
Explore our expert-made templates & start with the right one for you.
7 Popular Stream Processing Frameworks Compared
-
 Eran Levy
Eran Levy
- Streaming Data
- March 21, 2019
If you want to learn more about designing efficient streaming data architecture, we recommend checking out our comprehensive eBook, “Streaming Data and Data Lakes: Architecture and Best Practices.” This article is just an excerpt from the eBook, and by downloading the full version for free, you’ll gain access to a wealth of additional information, including detailed tool comparisons, real-world case studies, and much more. Don’t miss out on this opportunity to deepen your knowledge and improve your data processing strategies – download the eBook now!
Stream processing is a critical part of the big data stack in data-intensive organizations. Tools like Apache Storm and Samza have been around for years, and are joined by newcomers like Apache Flink and managed services like Amazon Kinesis Streams.
Today, there are many fully managed frameworks to choose from that all set up an end-to-end streaming data pipeline in the cloud. Making sense of the relevant terms so you can select a suitable framework is often challenging. This guide will shed light on this topic and help you navigate the landscape with ease.
What Are Big Data Stream Processing Frameworks?
Developers use stream processing to query continuous data streams and react to important events, within a short timeframe ranking from milliseconds to minutes.
Stream processing is closely related to real time analytics, complex event processing, and streaming analytics. Today stream processing is the primary framework used to implement all these use cases. Stream processing engines are runtime libraries which help developers write code to process streaming data, without dealing with lower level streaming mechanics.
Struggling with the complexity of open-source frameworks? Skip the lengthy coding in Scala/Java and start writing end-to-end batch and streaming ETL pipelines using nothing but the SQL you already know. Check out our technical white paper to learn how the magic happens. Or get a live demo of our newest offering, Upsolver SQLake, to see how the magic happens.
Types of Stream Processing Engines
There are three major types of processing engines.
Open Source Compositional Engines
In a compositional stream processing engines, developers define the Directed Acyclic Graph (DAG) in advance and then process the data. This may simplify code, but also means developers need to plan their data stream architecture carefully to avoid inefficient processing.
Challenges: Compositional stream processing are considered the “first generation” of stream processing and can be complex and difficult to manage.
Examples: Compositional engines include Samza, Apex, and Apache Storm.
Managed Declarative Engines
Developers use declarative engines to chain stream processing functions. The engine calculates the DAG as it ingests the data. Developers can specify the DAG explicitly in their code, and the engine optimizes it on the fly.
Challenges: While declarative engines are easier to manage, and have readily-available managed service options, they still require major investments in data engineering to set up the data pipeline, from source to eventual storage and analysis.
Examples: Declarative engines include Apache Spark Streaming and Flink, both of which are provided as a managed offering.
Fully Managed Self-Service Engines
A new category of stream processing engines is emerging, which not only manages the DAG but offers an end-to-end solution including ingestion of streaming data into storage infrastructure, organizing the data, and facilitating streaming analytics.
Examples: Upsolver SQLake is a fully managed declarative data pipeline platform for streaming and batch data. SQLake handles huge volumes of streaming data, stores it in a high-performance cloud data lake architecture, and enables real-time access to data and SQL-based analytics. Learn more from our architecture overview. And see some of the ways you can use SQLake to build declarative, self-orchestrating end-to-end data pipelines.

Comparing Popular Stream Processing Frameworks
Apache Spark
Spark is an open-source distributed general-purpose cluster computing framework. Spark’s in-memory data processing engine conducts analytics, ETL, machine learning and graph processing on data in motion or at rest. It offers high-level APIs for the programming languages: Python, Java, Scala, R, and SQL.
The Apache Spark Architecture is founded on Resilient Distributed Datasets (RDDs). These are distributed immutable tables of data, which are split up and allocated to workers. The worker executors implement the data. The RDD is immutable, so the worker nodes cannot make alterations; they process information and output results.
Pros: Apache Spark is a mature product with a large community, proven in production for many use cases, and readily supports SQL querying.
Cons:
- Spark can be complex to set up and implement
- It is not a true streaming engine (it performs very fast batch processing)
- Limited language support
- Latency of a few seconds, which eliminates some real-time analytics use cases
Apache Storm
Apache Storm has very low latency and is suitable for near real time processing workloads. It processes large quantities of data and provides results with lower latency than most other solutions.
The Apache Storm Architecture is founded on spouts and bolts. Spouts are origins of information and transfer information to one or more bolts. This information is linked to other bolts, and the entire topology forms a DAG. Developers define how the spouts and bolts are connected.
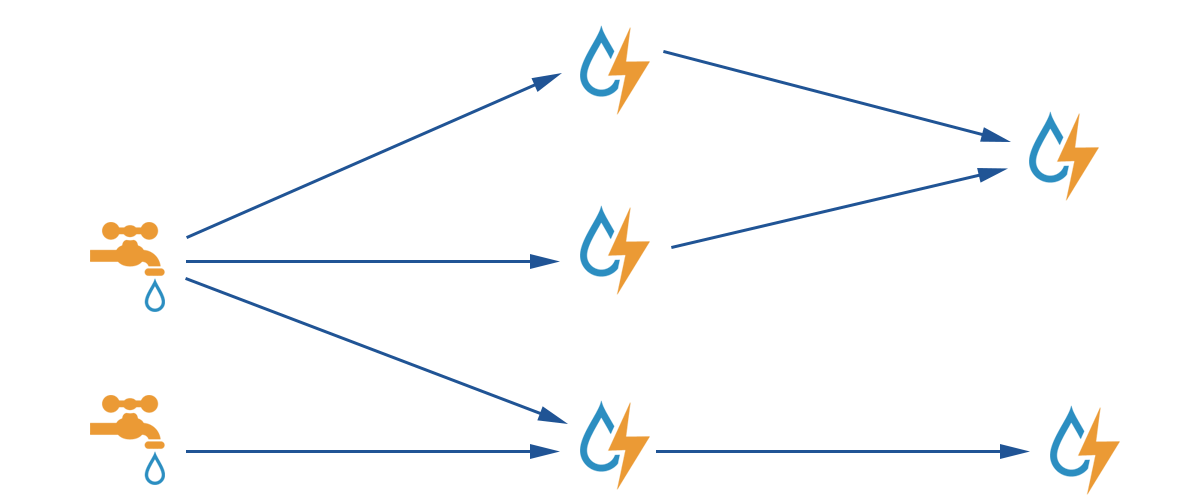
Source: Apache Storm
Pros:
- Probably the best technical solution for true real-time processing
- Use of micro-batches provides flexibility in adapting the tool for different use cases
- Very wide language support
Cons:
- Does not guarantee ordering of messages, may compromise reliability
- Highly complex to implement
Apache Samza
Apache Samza uses a publish/subscribe task, which observes the data stream, processes messages, and outputs its findings to another stream. Samza can divide a stream into multiple partitions and spawn a replica of the task for every partition.
Apache Samza uses the Apache Kafka messaging system, architecture, and guarantees, to offer buffering, fault tolerance, and state storage. Samza relies on YARN for resource negotiation. However, a Hadoop cluster is needed (at least HDFS and YARN).
Samza has a callback-based process message API. It works with YARN to provide fault tolerance, and migrates your tasks to another machine if a machine in the cluster fails. Smaza processes messages in the order they were written and ensures that no message is lost. It is also scalable as it is partitioned and distributed at all levels.
Pros:
- Offers replicated storage that provides reliable persistency with low latency.
- Easy and inexpensive multi-subscriber model
- Can eliminate backpressure, allowing data to be persisted and processed later
Cons:
- Only supports JVM languages
- Does not support very low latency
- Does not support exactly-once semantics
Apache Flink
Flink is based on the concept of streams and transformations. Data comes into the system via a source and leaves via a sink. To produce a Flink job Apache Maven is used. Maven has a skeleton project where the packing requirements and dependencies are ready, so the developer can add custom code.
Apache Flink is a stream processing framework that also handles batch tasks. Flink approaches batches as data streams with finite boundaries.
Pros:
- Stream-first approach offers low latency, high throughput
- Real entry-by-entry processing
- Does not require manual optimization and adjustment to data it processes
- Dynamically analyzes and optimizes tasks
Cons:
- Some scaling limitations
- A relatively new project with less production deployments than other frameworks
Amazon Kinesis Streams
Amazon Kinesis Streams is a durable and scalable real time service. It can collect gigabytes of data per seconds from hundreds of thousands of sources, including database event streams, website clickstreams, financial transactions, IT logs, social media feeds, and location-tracking events. The data captured is provided in milliseconds for real time analytics use cases, including real time anomaly detection, real time dashboards, and dynamic pricing.
You can build data-processing applications, called Kinesis Data Stream (KDS) applications. Typically, a kinesis data stream application interprets data from a data stream as data records. The application can run on Amazon EC2 and can use the kinesis client library.
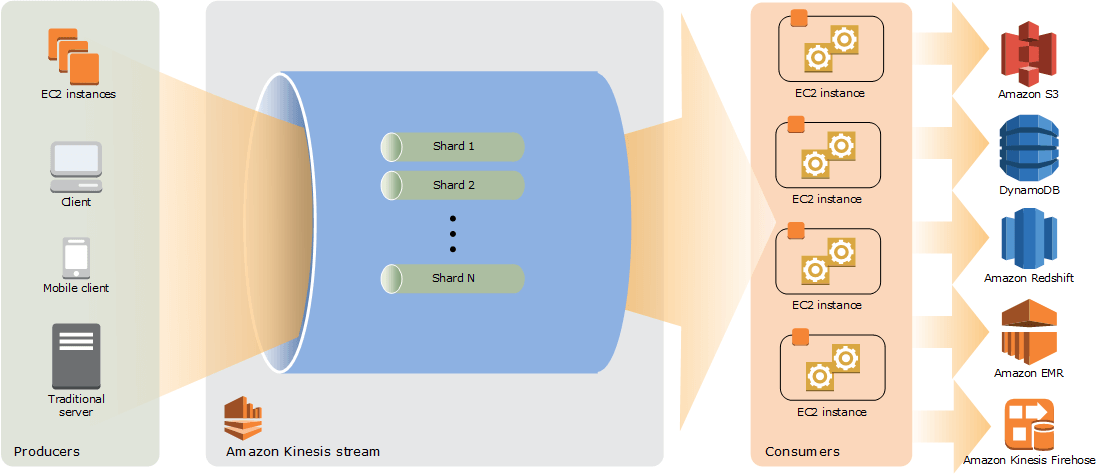
Source: Amazon
Pros:
- A robust managed service that is easy to set up and maintain
- Integrates with Amazon’s extensive big data toolset
Cons:
- Commercial cloud service, priced per hour per shard (see pricing)
Apache Apex
Apex offers a platform for batch and stream processing using Hadoop’s data-in-motion architecture by YARN. The platform provides integration with different data platforms. Apex also provides a framework that is easy to use.
Operationally, Apex utilizes native HDFS for persisting state and the YARN features found in Hadoop such as scheduling, resource management, jobs, security, multi-tenancy, and fault-tolerance. Functionally, developers can integrate Apex APIs with other data processing systems.
Apex allows for high throughput, low latency, reliability, and unified architecture, for batch and streaming use cases. It can process unbound data sets, which can grow infinitely.
Pros:
- Design focuses on enterprise readiness
- Strong processing guarantees (end-to-end exactly once)
- Highly scalable, high throughput with low latency
- Secure, supports fault-tolerance and multi-tenancy
Cons:
- Apex is no longer widely used and no vendor is currently supporting this framework at scale (see article)
- Limited support for SQL
- Difficult to find skilled users
Apache Flume
Flume is a reliable, distributed service for aggregating, collecting and moving massive amounts of log data. It has a flexible and basic architecture. It is fault-tolerant and hardy with failover and recovery features and tunable reliability. It operates an extensible data model that allows for online analytic application.
The key concept behind the design of Flume is to capture streaming data from web servers to Hadoop Distributed File System (HDFS).
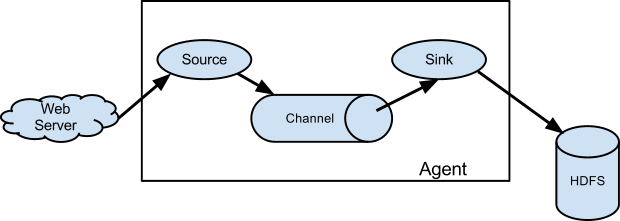
Source: https://flume.apache.org/FlumeUserGuide.html
Pros:
- Central master server controls all nodes
- Fault tolerance, failover and advanced recovery and reliability features
Cons:
- Difficult to understand and configure with complex logical/physical mapping
- Big footprint, over 50,000 lines of Java code
Want to learn more about streaming data analytics and architecture? Get our Ultimate Guide to Streaming Data:
- Get an overview of common options for building an infrastructure
- See how to turn event streams into analytics-ready data
- Cut through some of the noise of all the “shiny new objects”
- Come away with concrete ideas for wringing all you want from your data streams.
Get the full eBook right here, for free
Do it Yourself or End to End Stream Platforms?
There are many excellent options for building stream processing pipelines, but all of them require expertise and hard work to create an end-to-end solution. Managed streaming platforms such as SQLake provide an alternative to Spark. SQLake can ingest and process streaming data 10-100X faster than Apache Spark. SQLake also easily scales to millions of events per second with complex stateful transformations such as joins, aggregations, and upserts.
Try SQLake for free for 30 days. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
See how you can spin up an end-to-end streaming data pipeline in minutes, while supporting compelling use cases such as persisting events to a data lake or performing clickstream analysis.
Request a free consultation with Upsolver’s streaming data experts
Published in:
Blog
,
Streaming Data