Explore our expert-made templates & start with the right one for you.
Table of contents
Data Security in the Age of Data Lakes
The growth of cloud data lakes presents new challenges when it comes to protecting personal data. With databases, sensitive data can be protected by enforcing permissions on the table, row and column level – as long as we know where which tables contain sensitive information, it’s relatively straightforward to create a data governance strategy that prevents this data from reaching unauthorized hands.
However, with data lakes things are a bit trickier since you are now responsible for raw data in files rather than tables with known metadata. When data stored in unstructured object stores such as Amazon S3, Google Cloud Storage and Azure Blob Store, it is very difficult to pinpoint the location of sensitive data in order to create an effective permissions policy.
In this guide, we present 3 solutions for dealing with security and privacy on an S3 data lake: GDPR / CCPA requests, tokenization, and separating customer data.
Use Case 1: Protecting PII & Sensitive Data on S3 with Tokenization
Let’s look at this problem through the prism of a hypothetical business challenge, and see how we can solve it using S3 partitioning and tokenization.
Consider the following scenario: An ecommerce company stores a log of customer transactions. This contains sensitive data (credit card numbers) and PII (addresses, phone numbers) which should only be accessible for very specific cases, such as chargebacks. At the same time, analysts are querying this data to generate insights into purchasing trends, which are shared across the organization.
We want to ensure all the data is stored securely and encrypted in our data lake; in addition, we want an extra layer of security for the sensitive financial information, making it completely inaccessible by both the analysts and the people accessing their reports. At the same time, we want to ensure the non-sensitive data is accessible without forcing the analyst to jump through too many hoops.
Building the Solution using S3 Partitioning, Retention and Permissions
Our solution is built on tokenizing the sensitive fields in our data, while keeping the rest of the data as-is. We are using tokenization rather than masking (read about the differences here) since the original, sensitive data still needs to be accessible in some instances such as chargebacks, customer cancellations and fraud investigation.
In this approach, we replace each protected field with a single encrypted value based on the original value using an SHA-256 hash function. We will store the mapping between each tokenized field and the original value in an Upsolver Lookup Table, which is also stored in our data lake. We will also set a short retention policy for the raw data, deleting it every 24 hours, to further ensure that the non-tokenized data does not fall into the wrong hands.
Reference architecture
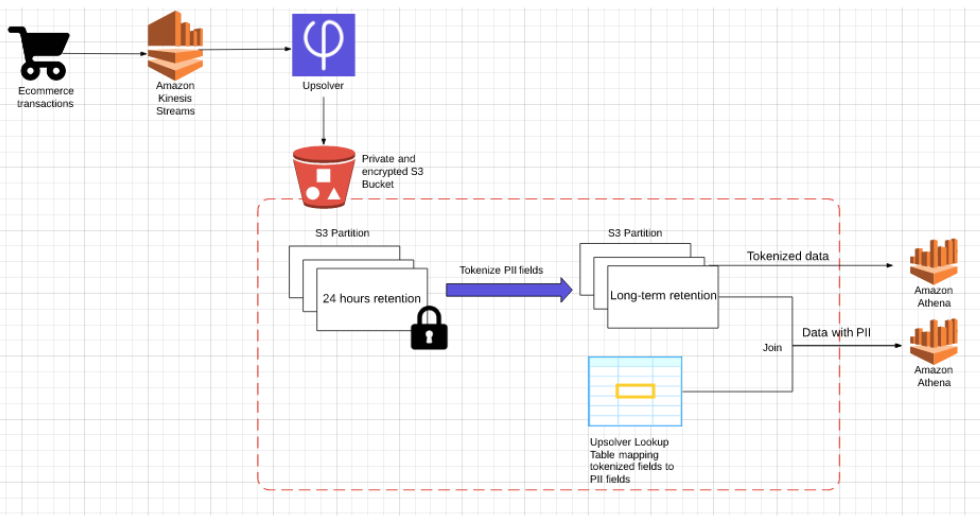
Raw data ingestion
Amazon Kinesis Streams processes the original data – the log of customer transactions that happen on our website. This stream contains sensitive information including PII and financial data.
Upsolver connects to the relevant Kinesis streams as a consumer and ingests the data into a private and encrypted S3 bucket. When configuring the data source in Upsolver, we will set a short retention policy, which means the partition where this data is stored will be deleted every 24 hours.
Tokenization
Using Upsolver’s SQL-based data transformations, we’ll proceed to create a tokenized version of the data by applying an SHA-1 hash function to every field that we want to protect – credit card, customer names and addresses, etc. This will create our anonymized, non-sensitive dataset which analysts can use to explore trends and build reports.
We will then create an Upsolver Athena output, in which all the sensitive fields will be added to the schema as Upsolver Calculated fields with an SHA-256 hash function applied to each. This data is ‘safe’ for analysts to use as all the sensitive information is tokenized. Since the risk associated with this data is much lower, we can set a longer retention policy. This output is partitioned by event time and files are compacted for optimized queries.
Finally, we configure an Upsolver Lookup Table, which allows us to index data by a set of keys and then retrieve the results from S3 in milliseconds. The Lookup Table stores key-value pairs that can be used to retrieve the non-tokenized version of the data. You can learn more about using Lookup Tables as a key-value store here.
Access control
After running our tokenization process, we can create relatively broad permissions for the tokenized datasets. Analytics and data science teams can use Amazon Athena to query this data for their purposes with no risk of data leakage.
In the instances where we do need access to the non-tokenized data, this can be achieved by joining the Lookup Table with the tokenized data by the SHA-256 key. This will create a view in Athena with the sensitive data. Using Upsolver, we can severely restrict access to this view to only a handful of authorized personnel.
Summary and Benefits Achieved
In this use cuse we presented a solution architecture for protecting PII and sensitive data on an Amazon S3 data lake. We built the solution using Upsolver and Amazon Athena in a way that ensures broad access to data for analytics on the one hand, while also ensuring every sensitive field is tokenized and restricted. We also used a short retention period as another safeguard against data leakage by deleting the original sensitive data every 24 hours.
Use Case 2: Handling GDPR / CCPA Requests in Amazon Athena
In the last few years, the way companies handle consumer data has come under increased scrutiny. Legislators on both sides of the Atlantic have introduced strict regulations in this area: The General Data Protection Regulation (GDPR) in Europe, and the California Consumer Privacy Act (CCPA).
Both of these legislations introduced various restrictions on the way companies collect, store and make use of personally identifiable information (PII), as well as harsh sanctions for breaches of duty. Hence, the ability to respond to data protection challenges is critical for organizations that want to continue processing PII without facing significant legal risks.
In this section, we’ll discuss the challenge of ensuring GDPR compliance when using Amazon Athena and explain how you can use data lake ETL tools such as Upsolver in order to remove PII from Athena quickly and efficiently.
What are GDPR / CCPA Erasure Requests?
Both the GDPR and the CCPA cover many different areas of how companies deal with user data: from affirmative consent to data being stored, through opting out of data being sold to third parties, and specific stipulations on how data is stored. There are also differences in when the law actually applies – the GDPR is the broader of the two, applying to any organization that operates within the European Union or that processes information of EU citizens.
A detailed breakdown of all of these requirements and a comparison of how they differ between the two legal acts is beyond the scope of this guide, but you can refer to this handy comparison table available as a PDF via bakerlaw.com.
For our purposes, we’d like to focus on the right to erasure / deletion: Both the GDPR and the CCPA grant consumers the right to deletion of the personal information a business has collected about them. While there are certain exceptions, in most cases the business must delete this data, and instruct its service providers to do the same. Personal data could include anything that can uniquely identify a user – names, email addresses, and even IP addresses.
The Challenge of Identifying and Removing PII in Athena / S3
Companies that receive an erasure request need to comply within 30 days (GDPR) or 45 days (CCPA) by removing said data from its databases. This is quite simple to do in a traditional database such as Redshift or Oracle, but more difficult in a data lake architecture where data is stored on Amazon S3 and queried via Amazon Athena.
As we’ve covered in the past, Amazon Athena is serverless and thus does not store any data, instead of reading data that is stored on Amazon S3. This means that if you’re using Athena to power your analytics queries, and you’ve received a GDPR / CCPA request that obligates you to remove data from an Athena table, you will need to remove that data from S3. However, this can be challenging since: Unlike databases, data lakes do not have built-in indexes, which makes it difficult to pinpoint a specific record. For example, finding a specific IP address could require us to query the entire lake, which often might contain hundreds of terabytes or petabytes of data; we would then also need to understand every action associated with this record to identify whether any third party or service provider has been given access to it.
- Data lakes are optimized for appends, wherein every new piece of data that comes in is stored sequentially and in chronological order. Modifying tables or records without an upsert API can be a challenge that requires writing dedicated code.
These factors can make GDPR compliance more difficult to achieve in Athena compared to alternative technologies. However, by being smart about the way we handle data preparation on S3 we can easily overcome these challenges and respond to removal requests without breaking a sweat.
Removing all records from the data lake
The first thing we want to do is to delete all the records pertaining to the GDPR / CCPA requests from our data lake storage on Amazon S3. We need to identify the relevant records for that user, and then delete the events containing that ID from the S3 bucket where we ingest data.
Using Upsolver, you can specify a specific user ID, and run a ‘one-off’ operation to cleanse your data lake from records containing that ID. This happens in parallel to other ETL processes, which means there’s no negative impact on performance. This instantly removes all the user data that currently exists from S3, as well as from any Athena table that reads from S3.
Removing records from upstream data during streaming ETL
Even after we’ve complied with the GDPR request with regards to the data we currently store, we want to ensure that any future reports are also GDPR compliant and don’t contain data related to a user who has asked to be removed. To do this, we will need to continuously update and delete records as part of the ETL process that writes data from Kinesis to S3 and from there to an Athena table.
We’ve written before about how Upsolver handles data lake upserts – you can visit that link for the details, but in a nutshell:
- Upsolver ingests raw data into S3 and creates an analytics-ready version of the data, which it stores as optimized Parquet in separate partitions on S3 – which is the data that will be read in Athena. A user can define a retention period for both the raw historical data and the Athena output.
- When creating ETLs with Upsolver, the users can set an Update or Delete key for output tables.
- As Upsolver continuously merges event files into optimized Parquet, it will use this key to either rewrite records (update) or skip them completely (delete) – so that the tables in Athena are updated accordingly.
GDPR is a specific instance of this process, requiring us to delete certain data with the specific piece of PII (email or IP address, name, etc.) used as our Delete key.
We can use Upsolver SQL to create a Boolean field which indicates when an event should be deleted. For example, the following SQL transformation creates a table with a field called should_delete_user which will be used to mark an event for deletion:
SELECT user_id, user_data, should_delete_user
FROM user_events
REPLACE ON DUPLICATE user_id
Based on this query, Upsolver will set a Delete Key based on the should_delete_user field. As events stream in, Upsolver will delete relevant events marked for deletion, and store this result in the Glue Data Catalog (or other Hive Metastore). The Athena table that reads this data from Glue will only contain the GDPR-compliant version of the data, with any relevant records or events removed.
Use Case 3: Protecting Customer Data in Embedded Analytics Pipelines
Almost any software or technology company offers some kind of built-in reporting to its customers. Embedded analytics is the term often used to describe customer-facing dashboards and analytics capabilities that allow end users of a company’s software to analyze data within that software.
In this section we will present a solution for building performant embedded analytics on streaming data using Amazon Athena. Upsolver will be used to ETL and partition the data on S3, which will help us run more efficient queries in Athena and ensure there is no intermingling of customer data in the dashboard that each customer sees.
The Challenge: Embedded Analytics for Multiple Customers
Let’s take a hypothetical scenario of an advertising technology company that programmatically places ads in real-time. The company works with many different advertisers and its ad units appear on different publisher websites. Apache Kafka is used to process ad-impression and ad-click streams generated by the ad unit on publisher websites, and the data is then written to S3.
The company would like each advertiser to be able to see a dashboard of overall ad unit performance per publisher website. Amazon Athena is used to query the data, while customers eventually interact with interactive dashboards that are embedded into the company’s SaaS product.
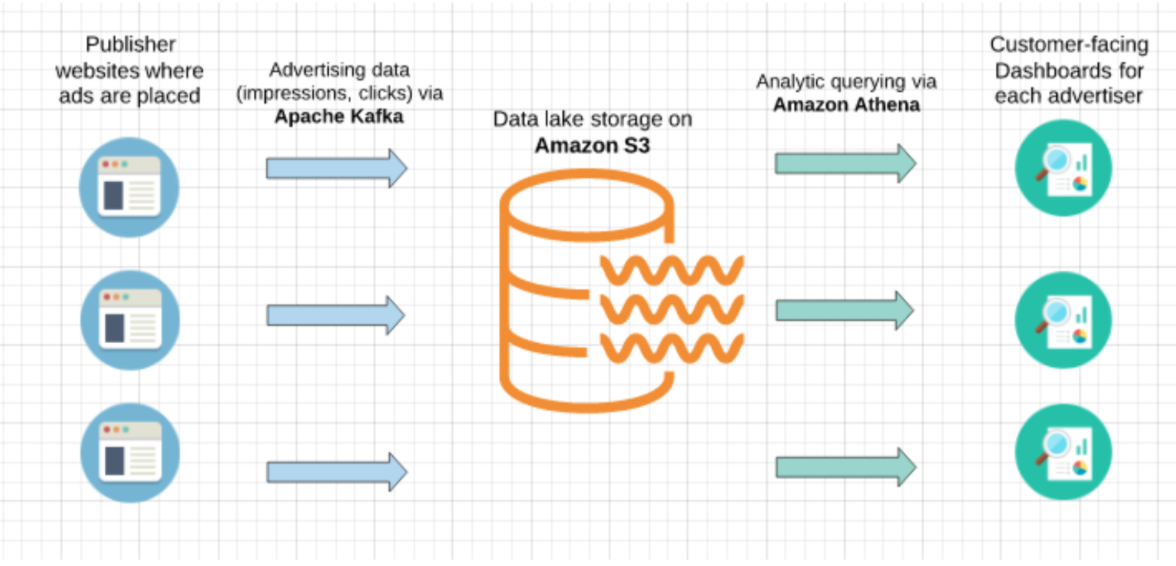
The challenge:
- Each customer should only have access to their own data
- Customers expect the embedded dashboards to show data in near real-time in order to understand how their campaigns are performing and pause or increase spend
The Solution: Custom Partitioning
Our solution is built on separating each customer’s data into its own partitions on S3, and then querying only that data in Amazon Athena.
Data partitioning for Athena
If you’re unfamiliar with how partitioning works in Athena, you should check out our previous article about partitioning data on S3. In short, folders where data is stored on S3, which are physical entities, are mapped to partitions, which are logical entities, in the Glue Data Catalog. Athena leverages partitions in order to retrieve the list of folders that contain relevant data for a query.
The most common way to partition data is by time – which is definitely what we will be using for time-series data such as ad impressions and clicks:
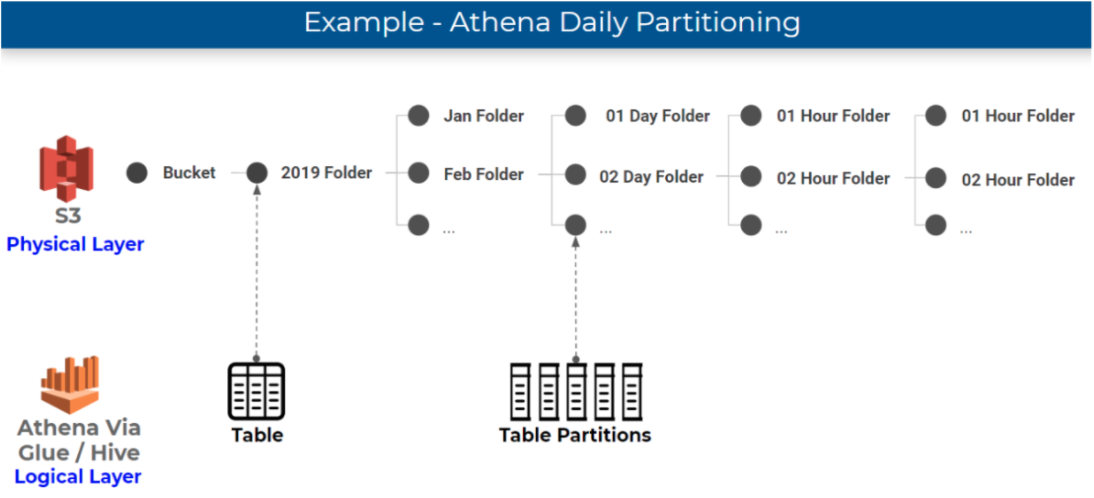
Efficient partitioning allows Athena to scan only the relevant data in order to retrieve a particular query, which reduces costs and improves performance. If the company in our example wants to see what was our average clickthrough rate for ad unit for a certain period in February, having the data partitioned by day allows us to ‘point’ Athena in the direction of that data using an SQL WHERE clause.
Custom partitioning by Customer ID
In our case we have another requirement – which is to separate each customer’s data. Each advertiser is exposed to a different dashboard, which sits on top of a different set of queries in Athena. Since we still want to minimize the amount of data scanned and ensure performance, each of these queries should only scan the data that is pertinent to that customer – which we will achieve by adding another layer to our partitioning strategy:
We’ll create custom partitions for each report we want to build in Athena so that each customer dashboard only queries that customer’s data: This is easy to do using Upsolver’s self-service data lake ETL, but if you’re not using Upsolver you can do it with whatever ETL code you are writing to ingest and partition data. Here’s how it would work:
- In addition to partitioning data by time, we will also be partitioning events by Customer ID – so that each ad impression and ad click is associated with a specific advertiser.
- As we are ingesting the data to S3, we will be writing each advertiser’s events to a separate partition.
- To ensure each advertiser only sees their own data, we will only give them permission to view the data in ‘their’ S3 partitions
- We’ll use the Customer ID in Athena to only query the relevant partitions for each dashboard.
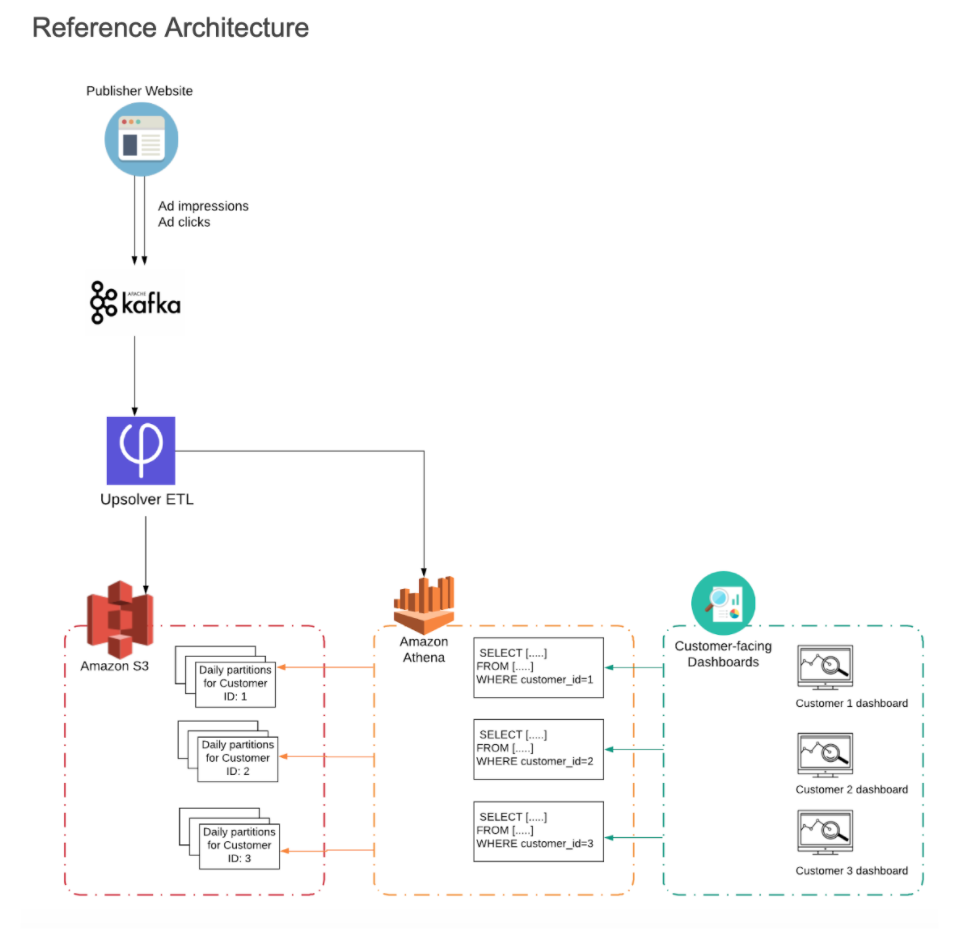
Building the Solution using Upsolver, S3 and Athena
In this section we’ll present a quick walkthrough on how to create custom partitions for embedded analytics in Athena, using Upsolver on AWS.
Step 1: Partition the data on S3
In the Data Source, we will tell Upsolver to partition the data by date as well as by a field within the data which will be Customer ID. As Upsolver ingests the data from Kafka, it will be partitioned by Customer ID and event time.

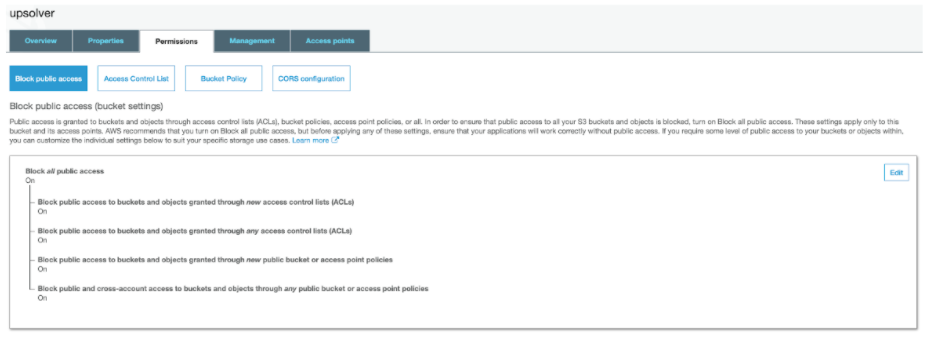
Step 2: Set S3 permissions
To prevent any possibility of ‘data leakage’ and ensure each customer only sees their own data, we will only grant each customer permission to read data from the partition that stores their data, based on the customer_id identifier. This is done in the S3 management console:
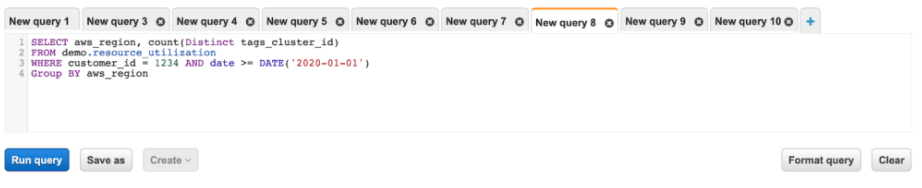
Step 3: Running the query in Athena
For each customer-facing dashboard, the Athena query that retrieves the relevant dataset will be specified to fetch the data from the partitions storing the relevant time-period as well as the relevant customer_id.
Step 4: Sharing data with customers
Typically customers would interact with a dashboard that sits ‘on top’ of Athena and visualizes the relevant dataset per customer_id. These dashboards might be developed in-house or using an embedded analytics solution such as Looker, Sisense, Tableau etc.