
Explore our expert-made templates & start with the right one for you.
8 Best Practices for High Performance Data Lakes
-
 Eran Levy
Eran Levy
- Data Lakes
- February 19, 2022
This article covers best practices in data lake design. Another key element for analytics performance is data pipeline architecture, which is a topic we’ve covered in great depth in our recent webinar with Amazon Web Services and ironSource: Data Lake ETL for Petabyte-scale Streaming Data. Read on to get the 8 essential best practices, or watch the webinar for free here.
Research by the Aberdeen group has shown that data lakes have the potential to significantly improve performance (PDF). However, before plunging into the lake, it’s important to be aware of the best practices that can make the difference between a performant data architecture that generates tangible value for the business, and a data swamp that nobody really knows what to do with.
In this article, we’ll present eight key best practices you should adhere to when designing, implementing and operationalizing your data lake. These are things that will mostly be automatically implemented if you’re using Upsolver, but if you’re building your data lake ‘manually’ you’ll need to ensure they’re done correctly if you want to get the most value out of your data lake architecture.
While we will mostly be referring to Amazon S3 as the storage layer, these best practices would also apply for a data lake built on a different cloud or using Hadoop on-premise.
What makes a good data lake?
To deliver value to both technical and business teams, a data lake needs to serve as a centralized repository for both structured and unstructured data, while allowing data consumers to pull data from relevant sources to support various analytic use cases. This can be achieved if data is ingested, stored, and managed according to the best practices we cover below.
1. Data ingestion can get tricky – think about it early
Data lake ingestion is the process of collecting or absorbing data into object storage. In a data lake architecture, ingestion is simpler than in a data warehouse because data lakes allow you to store semi-structured data in its native format.
However, data ingestion is still important, and you should think about it early. This is because if you don’t store your data properly, it can be difficult to access later on. Additionally, proper data ingestion can help address functional challenges such as optimizing storage for analytic performance and ensuring exactly-once processing of streaming event data. Some of these best practices are covered further in this article, and the rest can be found in our previous blog on data lake ingestion.
2. Make multiple copies of the data
One of the main reasons to adopt a data lake in the first place is the ability to store massive amounts of data with a relatively low investment – both financially and in engineering hours – since we are storing the data unstructured and decoupling storage from compute. You should take advantage of these newfound storage capabilities by storing both raw and processed data.
Keeping a copy of the raw historical data, in its original form, can prove essential when you need to ‘replay’ a past state of affairs – e.g. for error recovery, tracing data lineage or for exploratory analysis. However, this would be data that you access on an ad-hoc basis; whereas the data that is going to be used in analytic workflows should be stored separately and optimized for analytic consumption to ensure fast reads.
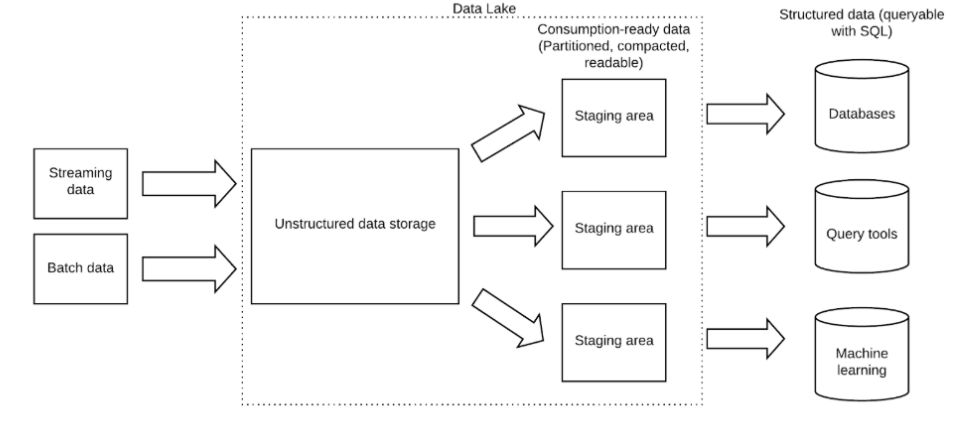
While this type of duplication might seem sacrilegious when working with expensive and cumbersome database storage; but in today’s world of managed infrastructure (e.g. in an AWS data lake), storage is cheap and there are no clusters to resize – so this course of option becomes viable.
With Upsolver, this would be implemented using Amazon S3 as the storage layer, with historical data and analytics-ready data stored in separate S3 buckets:
3. Set a retention policy
While this might seem contradictory to the previous tip, the fact that you want to store some data for longer periods of time doesn’t mean you should store all of the data forever. The main reasons you might want to get rid of data include:
- Compliance – regulatory requirements such as GDPR might dictate that you delete personally identifiable information after a certain period of time, or at a user’s request.
- Cost – data lake storage is cheap, but it’s not free; if you’re moving hundreds of terabytes or petabytes of data each day, your cloud bills are going to rack up.
You will also need a way to enforce whatever retention policy you create – this means you need to be able to identify the data that you want to delete versus the data you want to store for the longer term and know exactly where to find this data in your object storage layer (S3, Azure Blob, HDFS, etc.)
If you’re using Upsolver, you can define retention policies for data sources and outputs, and Upsolver would automatically delete the data after that period. Upsolver will also check to see if the files it is deleting are needed for any ETL process before doing so, which minimizes errors compared to manually deleting folders on Amazon S3.
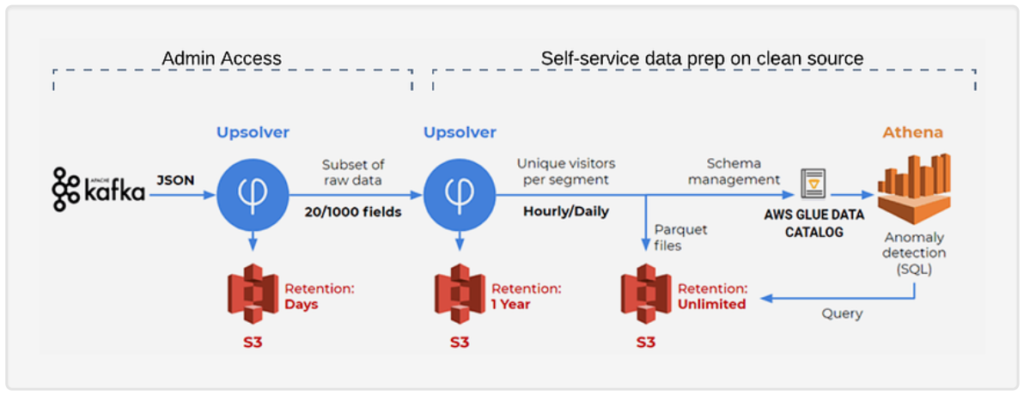
Source: SimilarWeb case study
4. Understand the data you’re bringing in
It’s true that data lakes are all about “store now, analyze later”, but going at it completely blind will not end well. You should have the ability to understand the data as it is being ingested in terms of the schema of each data source, sparsely populated fields, etc. Gaining this visibility on read rather than trying to infer it on write will save you a lot of trouble down the line by enabling you to build ETL pipelines based on the most accurate and available data.
We’ve written an entire article about schema discovery. We encourage you to peruse that article if you want to learn more about why you need a basic level of data discovery upon ingest, and how it’s implemented in Upsolver.
5. Partition your data
Partitioning your data helps reduce query costs and improve performance by limiting the amount of data query engines such as Amazon Athena need to scan in order to return the results for a specific query. Partitions are logical entities referenced by Hive metastores, and which map to folders on Amazon S3 where the data is physically stored.
Data is commonly partitioned by timestamp – which could mean by hour, by minute or by day – and the size of the partition should depend on the type of query we intend to run. If most of our queries require data from the last 12 hours, we might want to use hourly partitioning rather than daily in order to scan less data.
Watch this short video to learn more about the importance of partitioning, and how it impacts queries in Athena:
Source: ETL for Amazon Athena: 6 Things You Must Know
You can learn more about partitioning on S3 and the different considerations when choosing a partitioning strategy in this free data partitioning guide.
6. Readable file formats
Columnar storage makes data easy to read, which is why you’ll want to store the data you plan to use for analytics in a format such as Apache Parquet or ORC. In addition to being optimized for reads, these file formats have the advantage of being open-source rather than proprietary, which means you will be able to read them using a variety of analytic services.
In the same vein, note that data needs to be decompressed before reading. So while applying some kind of compression to your data makes sense from a cost perspective, you want to choose compression that is relatively ‘weak’ to prevent wasting unnecessary compute power.
Upsolver ensures data is readable by storing raw data as Avro, while analytics-ready data is stored as Apache Parquet and compressed using Snappy.
7. Merge small files
Data streams, logs or change-data-capture will typically produce thousands or millions of small ‘event’ files every single day. While you could try to query these small files directly, doing so will have a very negative impact on your performance over time, which is why you will want to merge small files in a process called compaction.
In a benchmark test we recently ran comparing Athena vs BigQuery, we saw major differences when running Athena queries on data that Upsolver compacts, partitions and converts to Parquet, compared to data that was only converted to Parquet:
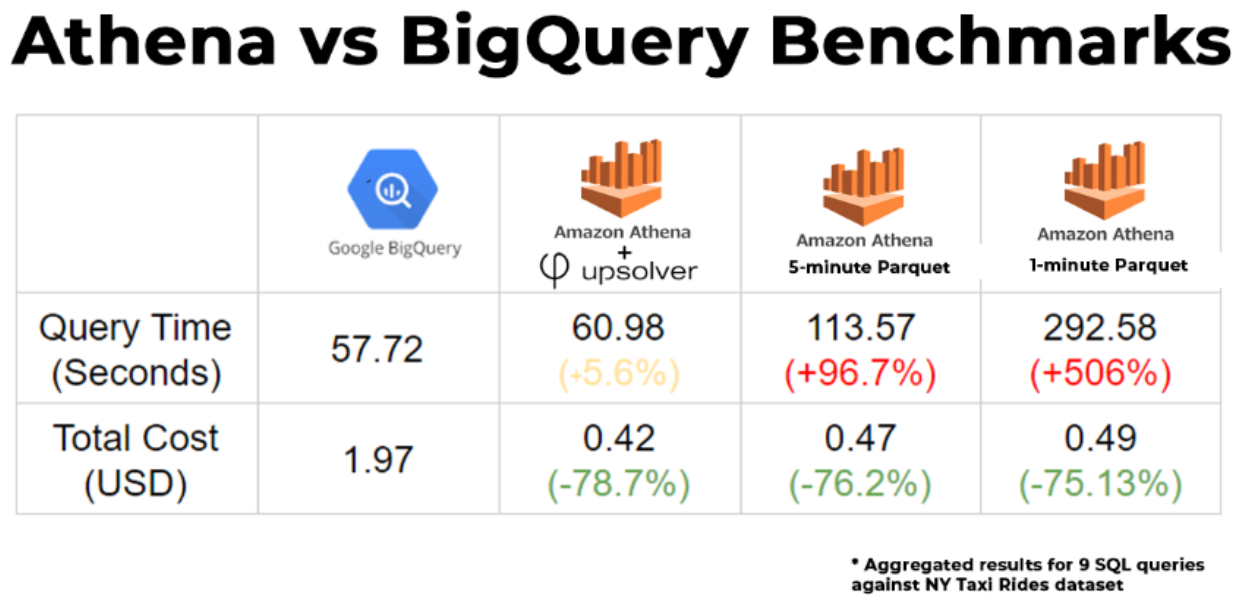
8. Data governance and access control
Data lakes have gained some notoriety among CISOs, who are rightfully suspicious of the idea of ‘dumping’ all your data into an unstructured repository, making it difficult to set specific row, column or table-based permissions as in a database.
However, this concern is easier to address today, with various governance tools available to ensure you have control over who can see which data. In the Amazon cloud, the recently introduced Lake Formation creates a data catalog allows you to set access control for data and metadata stored in S3. Protecting PII and sensitive data can also be done through tokenization.
Further Reading: Guiding Principles for Data Lake Architecture
Following these best practices when building your data lake is an important first step, but to ensure your data lake continues to serve the business you need to further consider the way you store, architect, and catalog your data. These include:
- Use event sourcing to ensure data traceability and consistency.
- Layer your data lake according to your user’s skills to ensure each consumer gets access to the data using the tools they already know.
- Keep your architecture open by storing data in open formats and using a central meta-data repository.
- Plan for performance by applying storage best practices to make data widely available.
You can read more about this in our guide to data lake architecture principles; you might also want to learn about how to organize your data lake and drain the data swamp.
Want to build a world-class data lake with minimal effort?
Upsolver can save you six months of coding by abstracting the complexity of data lakes and automatically implementing best practices under the hood. Get our technical whitepaper to learn more, or schedule a demo to see Upsolver in action.
Try SQLake for free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free for 30 days. No credit card required.
Published in:
Blog
,
Data Lakes
