Explore our expert-made templates & start with the right one for you.
Batch and Streaming Data Lake ETL with SQL
Extract, transform and load live data streams and historical big data into Athena, Redshift, ElasticSearch and RDS - with familiar ANSI SQL. Your data lake has never been more accessible.
Key Benefits and Feature Highlights
Self-service for
data consumers
Data analysts and developers can build streaming data pipelines. No Spark/Hadoop required.
Frictionless
data preparation
Easily prepare terabytes to petabytes of data for analysis, including joins between multiple streams.
Instant access to
fresh data
Write your SQL once to continuously get data that is always fresh, up-to-date, and optimized.
Unlock the value of your data.
Prepare to be astounded by how easy it is to prepare your data streaming.
Feature Highlights
Complex transformations in a familiar syntax
Need to analyze streaming data? Forget about writing hundreds of lines in Scala, clusters and workflow orchestration. If you know SQL, you’re good to go – including native support for nested data, rolling aggregations and window-based joins.
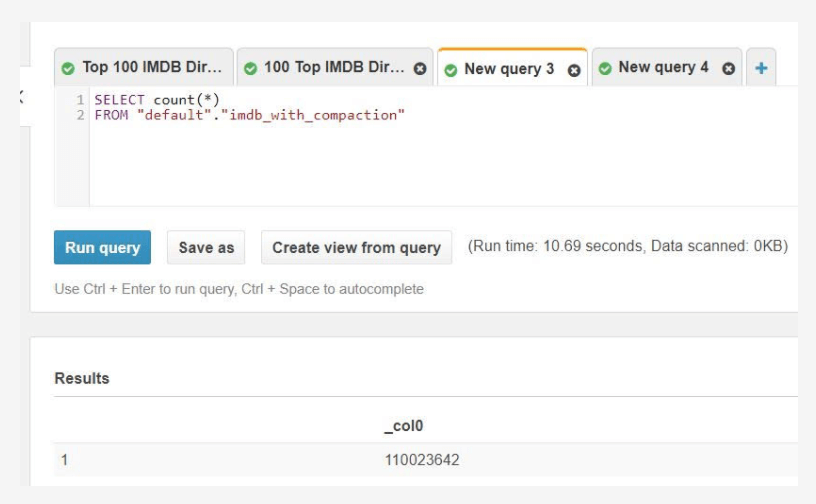
High cardinality joins between streams and data lake storage
With Upsolver, you have a single, SQL-based platform for all your ETL – batch, micro-batch and real-time – and for all your historical and live streaming data, leveraging Upsolver’s unique data lake indexing.
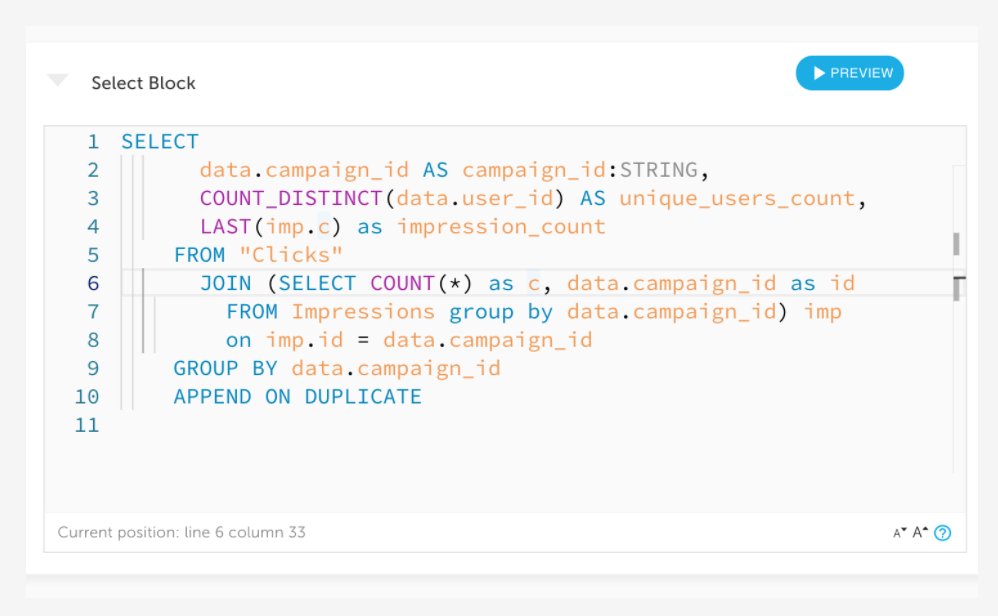
Fresh, up-to-the-minute data without ever updating your query
Write your SQL once and get low-latency data forever. Your query will return fresh data even as your data changes over time, with live data from Kafka available in Athena within seconds to minutes.
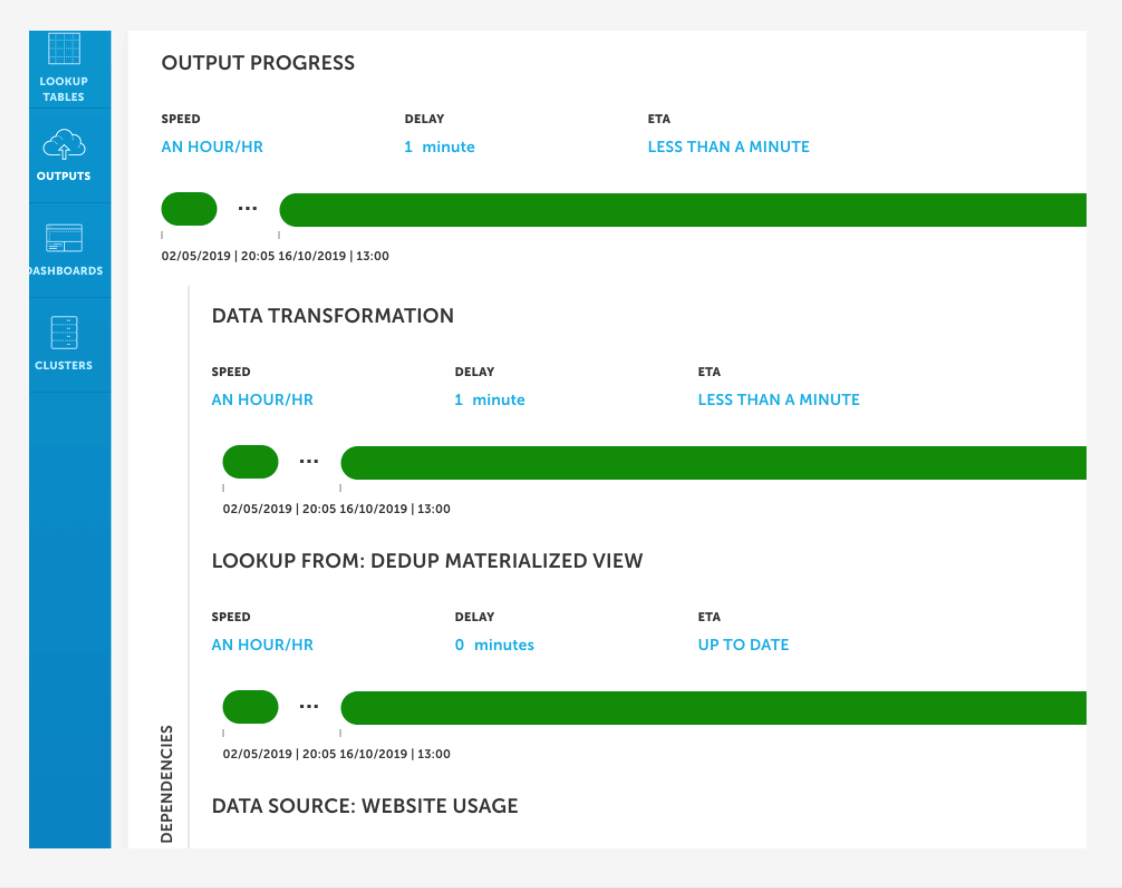
Scalable, repeatable workflows
Copy and paste SQL to quickly iterate and create new data pipelines at the speed of your business.
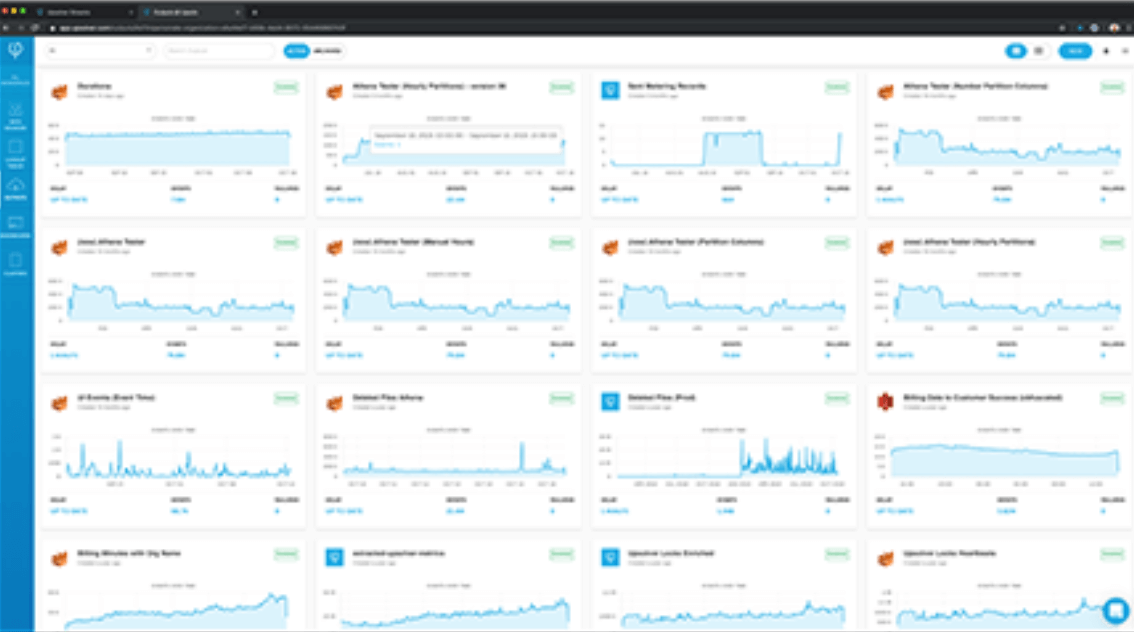
Optimized data for consumption with no additional effort
Focus on your analytic workflows while Upsolver does all the data engineering magic under the hood: partitioning, compaction, indexing, and more.
Learn more about Upsolver:
Read this case study to learn how Upsolver helped ironSource save thousands of engineering hours and cut costs.
Discover best practices you need to know in order to optimize your analytics infrastructure for performance.
Learn how to avoid common pitfalls, reduce costs and ensure high performance for Amazon Athena.
Instantly improve performance and get fresher, more up-to-date data in dashboards built on AWS Athena – all while reducing querying costs
