
Explore our expert-made templates & start with the right one for you.
Intro to AWS Data Lakes: Components & Architecture
-
 Eran Levy
Eran Levy
- Data Lakes
- November 29, 2019
The following article is based on a presentation given by Roy Hasson, Senior Business Development Manager at Amazon Web Services, as part of our recent joint webinar – Frictionless Data Lake ETL for Petabyte-scale Streaming Data. You can watch the full presentation and webinar for free right here.
What is a data lake?
A data lake is a centralized, curated, and secure repository that allows you to store all of your data in a single location in a ‘store now, analyze later’ paradigm: we’re ingesting the data without having to think too much in advance about how we intend to analyze this data, what our exact use cases for it will be, or what questions we’ll want to answer with the data. Think of it as a place to store all of your data without a lot of pre-planning or pre-processing.

Why build a data lake?
One of the biggest challenges companies have today, and a major driver of data lake adoption, is the desire to break down data silos. If you want to be able to take all of the most granular data into account, get a holistic view of what customers are doing and how the business is performing, it’s important to bring all the data from all the different corners of your organization into a single location. Having a single centralized repository for your data makes it easy to analyze that data quickly and cost effectively.
But furthermore, we want to be able to use different tools and different analytic capabilities, whether it’s machine learning or simple data analytics, to be able to process that data. Doing it all in one place just makes it a lot easier for us to do that.

Data Lake Components (Business Reference Architecture)
While there is no single list of tools that every data lake must include, there are some core components that you can expect to find. From a business perspective, there are several processes that will need to be addressed within your data lake architecture:
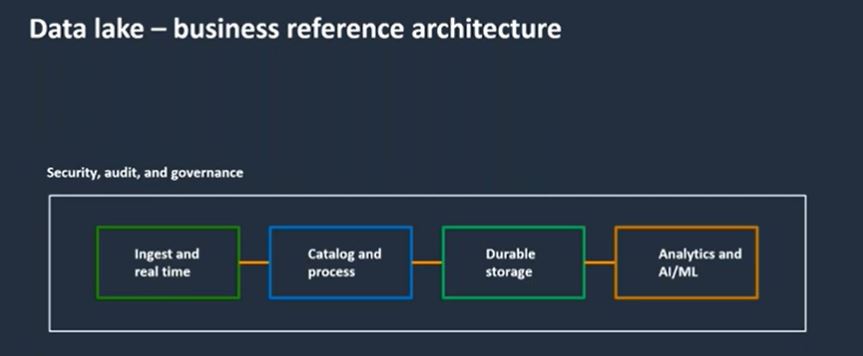
Let’s talk about each of these components:
- Ingestion: Typically the first thing we have to do is ingest the data, which basically just means getting data into our lake. Traditionally that would be done in batch workloads where we are periodically moving large volumes of data, such as a large table from an on-premise database that we are moving to the cloud. Modern architectures would often include streaming data use cases: mobile device data, IoT data, click-stream. There are different mechanisms and tools that allow you to ingest big data.
- Cataloging: Once the data has been moved to our cloud data lake, we need to be able to catalog it so we actually know what is there – otherwise we just have a lot of scattered data that we don’t really understand or know how to put to use. So we catalog the data and we expose that to a metadata store, so users can explore and really understand what exists in our lake.
- Processing: The next step that we would want to do after understanding what data we have, is to process the data. In larger organizations that have a lot of data in silos, end users such as data analysts or data scientists are forced to take the data in, process it, and do the data wrangling independently every single time because there’s really no centralized way to process that data. When we’re building our data lake we want to centralize that process in a way that is easy for us to automate, secure, and also govern,
- Storage: There are a number of considerations to take into account when storing the data. We are dealing with very large volumes of data, so it’s possible that we’re not ready to use all of it yet, while some of the data might already be operational. We need a way to store very large amounts of data in a durable fashion, but also make sure that it’s cost effective so that we’re not paying a lot of money to store all the data before we actually get any insights out of it.
- Analytics and AI / ML: Lastly, once the data has been stored, pre-processed, and cataloged, now we want to be able to bring different compute engines to query our data, – whether it’s for reporting and BI use cases, or machine learning.
This entire flow needs to be contained in a secure, governed and auditable fashion, so we can actually control that data and make sure there’s no leakage or production errors along the way.
Data Lake on AWS – Reference Architecture
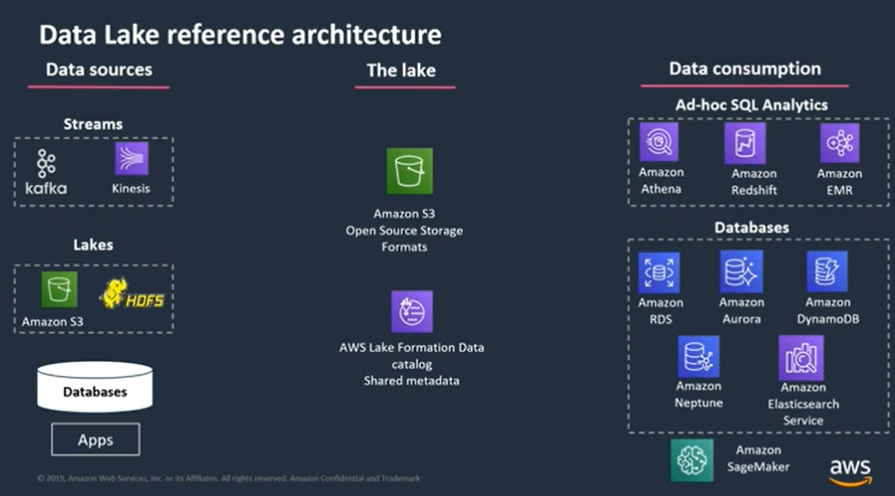
Looking at the diagram above, on the left side we see our ingested data sources – including streaming sources, static data, databases, and data warehouses. Some of this data might be on-premises, some might be on AWS already.
We want to centralize our data in durable storage, which on AWS is based on Amazon S3, which is an object store. Think of it as a place to put all of the data without really thinking about what it is and how to use it, but that also gives you life cycle policies that allow you to move the hard data to warm and cold as it transitions and evolves over time. So you’re saving on storage by moving the data to colder, more cost effective storage.
The AWS lake formation is a service that was introduced last year and was made generally available a couple of months ago. It gives you a way to build governance, security and authorization and to quickly launch your data lake.
When it comes to the data consumption layer: our data lake is common to all users, but we don’t want to force them to use a particular engine to query the data, such as a particular BI tool or database – since the whole idea behind our data lake is to enable different users to use the tools that are most efficient for them. So we want to be able to keep an open architecture and expose the lake to various tools – whether it’s Amazon Redshift, for data warehousing, Amazon Athena, for analytics and interactive queries, or Jupyter Notebooks using SageMaker for machine learning.
Learn more about AWS data lakes:
You can watch the full webinar for free to learn about:
- Best practices for using Amazon Athena as the data lake query engine
- How ironSource built and operationalized its AWS data lake at petabyte-scale
- Building declarative, self-service ETL pipelines with Upsolver
Try SQLake for free (early access)
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes