Explore our expert-made templates & start with the right one for you.
Big data ingestion is a major challenge in most data lake implementations. With Upsolver, you can simplify ingest pipelines and effortlessly write live data to your S3 data lake, bypassing common roadblocks and ensuring data is written and stored according to object storage best practices. By optimizing ingestion and storage, you can create an accessible and performant data lake.
Understanding the big data ingestion challenge
To understand the value of using a tool such as Upsolver for ingest pipelines, we need to understand the types of challenges most organizations encounter when writing data to object storage such as Amazon S3. These include:
- Architectural challenges: Data lakes are often built on the premise of ‘store data now, analyze later’. While this is a useful paradigm for data exploration, it means you’re often building the lake without knowing exactly what you want to do with the data, which could lead to data being dumped into object storage without a clear strategy for ingestion and operationalization. This can become problematic since data which is not ingested and stored according to best practices will be very difficult to access further down the line, turning your data lake into a data swamp. Implementing these best practices requires a high level of technical expertise.
- Functional challenges around maintaining performance at scale – this includes continuous storage optimization which is best done upon ingestion, such as converting ingested files from JSON format to Apache Parquet, choosing the right partitioning strategy, and compacting small files. Exactly-once processing of event streams from Kafka or Kinesis, without losing or duplicating messages, is also notoriously difficult to implement. These issues are exacerbated by the data lake’s unstructured nature and lack of visibility which creates a reliance on ‘blind ETL’.
Automating Data Lake Ingestion
Various open-source frameworks can be used to ingest big data into object storage such as Amazon S3, Azure Blob or on-premises Hadoop. However, these tend to be very developer-centric and can be taxing to configure and maintain, especially when new data sources or schemas are being added or when data volumes grow very quickly. In these cases, automating data ingestion could prove to be a more robust and reliable solution.
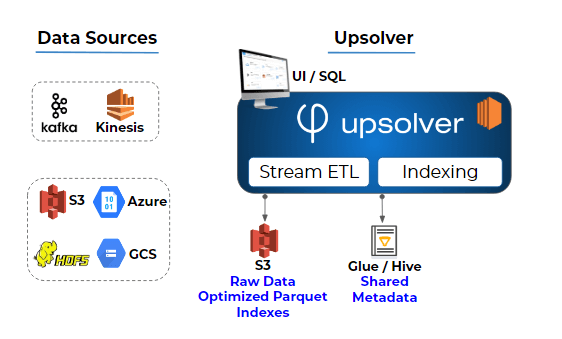
Upsolver automates ingestion by natively connecting to event streams (Apache Kafka or Amazon Kinesis) or existing object storage, stores a raw copy of the data for lineage and replay, along with consumption-ready Parquet data – including automatic partitioning, compaction and compression. Once data is on S3, Upsolver offers industry-leading integration with the Glue Data Catalog, making your data instantly available in query engines such as Athena, Presto, Qubole or Spark.
Key Features of the Upsolver Solution
- Native connectors to stream processors (Kafka, Kinesis) and data lakes (Amazon S3, Azure Blob, Google Cloud Storage) allows you to quickly choose the data you need to ingest to your lake
- Baked-in best practices for data storage and optimization, reducing the need for tedious and cumbersome ETL coding while ensuring your data is easily accessible for future analytics and machine learning initiatives
- Automatic data partitioning on S3
- Automatic compaction of small files
- Analytics-ready data stored in columnar file formats such as Apache Parquet and ORC – optimized for consumption; alongside raw data stored in Avro
- Ability to replay historical data for data exploration, experimentation and to incident investigation
- Native integration with Hive metastores such as AWS Glue makes data instantly queryable in a variety of SQL-based engines, including Athena, Presto, and Redshift Spectrum
- Automatic schema discovery and indexing for semi-structured data upon ingest, solving the visibility challenge
Why companies choose to automate data lake ingestion with Upsolver
The key benefits we hear from customers who replaced coding-based data ingestion with Upsolver’s automated data lake ETL tool include:
- Making the data lake accessible – since data is stored ready for consumption with no additional ETL required, analysts and data scientists can instantly use SQL engines to query the data
- Reducing engineering costs associated with maintaining MapReduce or Spark jobs to optimize file sizes and formats
- Storing historical data from Kafka or Kinesis in a cost-effective matter, while making it easy to replay an event stream for data exploration or investigation
- Visibility into the data being ingested into the lake, which helps create a structured data lake rather than a data swamp