
Explore our expert-made templates & start with the right one for you.
Solving the Upserts Challenge in Data Lakes
-
 Shawn Gordon
Shawn Gordon
- Use Cases
- April 1, 2020
Updating or deleting data (upserts) is a basic functionality in databases, but is surprisingly difficult to do in data lake storage. In this article, we will explain the challenge of data lake upserts, and how we built a solution to enable an efficient and quick update and delete operations on object storage using Upsolver’s SQL-based data transformation engine.
If you need an out-of-the-box tool for upserts on your data lake, you should go ahead and schedule a demo of Upsolver – we offer a FREE proof of concept on your data and in your environment. For the details of how our solution is built and how it works, keep reading.
Typical Use Cases for Upserts
Before we present the challenge, let’s start with the ‘why’. In what scenarios do you need data lake upserts? In other words, when would we need to delete or update a record which we’ve already written to a database or lake? Here’s a non-comprehensive list of business scenarios:
- GDPR and similar PII regulations: The European General Data Protection Act and California Consumer Privacy Act (CCPA) stipulate that companies must remove personal information from their databases upon request, which will require us to find and delete these records in our data lake.
- Data warehouse migration and CDC: Change data capture (CDC) is a design pattern for database replication based on a set of changes instead of a full table copy. CDC enables organizations to act in near real-time based on data in their operational databases, or to replicate legacy systems into cloud data lakes. This requires us to update records in our data lakes based on updates to the replicated database.
- Fraud detection: Removing or flagging fraudulent transactions from an eCommerce database, or fraudulent clicks on ads. It could be minutes or days between the time of the event and the time in which fraud is detected, which will require updating historical data storage.
- User and session-based aggregations: When dealing with sessionization or user profiling, we would need to update a table containing user data based on recent interactions.
- Another broader set of scenarios could be around ensuring consistency and reliability by removing erroneous records that found their way into the data lake due to system or human mishap.
The Challenge: Pinpointing Records on Object Storage
In a database, upserts are barely an issue. Since databases have built-in indices, it is easy to pinpoint a specific record and to change that record or remove it completely.
However, in a data lake, we are storing data in unstructured object storage such as Amazon S3, Azure Blob Storage or HDFS.
Object storage is used for append-only analysis, where the data is typically partitioned by time. In this architecture, there’s no easy way to pinpoint a specific record which is necessary for operations like upsert or delete. Essentially we are dealing with log files, sitting in folders in the order they arrive in, without indexes or consistent schemas
Due to these built-in limitations, finding the record that needs to be updated or deleted requires us to perform full data scans. Scanning the entire historical database to identify all previous instances that need to be updated is a resource-intensive, time-consuming operation, which can lead to delayed responses to change requests or strain IT resources. In the meantime, users don’t get a consistent view of the data like there are used to from databases.
The Solution
In light of the challenges we outlined above, and which many of our customers struggled with, the Upsolver ETL platform introduced data lake upserts that are configured via a visual interface or as SQL. In the next section, we’ll explain the process that happens under the hood, and which allows the platform to efficiently update and delete tables stored on object storage as part of ongoing streaming ETL.
The solution is based on Views to maintain data consistency for users and an on-going data compaction process to merge updates/deletes into object storage. We previously covered the topic of compaction in the context of accelerating AWS Athena by reducing the number of small files.
When creating ETLs with Upsolver, it’s possible to define an Update or Delete key for output tables. This tells Upsolver that the table is bound to get updates and deletes. As a result, Upsolver will run a two phase ETL process.
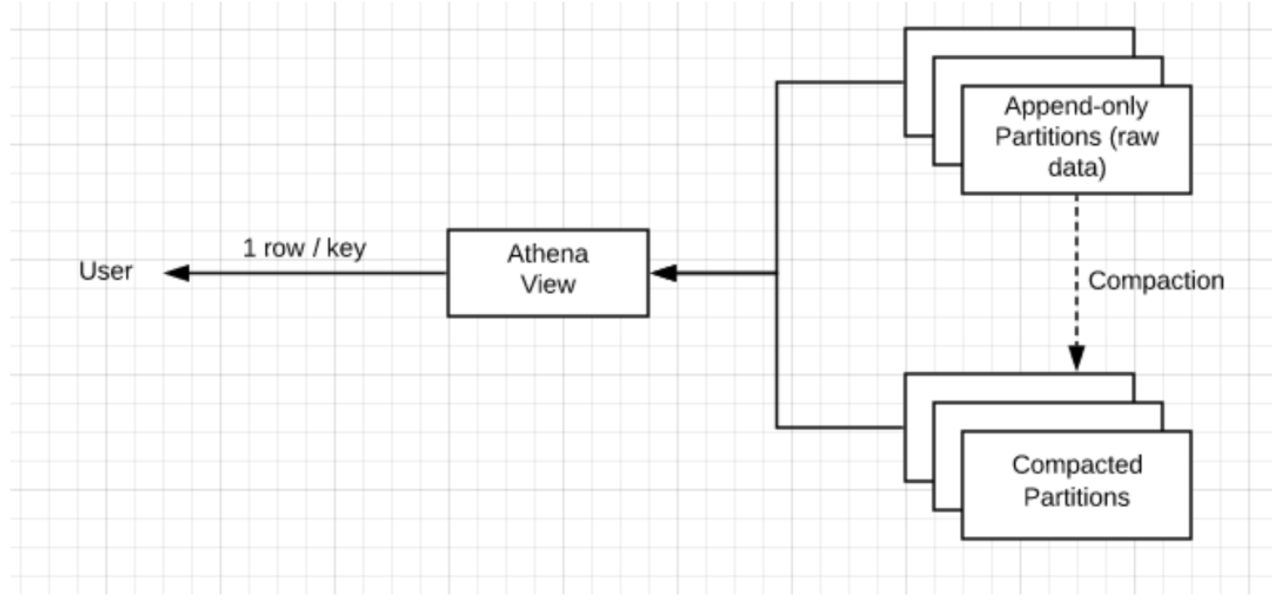
In the first phase, new data is immediately written to object storage (append-only) so it will be available for queries. As opposed to the append-only case, users will query a View that Upsolver created instead of the table. The View’s only job is to return the last values that are associated with the table key. This step makes sure that data is immediately available and consistent but the caveat is performance. The View will need to scan all the table data which leads us to the second step – on-going compaction.
When the user defined the upsert key in Upsolver’s ETL job, Upsolver started keeping a map between the table keys and files that contain them. The compaction process looks for keys in more than one file and merges them back into one file with one record per key (or zero if the last change was a delete). The process keeps changing the data storage layer so the number of scanned records on queries will be equal to the number of keys and not the total number of events.
For example, the following SQL in Upsolver defines an ETL from a stream of events into a table with user_id as the upsert key and the number of historic user records as a column:
SELECT user_id, COUNT(*) as user_events_count
FROM user_events
GROUP BY user_id
Once the ETL is executed, Upsolver creates a view and a table in the relevant metastore (Hive metastore, AWS Glue Data Catalog). The table has two types of partitions: Append-only for new data and Compacted for data with just 1 entry per key. To ensure a consistent result, every query against the view scans all the data in the append-only partitions but the Compacted partitions only require to scan the data until finding the first result (1 entry per key). Keeping the append-only partitions small is critical for maintaining fast queries which is why it’s so important to run Compaction continuously.
Benefits of Upsolver’s Data Lake Upserts
Performing upserts as part of an ongoing data ingestion and storage optimization process has several advantages:
-
- Efficiency: Only the relevant data and partitions need to be read and rewritten, rather than the entire database
- Simplicity: Upserts are handled via a simple SQL query that does not require manual tuning
- Consistency: Since Upsolver indexes data and ensures exactly-once processing upon ingestion, there is a high level of certainty that all relevant records will be updated.
Learn more
- Get our technical whitepaper to learn more about the Upsolver platform.
- See a demo of Upsolver to see data lake upserts in action and chat with our solution architects.
- Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.