
Explore our expert-made templates & start with the right one for you.
How to Build Data Lake Architecture, with 8 Examples (on S3)
-
 Eran Levy
Eran Levy
- Data Lakes
- June 9, 2021
This article presents reference architectures and examples of data lake implementations, from around the web as well as from Upsolver customers. For a more detailed, hands-on example of building a data lake to store, process and analyze petabytes of data, check our data lake webinar with ironSource and Amazon Web Services.
Upsolver’s newest offering, SQLake, takes advantage of the same cloud-native processing engine used by the Upsolver customers featured here. With SQLake you can build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
So you’ve decided it’s time to overhaul your data architecture. What’s next? How do you go about building a data lake that delivers the results you’re expecting?
Well, we’re strong believers in the notion that an example is worth a thousand convoluted explanations. That’s why we’ll jump right into real-life examples of companies that have built their data lakes on Amazon S3, after covering some basic principles of data lake architecture. Use this guide for inspiration, reference, or as your gateway to learn more about the different components you’ll need to become familiar with for your own initiative.
What is data lake architecture?
A data lake is an architecture pattern rather than a specific platform, built around a big data repository that uses a schema–on–read approach. In a data lake, we store large amounts of unstructured data in an object store such as Amazon S3, without structuring the data in advance and while maintaining flexibility to perform further ETL and ELT on the data in the future. This makes it ideal for businesses that need to analyze data that is constantly changing, or very large datasets.
Data lake architecture is simply the combination of tools used to build and operationalize this type of approach to data – starting from event processing tools, through ingestion and transformation pipelines, to analytics and query tools. As we shall see in the examples below, there are many different combinations of these tools that can be used to build a data lake, based on the specific skillset and tooling available in the organizatino.
To learn more, check out What is a Data Lake? and Understanding Data Lakes and Data Lake Platforms.
Design Principles and Best Practices for Building a Data Lake
We’ve covered design principles and best practices in more depth elsewhere – you can check out the links to dive deeper. In this article, we’ll quickly run through the 10 most important factors when building a data lake:
- Event sourcing: store all incoming events in an immutable log, which log can then be used for ETL jobs and analytics use cases. This approach has many benefits, including the ability to reduce costs, validate hypotheses retroactively, and trace issues with processed data.
- Storage in open file formats: A data lake should store data in open formats such as Apache Parquet, retain historical data, and use a central meta–data repository. This will enable ubiquitous access to the data and reduce operational costs.
- Optimize for performance: You’ll eventually want to put the data in your lake to use. Store your data in a way that makes it easy to query, using columnar file formats and keeping files to a manageable size. You also need to partition your data efficiently so that queries only retrieve the relevant data.
- Implement data governance and access control: Tools such as AWS data lake formation make it easier to control access to data in a data lake and address security concerns.
- Schema visibility: You should have the ability to understand the data as it is being ingested in terms of the schema of each data source, sparsely populated fields, and metadata properties. Gaining this visibility on read rather than trying to infer it on write will save you a lot of trouble down the line by enabling you to build ETL pipelines based on the most accurate and available data.
Learn more about how to structure your data lake.
8 Data Lake Examples to Copy and Learn From
Data lakes are used to power data science and machine learning, lower the total cost of ownership, simplify data management, incorporate artificial intelligence and machine learning, speed up analytics, improve security and governance, centralize and consolidate data, quickly and seamlessly integrate diverse data sources and formats, and democratize data by offering users broader access to data through more diverse tooling.
Check out the examples below to see how are data lakes are used across industries to reduce costs and improve business agility:
1. Sisense Builds a Versatile Data Lake with Minimal Engineering Overhead
As a leading global provider of business intelligence software, Sisense has data-driven decision making embedded in its DNA. One of the richest sources of data the company has to work with is product usage logs, which capture all manner of users interacting with the Sisense server, the browser, and cloud-based applications.
Over time, and with the rapid growth in Sisense’s customer base, this data had accumulated to more than 70bn records. In order to effectively manage and analyze this data, the company quickly realized it would have to use a data lake architecture, and decided to build one using the AWS ecosystem. We’ve written a more detailed case study about this architecture, which you can read here.
The Data Lake
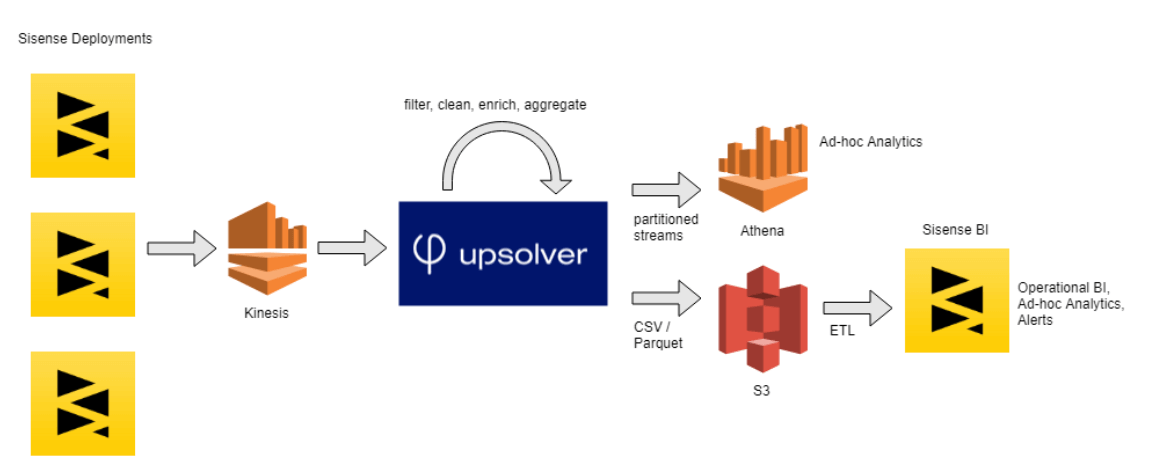
To quickly generate value for the business and avoid the complexities of a Spark/Hadoop-based project, Sisense’s CTO Guy Boyangu opted for a solution based on Upsolver, S3, and Amazon Athena.
Product logs are streamed via Amazon Kinesis and processed using Upsolver, which then writes columnar CSV and Parquet files to S3. These are used for visualization and business intelligence using Sisense’s own software. Additionally, structured tables are sent to Athena to support ad-hoc analysis and data science use cases.
To learn more about Sisense’s data lake architecture, check out the case study.
2. Depop Goes From Data Swamp to Data Lake
Depop is a peer-to-peer social shopping app based in London, serving thousands of users. These users take various actions in the app – following, messaging, purchasing and selling products, and so on – creating a constant stream of events.
The Depop team documented their journey in two excellent blog posts. After an initial attempt to create replicas of the data on Redshift, they quickly realized that performance tuning and schema maintenance on Redshift would prove highly cumbersome and resource intensive. This led Depop to adopt a data lake approach using Amazon S3.
The Data Lake
 Click to enlarge. Image source: Depop Engineering Blog.
Click to enlarge. Image source: Depop Engineering Blog.
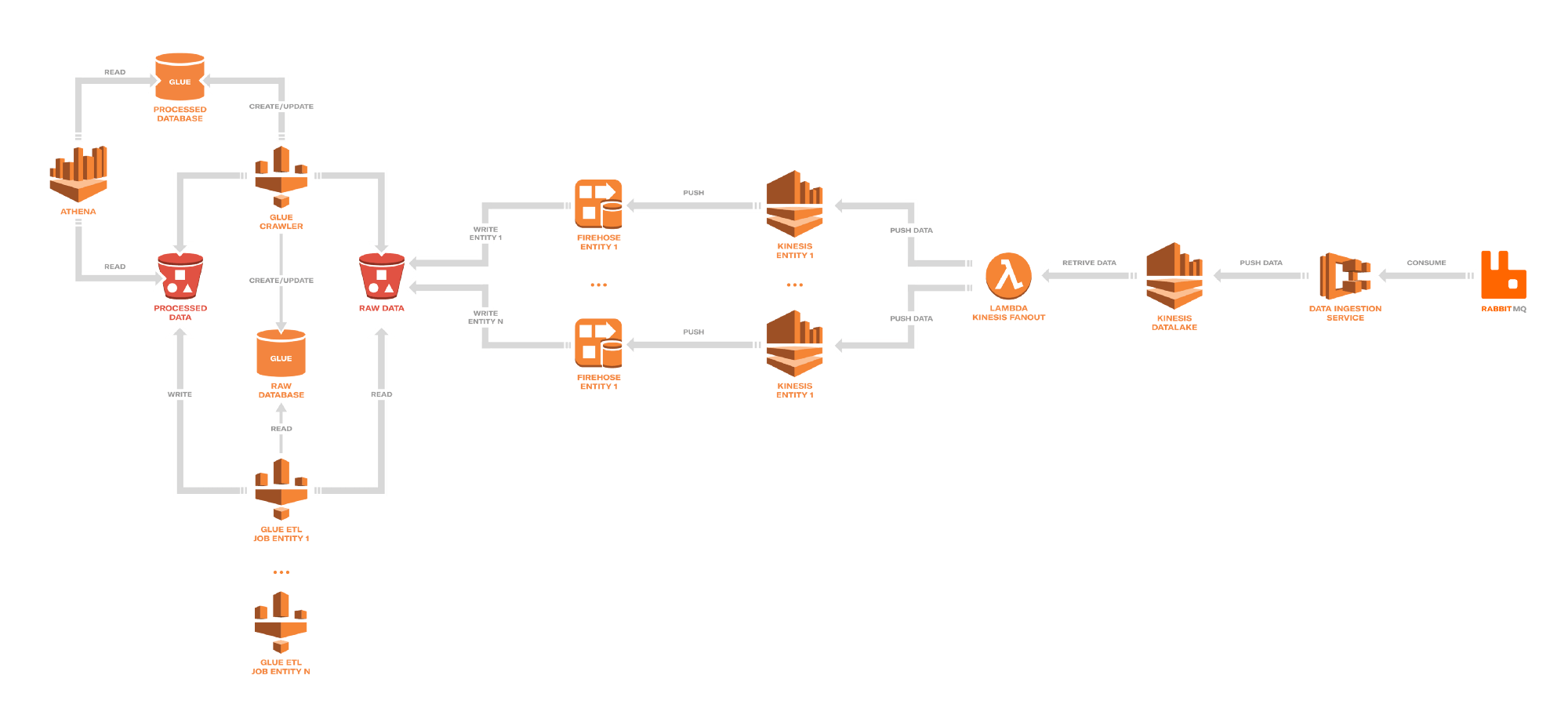
The data lake at Depop consists of three different pipelines:
- Ingest: Messages are written via RabbitMQ, and dispatched via a fanout lambda function.
- Fanout: The lambda function sets up the relevant AWS infrastructure based on event type and creates an AWS Kinesis stream.
- Transform: The final step is creating columnar Parquet files from the raw JSON data, and is handled using the AWS Glue ETL and Crawler. From there data is outputted to Athena for analysis.
For more information about Depop’s data lake, check out their blog on Medium.
3. ironSource Streams its Way to Hypergrowth
ironSource is the leading in-app monetization and video advertising platform. ironSource includes the industry’s largest in-app video network. The company collects, stores, and prepares vast amounts of streaming data from millions of end devices.
When ironSource’s rapid data growth effectively obsoleted its previous system, it chose Upsolver to help it adopt a streaming data lake architecture, including storing raw event data on object storage.
The Data Lake
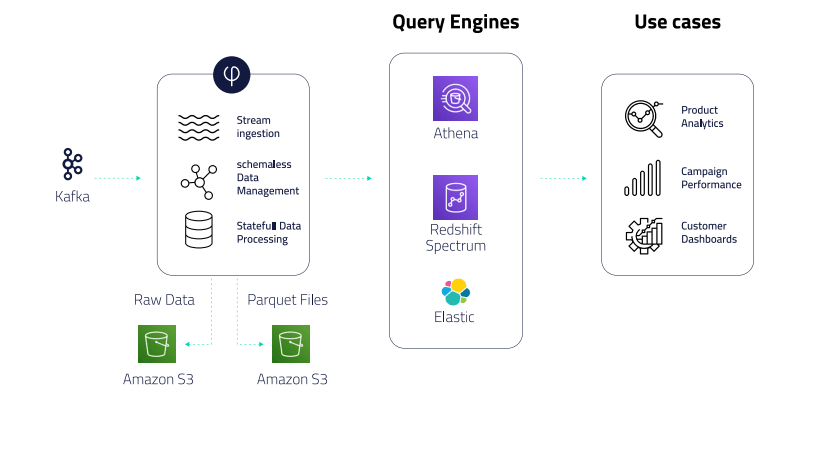
- Using Upsolver’s no-code self-service UI, ironSource ingests Kafka streams of up to 500K events per second, and stores the data in S3.
- Upsolver automatically prepares data for consumption in Athena, including compaction, compression, partitioning, and creating and managing tables in the AWS Glue Data Catalog.
- ironSource’s BI teams use Upsolver to enrich and filter data and write it to Redshift to build reporting dashboards in Tableau and send tables to Athena for ad-hoc analytic queries.
Learn more about ironSource’s data lake architecture.
4. Bigabid Builds a High-Performance Real-time Architecture with Minimal Data Engineering
Bigabid brings performance-based advertisements to app developers, so clients only pay when new users come to their application through the ad. Bigabid takes advantage of machine learning (ML) for predictive decision-making and goes beyond social media and search engine data sourcing to create an in-depth customer user profile.
Bigabid had to replace its daily batch processing with real-time stream processing, so the company could update user profiles based on users’ most recent actions and continue to develop and scale ad campaigns. Using Upsolver’s visual no-code UI, Bigabid built its streaming architecture so quickly, it saved the equivalent of 6-12 months of engineering work from four dedicated engineers.
The Data Lake
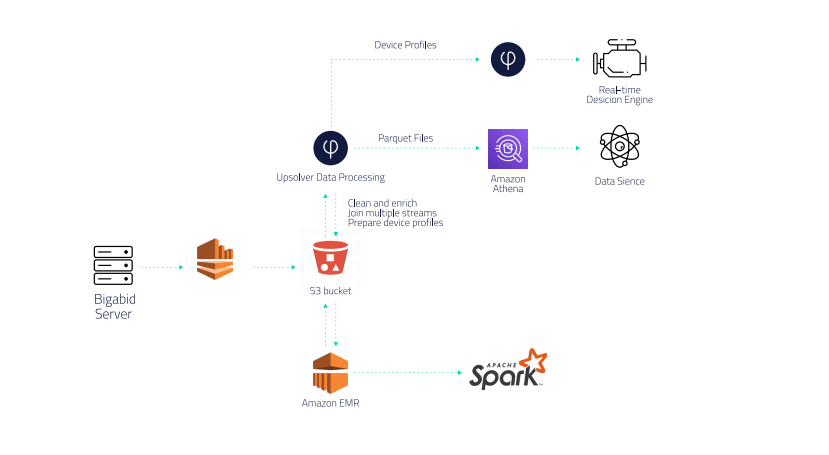
Bigabid uses Kinesis Firehose to ingest multiple data streams into its Amazon S3 data lake, then uses Upsolver for data ETL, combining, cleaning, and enriching data from multiple streams to build complete user profiles in real-time. The company also uses Upsolver and Athena for business intelligence (BI) reporting that is used by its data science team to improve machine learning models.
Upsolver also automatically prepares data for Athena, optimizing Athena’s storage layer (Parquet format, compaction of small files) and sharply accelerating queries.
Learn more about Bigabid’s real-time data architecture.
5. SimilarWeb Crunches Hundreds of Terabytes of Data
SimilarWeb is a leading market intelligence company that provides insights into the digital world. To provide this service at scale, the company collects massive amounts of data from various sources, which it uses to better understand the way users interact with websites.
In a recent blog post published on the AWS Big Data Blog, Yossi Wasserman from Similar Web details the architecture that the company uses to generate insights from the hundreds of terabytes of anonymous data it collects from mobile sources.
The Data Lake
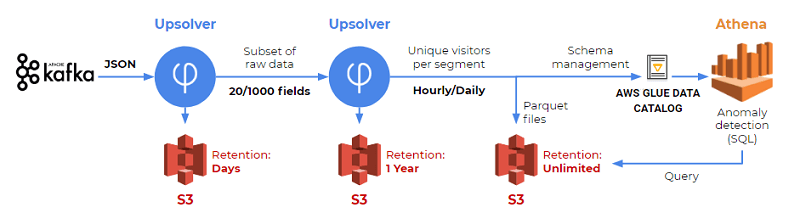
Image source: AWS blog
The SimilarWeb solution utilizes S3 as its events storage layer, Amazon Athena for SQL querying, and Upsolver for data preparation and ETL. In his article, Wasserman details the way data is sent from Kafka to S3, reduced to include only the relevant fields needed for analysis, and then sent as structured tables to Athena for querying and analysis.
Read more about Similar Web’s data lake solution on the AWS blog.
6. An Event-driven, Serverless Architecture at Natural Intelligence
Natural Intelligence runs comparison sites across many different verticals. As Denise Schlesinger details on her blog, the company was looking to accomplish two different goals with this data:
- Query raw, unstructured data for real-time analytics, alerts and machine learning
- Store structured and optimized data for BI and analytics
To effectively work with unstructured data, Natural Intelligence decided to adopt a data lake architecture based on AWS Kinesis Firehose, AWS Lambda, and a distributed SQL engine.
The Data Lake
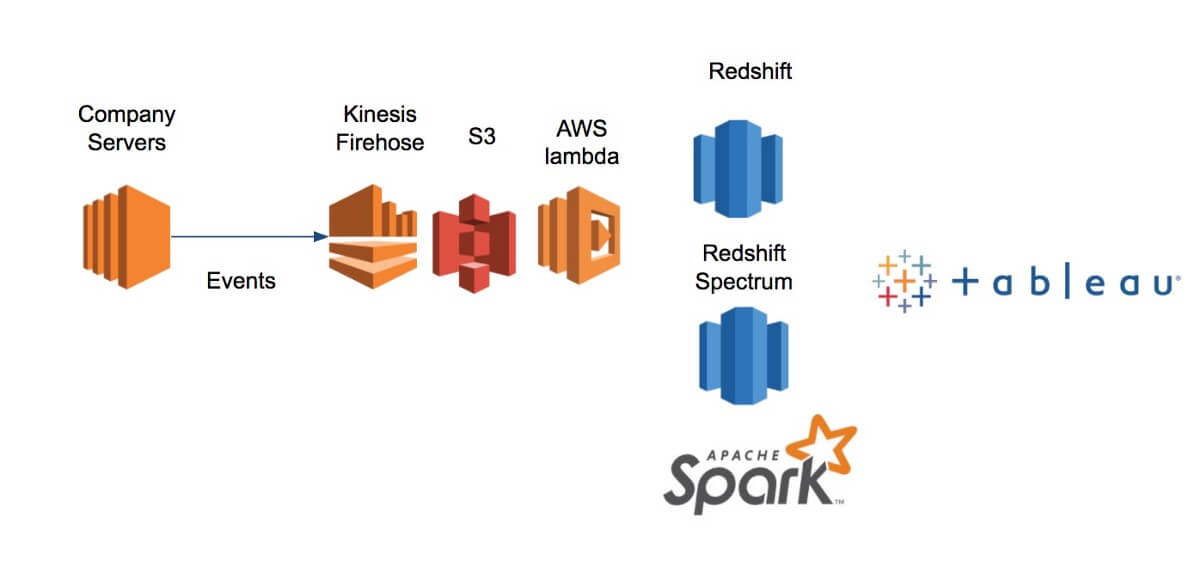
Image source: Denise Schlesinger on Medium
S3 is used as the data lake storage layer into which raw data is streamed via Kinesis. AWS Lambda functions are written in Python to process the data, which is then queried via a distributed engine and finally visualized using Tableau.
For more details about this architecture, check out Denise’s blog on Medium.
7. Peer39 Contextualizes Billions of Pages for Targeting and Analytics
Peer39 is an innovative leader in the ad and digital marketing industry. Each day, Peer39 analyzes more than 450 million unique web pages holistically to contextualize the true meaning of the page text and topics. It helps advertisers to optimize their spend and place ads in the right place, at the right time.
The Data Lake
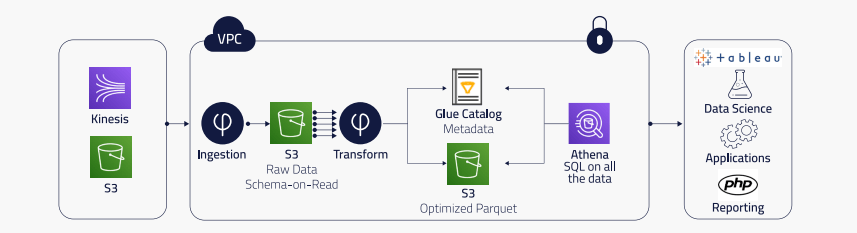
Upsolver automates and orchestrates Peer39’s data workflow, incorporating built-in data lake best practices including:
- partitioning
- queuing
- guaranteed message delivery
- exactly-once processing
- optimization of Athena’s storage layer (Parquet format, compaction of small files) so queries run much faster.
Peer39’s updated streaming data architecture unified teams across data science, analytics, data engineering, and traditional database administration, enabling the company to speed go-to-market with existing staff.
Learn more about Peer39’s streaming data architecture.
8. Browsi – Managing ETL Pipelines for 4 Billion Events with a Single Engineer
Browsi provides an AI-powered adtech solution that helps publishers monetize content by offering advertising inventory-as-a-service. Browsi automatically optimizes ad placements and layout to ensure relevant ad content.
Browsi needed to move from batch processing to stream processing, and move off of manually-coded data solutions.
The Data Lake
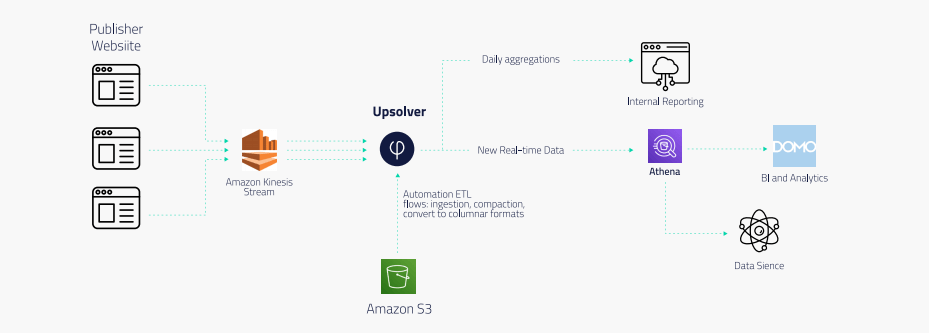
Browsi implemented Upsolver to replace both the Lambda architecture used for ingest and the Spark/EMR implementation used to process data.
Events generated by scripts on publisher websites are streamed via Amazon Kinesis Streams. Upsolver ingests the data from Kinesis and writes it to S3 while enforcing partitioning, exactly-once processing, and other data lake best practices.
From there, Browsi outputs ETL flows to Amazon Athena, which it uses for data science as well as BI reporting via Domo. End-to-end latency from Kinesis to Athena is now mere minutes. Meanwhile, a homegrown solution creates internal reports from Upsolver’s daily aggregations of data.
And it’s all managed by a single data engineer.
Learn more about Browsi’s streaming ETL pipelines.
How to Build a Data Lake:
- Map out your structured and unstructured data sources
- Build ingestion pipelines into object storage
- Incorporate a data catalog to identify schema
- Create ETL and ELT pipelines to make data useful for analytics
- Ensure security and access control are managed correctly
Ready to build your own data lake?
Upsolver is the fastest and easiest way to get your S3 data lake from 0 to 1. Schedule a demo to learn how you can go from streams to analytics in a matter of minutes. For additional data infrastructure best practices, check out some of these data pipeline architecture diagrams.
Try SQLake for free for 30 days. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes