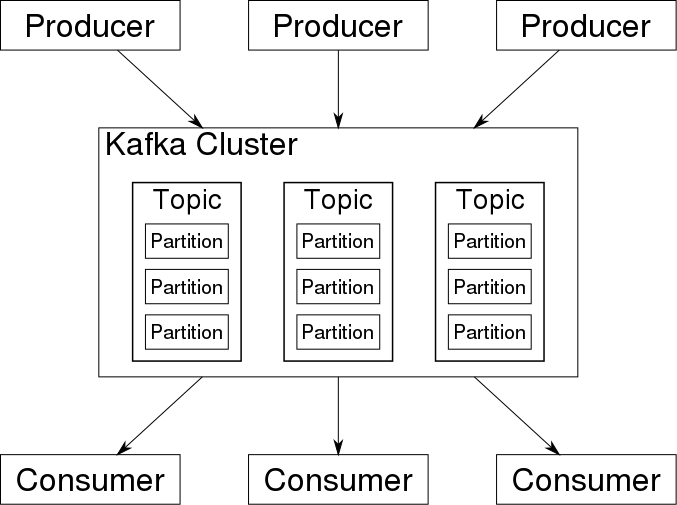
Source: Wikimedia Commons
Kafka provides a robust, reliable and highly scalable solution for processing and queueing streaming data, and is probably the most common building block used in streaming architectures.
But what do you do once you have data in Kafka, and how do you get it into a form that developers and data analysts can actually work with? In the next part of this article, we’ll explain why the answer to that question, in most cases, is to build a data lake.
Why not read directly from Kafka?
A lot of organizations look at the neatly partitioned data going into their Kafka clusters and are tempted to just read that data directly. While this might sound like an easy fix with minimal data plumbing, it also has major drawbacks that all stem from the fact that Kafka is a system that is highly optimized for writing and reading fresh data.
This means that:
Producing is easy…
- Unlimited writes: Kafka stores events on one large file on disk, and that file is appended sequentially as new events are processed. This system enables it to achieve truly incredible feats such as completing two million writes per second on three cheap machines.
- High reliability: Even without too much tweaking, Kafka is highly fault-tolerant and writes just work – you don’t need to worry about losing relevant events.
- Strong ordering within a partition: Data is ordered sequentially; if two consumers read the same partition, they will both read the data in the same order. This means that multiple, unrelated consumers will see the same ‘reality’ – which can be extremely important in some cases (e.g. when assigning workloads).
- Exactly-once writing: Kafka 0.11 introduced exactly-once writing, which is very handy as a means of reducing efforts on the consumer side.
…but consuming is hard (and expensive!)
- Retention is 10X-100X more expensive than when using cloud storage: Storing historical data on Kafka clusters can quickly drain your IT budget. Kafka stores multiple copies of each message on expensive hard drives connected to servers. Both of these factors contribute to at least 10x the bottom line compared to storing the data on a data lake such as Amazon S3.
- Risk to production environments: Reading from Kafka in production is not great: every additional consumer drains resources and slows performance, while reading “cold” data will likely cause cache misses.
- Waste of compute resources: Kafka consumers read an entire record to access a specific field, whereas columnar storage on a data lake (e.g. Apache Parquet) will allow you to directly access specific fields.
- Data quality effort per consumer: Each Kafka consumer works in a vacuum, which means data governance is an issue that needs to be multiplied by the amount of consumers – which in turn means repetitive deduplication, schema management, and monitoring processes; a data lake allows you to unify these operations on a single repository.
The Solution: Build a Data Lake
We’ve explained why reading data directly from Kafka is messy, expensive and time-consuming. Most of these problems can be solved by introducing a data lake as an intermediary stage between your Kafka and the systems you use to analyze data. This approach is advantageous as it allows you to:
- Leverage cheap storage on S3, allowing you to significantly increase retention without paying through the nose for storage.
- Introduce new use cases without worrying about Kafka performance and stability: a data lake enables flexibility to introduce new consumers and applications, without slowing down your production environment.
- Ensure data quality and governance by working on a single repository rather than individual topics.

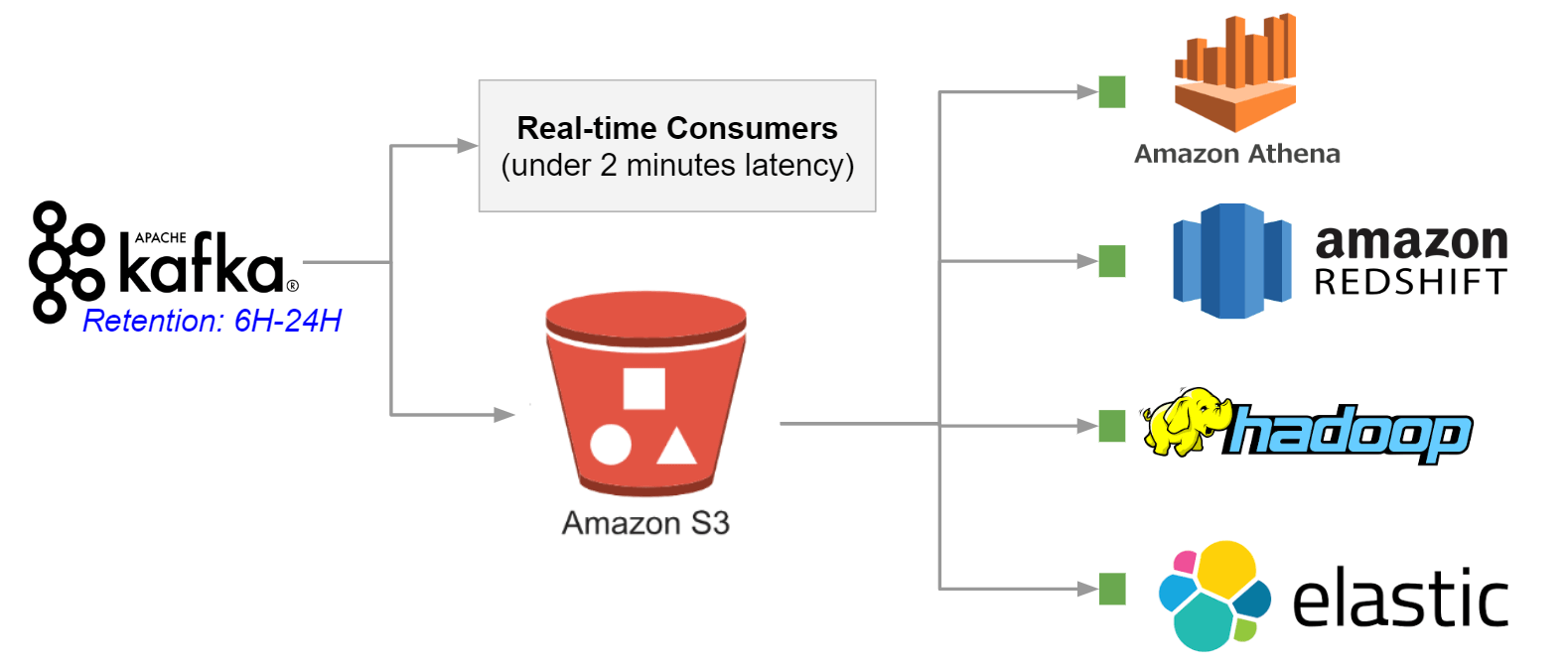
Here’s what this would look like in an AWS environment:
Apache Kafka + Data Lake Reference Architecture
The Real-time Caveat
You might have noticed a “Real-time Consumers” block in the diagram above, although we recommended reading data from a data lake and not directly Kafka. What’s going on?! Have we been lying to you this entire time?
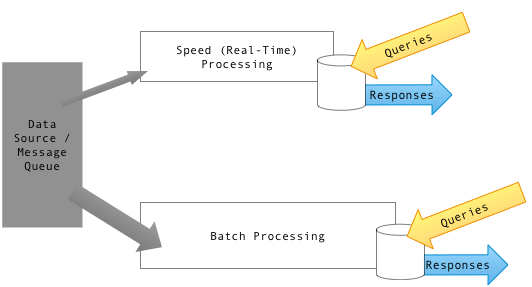
We haven’t but there is an important caveat, which is that the data lake architecture will not work for use cases that require an end-to-end latency of seconds. In such cases, for example as part of a fraud detection engine, you would need to implement an additional Kafka consumer that would only process real-time data (last few minutes) and merge the results with the results of a data lake process. This architectural pattern is named Lambda Architecture:
Next Step: Building Your Data Lake
Given the significant technical hurdles inherent in reading data directly from Kafka, using a data lake to store raw events makes sense. To manage this raw Kafka data and make it useful, establish an ETL pipeline to extract the data from Kafka or a staging environment, transform it into structured data, and then load it into the database or analytics tool of choice.
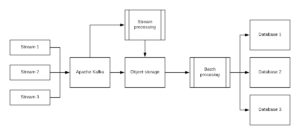
This approach:
- provides inexpensive, infinitely scalable storage
- makes historical data available for replay purposes
- can support a broad range of use cases, including real-time
That said, ETL pipelines for Apache Kafka can be challenging. In addition to the basic task of transforming the data, you also must account for the unique characteristics of event stream data. More details on the process.
Using Upsolver to Build a Data Lake with Apache Kafka
Upsolver’s self-service streaming data platform sharply reduces the time to build pipelines and place them into production. A visual interface synced to declarative SQL commands enables you to build pipelines without knowledge of programming languages such as Scala or Python. Upsolver also automates the “ugly plumbing” of table management and optimization, saving you substantial amounts of data engineering hours.
With just a finite number of clicks in the Upsolver UI, you can create a Kafka data source and output it into a data store or query engine. Setting up a data source subscribes Upsolver to the topic you specify in the Kafka cluster.
Here’s an example involving ingesting data from Kafka and outputting it to Amazon S3. Detailed steps are here. In summarized form, here’s all you need to do:
Select a new source:
- From the Data Sources page select a new source and then specify Kafka.
- Enter in the host:port for your Kafka cluster.
- If there are multiple hosts, the format should be host1:port1, host2:port2, …
- Select the Kafka topic to read from.
- Name this data source and click Continue.
- When the S3 Bucket Integration window displays, click Launch Integration. The AWS CloudFormation page displays in a new tab.
- Check the I acknowledge statement and click Create Stack.
When you create the data source, Upsolver displays 100 recent records from the topic as a preview. This enables you to check yourself and make any desired adjustments before you run your query.
Tip When the stack is created with the required resources, the message in Upsolver stops displaying. You can now use your Kafka topic data source.
Of course, quite often your needs may not be quite this straightforward. In these cases you can display advanced options right after you specify Kafka as a new data source. These advanced options enable you to customize the data source by selecting:
- a specific compute cluster
- a target storage option
- retention options
You can also configure settings for:
- Kafka Consumer Properties
- Shards
- Execution Parallelism
- Real Time Statistics
- Use SSL
- End Read At
- Store Raw Data
- Compression
After you make these configurations and review sample data, simply click Create to begin using your Kafka data source.
Note By default the data in a data source is kept in Upsolver forever. If you specify a retention period in Upsolver (for example, 30 days), this only applies to the data source.
If you create an output based on this data source, it has its own retention, and these do not need to match (for example, you can configure the output to retain data for a year).
Best Practices for Cloud Data Lakes
There are a lot of best practices it’s valuable to follow when creating your data lake, on S3 or elsewhere. You can see a quick summary of them in the last few slides above. If you’re still not sure how to approach building your data lake, check out our Guide to Self Service Data Lakes in the Cloud.
Try SQLake for free (early access)
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes
