
Explore our expert-made templates & start with the right one for you.
Upsolver Lookup Tables: A Decoupled Alternative to Cassandra
-
 Eran Levy
Eran Levy
- Cloud Architecture
- January 9, 2020
In recent posts we’ve shown examples of implementing schema discovery and low-latency joins between streams using Upsolver. In this article we’ll take a closer look at the underlying technology that enables Upsolver to perform these types of operations implicitly, and compare it to alternative solutions which would require a NoSQL database – typically Apache Cassandra.
The Challenge: Retrieving Key-Value Data from Unstructured Storage
New data sources such as IoT sensors, web applications and server logs generate semi-structured data at a very high velocity. At higher scales, ETLing all of this data into data warehouses become impractical, and the company builds a data lake, wherein historical data is stored as raw time-series data in object storage such as Amazon S3.
While data lakes offer numerous advantages over the data warehouse approach, they are not without limitations: unstructured storage makes it easy to ingest very large volumes of data, but putting this data to use means finding alternatives to many built-in features of databases. In this context, one of the most challenging operations to perform in a data lake is retrieving records by a set of keys – especially when this operation needs to be done in low latency.
There are numerous scenarios where we might need to retrieve data by key from our lake, including:
- Joins between streaming sources – e.g. joining between impressions and clicks based on a user ID
- Data-driven applications – e.g. a mobile app that needs to pull all the records related to a specific user to show them their purchase history
- Device or user-level aggregations – e.g., creating a single view of user activity for advertising or analytics purposes
Building the necessary data pipelines in order to provide the data needed for these operations can be shockingly complex in a streaming architecture. Let’s proceed to look at why.
No Indexes and NoSQL
Traditional databases utilize indexes to retrieve data by key. Since data is indexed upon ingestion, the database can easily retrieve the relevant key-value pairs it needs to perform an operation such as a join; joining new data with older data doesn’t pose a significant challenge.
However, data lake storage is by default unstructured and unindexed. This means there is no fast and easy way to ‘pinpoint’ a specific value by key, which in turn means that retrieving all the relevant historical records requires a full table scan. At high volumes of data, this is a resource-intensive query that requires much manual tuning, and will still take a while to return results – creating latencies that could range from several hours to several days.
The traditional solution to this lack of indexing is to add a NoSQL database that will serve as the real-time key value store. As data is being ingested into the lake, the relevant key-value pairs will also be written to our NoSQL instance. Aggregations and joins are done in this database, and the results are served from there to applications that require data. Cassandra is the ‘go to’ open-source solution, while Redis and DynamoDB are also popular alternatives.
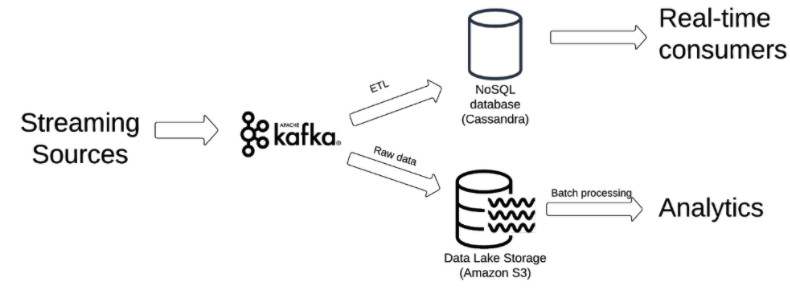
Let’s look at the pros and cons of this approach
Cassandra Advantages:
- Fast reads: NoSQL databases provide extremely fast read performance, which makes them suitable for operations that need to happen in near real-time.
- High availability and resilience: Cassandra’s distributed architecture ensures high data availability, with data stored across multiple nodes for increased resilience (no single point of failure).
Cassandra Drawbacks
Functional Limitations
Can’t retrieve historical state. This is a key functional limitation stemming from Cassandra’s architecture. The database is built to retrieve current state, rather than ‘as of’ – this makes historical lookups impossible, and requires us to run a continuous aggregation in order to get the eventual state.
For example – let’s say an ecommerce website wants to dynamically adjust the content it presents to a specific user who’s currently browsing, based on the amount of times that user has viewed the same product in the last 90 days. In order to create this aggregation, we need to run complex ETL code throughout the entire period, which means we had to think of this question in advance and before we collected the data; furthermore, our ETL code runs against live streaming data which could change over time, which means it could easily break. This entire process is very easy to get wrong.
Operational Limitations
Cassandra comes with very high DevOps overhead. One of the main reasons people use data lakes for streaming data use cases is to avoid the complex ETL coding that would be needed in order to ‘fit’ this data into a database; introducing a NoSQL database means all these problems come right back and with a vengeance. These include:
- Deploying cluster that needs to be always on. Rightsizing needs to be done in advance – this applies to both storage and compute, which are not decoupled.
- Loading data – this can be very complex due to rate limitations. Among other things we need to ensure resilience and continuously monitor the eventual storage for consistency.
- Maintenance – DevOps resources are required to ensure the database stays online and healthy – including regular backups, pruning unnecessary storage, and monitoring resources usage.
- Direct infrastructure costs – Cassandra holds all data on SSDs, including 3 copies of each record for resilience. An additional buffer is required to accommodate growth in data volumes. Storing 10 terabytes of data on a Cassandra instance in AWS will increase your cloud bill by about $5000 a month.
The alternative: Upsolver Lookup Tables
Upsolver Lookup Tables are meant to provide a solution that sidesteps the inherent limitations that stem from the lack of indexing in data lakes, while avoiding the overhead of NoSQL databases such as Cassandra.
Lookup Tables are used to retrieve data from a data lake on S3 using a set of keys in a latency of milliseconds. Lookup Table decouple reads and writes into two separate clusters, which share nothing except the data stored on S3:
- The ETL cluster creates the Lookup Table by continuously materializing the results of a simple SQL statement to S3. The SQL must include a GROUP BY clause since the aggregation keys will later be used to read the data. The materialized results are partitioned by time, as is usually the case in data lake partitioning.
- The serving cluster loads data from the S3 into RAM in order to serve read requests at a high throughput and milliseconds latency using a REST API. The serving cluster acts as a smart cache on top of S3 by only fetching relevant data into RAM and rolling up many small Lookup Table fragments into the aggregation window defined by the user.
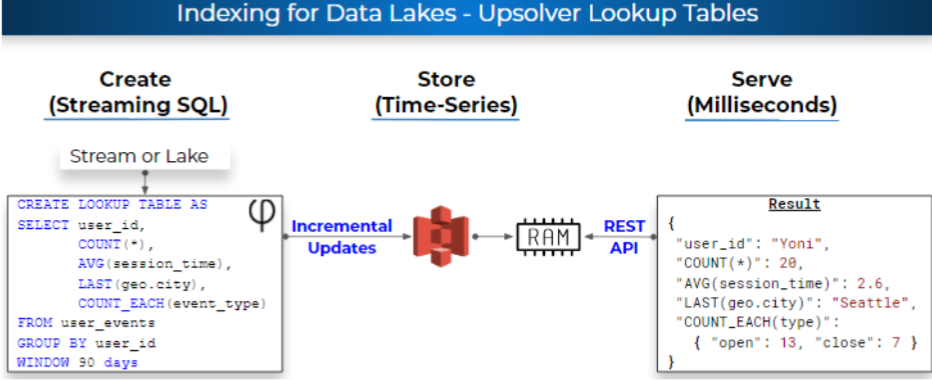
How it Works
Lookup Tables are built around three core components:
1. Storage on S3
By relying the time-series storage model described above, Upsolver can leverage Amazon S3 as the storage layer rather than a database instance – meaning the architecture stays decoupled, and users only pay for compute resources as needed. This results in tremendously lower infrastructure costs – the same 10 terabytes which we were paying $5000 to store in Cassandra, would cost $230 using S3 storage.
2. Reading compressed data in-memory
The ‘secret sauce’ behind Lookup Tables is Upsolver’s innovative compression technology. Cassandra and similar databases store compressed data on disk but require the table to be decompressed when it is loaded into RAM, whereas Upsolver uses proprietary technology that enables random access to compressed data, which enables you to store 10X-15X more data in RAM. This translates into much larger time windows of historical data, without relying on pre-defined aggregations.
3. Defined via SQL
Since Upsolver is an end-to-end data lake ETL platform, the system is aware of the schema and overall composition of the data. Indexes are created when data is ingested into S3 and updated automatically when the system identifies schema changes.
This allows end-users to define Lookup Tables as aggregations over raw data using a simple SQL statement rather than a complex NoSQL ACID API. This SQL runs continuously even as the underlying data changes – dramatically lowering the entry barrier and removing the overdependence on DevOps that a Cassandra implementation entails.
Summary: Key Benefits of Lookup Tables vs Cassandra
- Ease of use – Lookup Tables are part of the Upsolver platform and can be used by any developer or data analyst who is fluent in SQL. Cassandra requires significant DBA / DevOps resources.
- Decoupled storage and compute – index is stored as time-series object on S3 and loaded into memory for fast serving, whereas Cassandra requires constant ETL effort.
- Auto-scaling – Upsolver can automatically deploy an additional server to increase performance; with Cassandra, you would need to manually configure a new instance.
- Historical backfill – Upsolver’s unique compression technology allows for ‘time travel’ on historical data, without needing to define the aggregation in advance; Cassandra only provides current state.
- Enables many window aggregations at high cardinality, including count distinct, nested aggregation, time-series aggregation; Cassandra has limitations around high cardinality data.
- Costs – as covered above, Lookup Tables entail about 1/25 direct infrastructure costs compared to Cassandra, as well as countless engineering hours that can be put to better use (one of our customers quantified this as six months of work by four engineers).
Use Cases
Common use cases for Upsolver Lookup Tables include:
- Data-driven apps – Lookup Tables serve data at millisecond latency to apps that require data in real-time, such as monitoring and alerting systems.
- Real-time dashboards – using Lookup Tables, organizations can create deeper real-time or near real-time analytics, rather than being constricted by batch processing latencies when reports require data to be joined or aggregated.
- Real-time machine learning – Lookup Tables enable machine learning algorithms to take both real-time and historical data into account, resulting in more accurate modeling with less data engineering (as we’ve covered in our machine learning webinar).
- Single view of user or device activity – this is a common challenge in IoT and AdTech, which is easily solved by using Lookup Tables as a key-value store that aggregates every record for a specific ID.
Want to learn more?
- Join us for a live demo of Upsolver to dive deeper into Lookup Tables functionality, and to get a guided tour by one of our solution architects
- Explore our data preparation for machine learning solutions
- Get the Upsolver technical white paper
- Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Request a free consultation with Upsolver’s streaming data experts.
See how you can spin up an end-to-end streaming data pipeline in minutes.
Published in:
Blog
,
Cloud Architecture