Explore our expert-made templates & start with the right one for you.
Data Lake
Back to glossaryA data lake is an architectural design pattern in big data. It is not a single product; rather, a data lake is a set of tools and methodologies for organizations to derive value from extremely large – and often dynamic and fast-growing – data sets.
Data lakes center around a decoupled and virtually limitless file repository in which to preserve all of your raw data in a “store now, analyze later” paradigm. This layer often leverages inexpensive object storage such as Amazon S3, Azure Blob Storage or Hadoop on-premises. A data lake typically also consists of a variable range of tools and technologies that move, process, structure, and catalog the data to make it queryable – and therefore valuable.
Companies set up data lakes primarily for analytics. They can store and organize operational data in its native format – both historical and continuously-updated – of any type:
- raw (tabular)
- semi-structured (JSON or log files)
- unstructured (videos, images, binary files)
Data can arrive in synchronous or asynchronous batches or stream continuously in real-time. Just a few examples:
- transactional data from CRM and ERP systems
- event-based data from IoT devices such as road sensors and health trackers
- clickstreams and log files from social media sites and Web apps
- documents and media files from internal collaboration systems
Data is stored as-is and schema-less. Once stored, it’s fed to other systems that in turn make it available to a range of business applications for analysis and modeling, such as:
- data warehouses
- machine learning
- visualization
- NoSQL databases
- business intelligence
- real-time reporting
Data lakes differ from data warehouses, which store only structured data and must impose schema-on-write when data is ingested. Data warehouses can be a great fit for certain static use cases. But the schema-on-read model of data lakes means you can structure data when you retrieve it from storage; that, and the spectrum of available file formats, open up many more possibilities for data analysis and exploration tools and techniques. Data lakes are also ideally-suited for business use cases tasks that change over time.
What are the benefits of a data lake?
Broadly, data lakes enable you to harness more data, from more sources, in less time, and analyze data using a wide variety of tools or techniques. As compared to traditional database storage or data warehouses, data lakes improvements include:
- Speed
- Flexibility
- Scale at low cost
- Resilience and fault tolerance
Speed
Data lakes ingest data without any kind of transformation or structuring. Instead, they write data in objects or blocks. At a later stage that data is parsed and adapted into the desired schema only as it’s read during processing. This means:
- Data lakes are ideally suited for storing vast streams of real-time transactional data as well as virtually unlimited historical data coming in as batches.
- You can store data just in case you may someday need it, without caring about storage capacity.
- Data scientists, who may not know exactly what they are looking for, can find, access, and analyze data more quickly and accurately, as the lack of strict metadata management enables faster data writes.
Flexibility
You can also think of a data lake as storage and analysis with no limits.
- You’re not limited by the way you chose to structure your data before it’s stored.
- You can store data in its native raw form, no matter the format.
As a result, you can use your data in a near-limitless variety of ways – for example, structured data processing, as with databases and data warehouses, or machine learning, including:
- sentiment analysis
- fraud detection and prediction
- natural language processing
- rapid prototyping
- recommendation engines
- personalized marketing
Scale at low cost
Storage is cheap. Computing cycles are not. Data lakes decouple storage from the dramatically more costly compute. This makes working with large amounts of data much more cost-effective compared to storing the same amount of data in a database, which combines storage and computing.
There’s no pre-defined schema. You can easily add new sources or modify existing ones without having to build custom pipelines, which sharply reduces the need for dedicated infrastructure and engineering resources. And the schema-on-write paradigm essentially reduces the amount of data for engines such as Athena to process. This further reduces compute costs by avoiding repeated searches of the entire lake.
Additional savings come from reduced hardware (servers) and maintenance costs (people as well as data centers, cooling and power, and so on).
Resilience and fault tolerance
Data lakes are usually configured on a cluster of scalable commodity hardware, typically in the cloud. The distributed nature of this cloud data lake means errors further down the pipeline are less likely to affect production environments. (Data lakes can live on-premises, but increasingly they are cloud-based.)
Further, storing historical data ensures accuracy and enables replay and recovery from failure.
What is a Data Lake architecture?
Value comes from the surrounding infrastructure that ultimately makes data available to the data scientists and business analysts tasked with extracting insights, creating models, generating reports, and improving services. (The combination of data lake storage and the infrastructure that underpins it is sometimes called a data lakehouse.) Some organizations use multiple vendors to build this infrastructure. Others “lock in” with one vendor’s proprietary technology. That’s what’s behind the delta lake vs. data lake debate.)
The goal of an architecture is to connect the dots from data ingested to a complete analytics solution. The framework varies, but typically encompasses schema discovery, metadata management, and data modeling. These are complex tasks and involve multiple components such as:
- Apache Spark
- Apache Kafka
- Apache Hadoop
Components can be stitched together with:
- Java
- Scala
- Python
Techniques for creating an ETL pipeline or ELT move data from component to component. They also play a critical role in massaging streams of unstructured data to make it accessible.
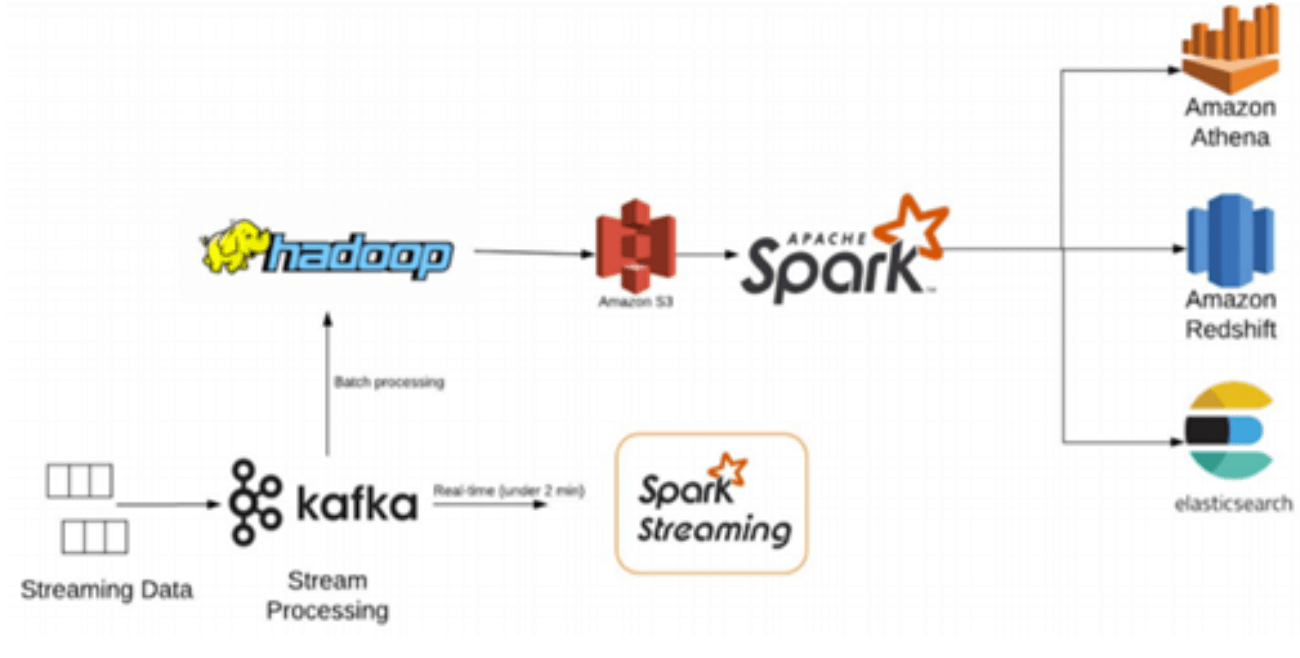
There is no single list of tools every data lake must include. Data lake best practices vary as a result. But there are core components you can expect to find. In the S3 data lake stack illustrated below, for example:
- the data is ingested by Amazon Kinesis, controlled by a Lambda function that ensures exactly-once processing
- ETL is a batch process, coded in Spark/Hadoop and running on an Amazon EMR cluster once daily.
- Services such as EMR, Athena, and Redshift can all query the same copy of the data simultaneously, so there is no additional cost or overhead.