
Explore our expert-made templates & start with the right one for you.
Understanding Data Lakes and Data Lake Platforms
-
 Eran Levy
Eran Levy
- Data Lakes
- January 5, 2022
The following article is an abridged version of our new guide to Data Lakes and Data Lake Platforms – get the full version for free here.
If you’re working with data in any capacity, you should be familiar with Data Lakes. Even if you don’t need one today, the rapid growth of data and demand for increasingly versatile analytic use cases (such as reporting, machine learning, and predictive analytics) could result in your organization outgrowing its data infrastructure much sooner than you currently foresee.
We’ve prepared this quick guide to help get you ready for that day, and keep you from asking embarrassing questions such as “what kind of data lake do you think we should buy?” To understand what’s wrong with that line of reasoning, let’s jump right into:
What is a Data Lake?
Data Lakes: The 60 Second Definition
A data lake is a centralized repository storing both structured and unstructured data in its native formats, alongside metadata tags and unique identifiers. The architecture is flat rather than hierarchical as in a data warehouse. The data is stored on object storage, with compute resources handled separately, which reduces the costs of storing large volumes of data.
An architecture, not a product
The first thing to understand, and which often confuses people who come from a database background, is that the term “data lake” is most commonly used to describe a certain type of big data architecture, rather than a specific product or component. This confusion is made worse by the fact that certain products are actually called Data Lake, and by the general mess of terminology and vendor noise in the big data space.
However, and as we’ve previously explained in an article on KDnuggets, the term itself is meaningful in describing a specific architectural paradigm: the idea that when working with massive amounts of data, we would opt to store raw data in its original form in one centralized repository (the ‘lake’), and use this repository to later support a broad range of use cases.
Store now, analyze later
The core tenet of the data lake approach is to separate storage from analysis. Data lakes ingest streams of structured, semi-structured and unstructured data sources, and store the data as-is and schema-less.
This is a sharp deviation from traditional analytics, where we would build our database in a way that was best suited to support a particular use case – transactional, reporting, ad-hoc analytics, etc, and then structure the data accordingly.
After all data has been stored successfully, and we’ve decided what we would like to do with it, data can then be outputted to other systems that will make it workable for various consumer applications: Data warehouse, machine learning, BI tools, NoSQL databases and dozens of other platforms that manage, integrate and structure the data for analysis.
Learn more in our data engineering glossary: what is a data lake?
Typical Use Cases for Data Lakes
Data lakes are typically used as a centralized repository, consolidating both processed and unprocessed data including text and unstructured sources such as images and media files, as well as streaming sources such as server logs. Different applications would pull from this data for operational purposes, interactive analytics, and more advanced use cases such as AI and machine learning.
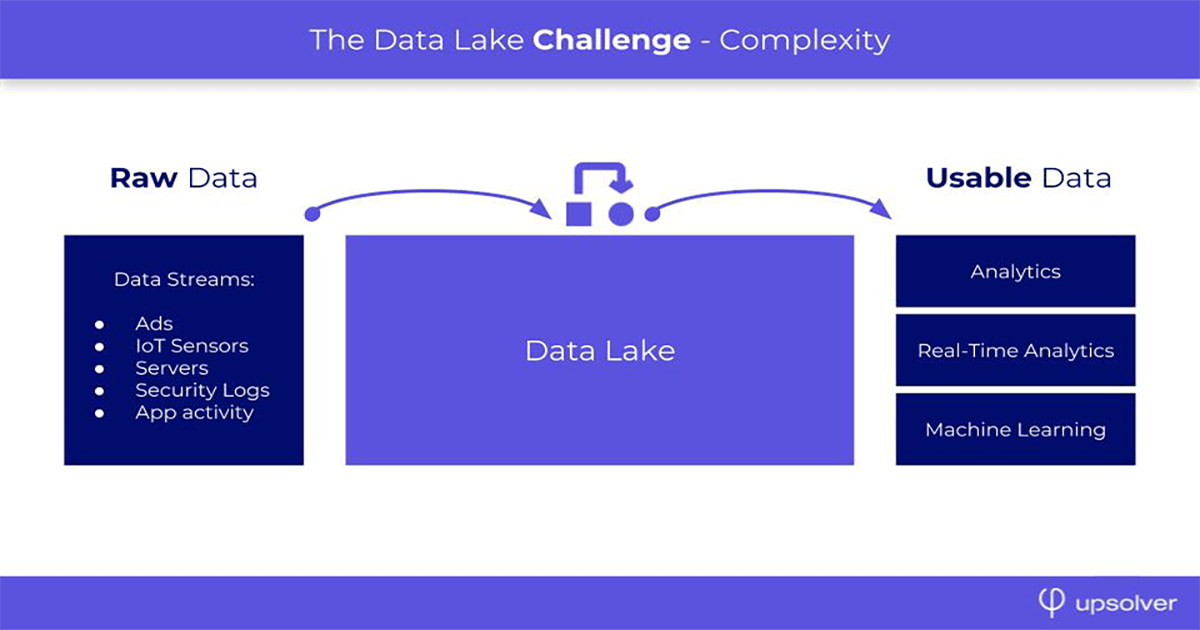
Data lakes are helpful when working with streaming data – event-based data streams generated continuously, such as by IoT devices, clickstream tracking, or product/server logs. Typically these are small records in very large quantities, in semi-structured format (often JSON).
Deployments of data lakes will usually address one or more of the following business use cases:
- Centralized repository for all business data: Data lakes store large volumes of data. Due to storage in the lake being scalable and relatively inexpensive, and the flexibility it provides for collecting different types of data, businesses can use data lakes to store much more data than they would in a data warehouse, without constantly grappling with cost optimization questions.
- Business intelligence and analytics – analyzing streams of data to identify high-level trends and granular, record-level insights.
- Data science – unstructured data opens creates more possibilities for analysis and exploration, enabling innovative applications of machine learning, advanced statistics and predictive algorithms.
- Data serving – data lakes are usually an integral part of high-performance architectures for applications that rely on fresh or real-time data, including recommender systems, predictive decision engines or fraud detection tools.
Data lakes are helpful when working with streaming data – event-based data streams generated continuously, such as by IoT devices, clickstream tracking, or product/server logs. Typically these are small records in very large quantities, in semi-structured format (often JSON).
Advantages of Data Lakes
A data lake offers unmatched scale and a very high level of flexibility to process data using various technologies, tools, and programming languages. The separation of storage and compute allows businesses to cut direct infrastructure costs while storing large volumes of data, and reduce the overhead of ingesting semi-structured data into a warehouse.
In the scenarios we just described, there are numerous advantages to a data lake approach:
- Resource optimization: by decoupling (cheap) storage from (expensive) compute resources, data lakes can be tremendously cheaper than databases when working with high scales.
- Less ongoing maintenance: the fact that data is ingested without any kind of transformation or structuring means it’s easy to add new sources or modify existing ones without having to build custom pipelines.
- Broader range of use cases: data lakes give organizations more flexibility in how they eventually choose to work with the data, and can support a broader range of use cases, since you are not limited by the way you chose to structure your data upon its ingestion.
Data Lake Challenges
Data lakes are notoriously difficult to manage. When looking at total cost of ownership (including engineering costs), they can also be very expensive, and data lake projects can take years to start delivering real value. Data security and governance also need to be implemented separately.
Despite these advantages, it is an unfortunate truth that most big data projects fail (85% according to some estimates). Common obstacles include:
- Technical complexity: Not only are most data lake architectures not self-service for business users, they are not self-service even for experienced developers – instead requiring a team of dedicated data engineers to maintain the multitude of building blocks, pipelines and moving parts that compose a data lake architecture. As we’ve previously written, this process kind of sucks.
- Slow time-to-value: Data lake projects can drag on for months or even years, creating a resource drain that is increasingly difficult to justify.
- Data swamps: Storing raw data provides a high level of flexibility, but foregoing all data governance and management principles can lead organizations to hoard massive amounts of data that they will likely never use, while making it more difficult to access the data that could actually be useful. Learn more about structuring your data lake to avoid data swamp.
- Security and compliance: Implementing access control, security, and governance in a data lake is non-trivial due to poor visibility into the data and the inability to natively update or delete records. This can create headaches when records need to be removed for compliance reasons. Learn more about data lake upserts.
Data Lake Deployments – Cloud and On-premises
While data lakes are often associated with Hadoop, the terms are far from interchangeable. In fact, it would be safe to say that most new data lakes are being built in the Cloud (with Amazon Web Services leading the pack, following by Microsoft Azure and Google Cloud Platform). For these reasons Gartner has recently predicted that Hadoop implementations are approaching obsoletion.
However, our experience indicates that organizations which work with truly massive data (in the tens to hundreds of petabytes) might be deterred by the costs of storing and processing all of that data in the Cloud, and hence we are still seeing large data lake implementations built on HDFS on-premises – so we are not so quick to proclaim the death of Hadoop.
Learn more about cloud vs on-premises data lakes
What is a Data Lake Platform?
A Data Lake Platform (DLP) is a software that is meant to address the data lake challenges which we’ve covered in the previous section – complexity, sluggish time to value, and overall messiness. The DLP addresses these challenges by:
- Unifying data lake operations and combining building blocks to create simpler data lake architectures – instead of a patchwork of glued-together systems, a DLP offers a single platform that takes care of everything from data management and storage to processing, ETL jobs and outputs.
- Enforcing best practices and optimizing data flows, and thus replacing months of manual coding in Apache Spark or Cassandra with automated actions managed through a GUI.
- Improved performance and resource utilization throughout storage, processing and serving layers.
Data Lake Platforms enable developers without an extensive big data background to create a complete pipeline from incoming data streams to structured data, that can be queried using SQL or other analytic tools. By doing so, DLPs enable organizations to generate more business value from their data lakes, at a faster pace.
Components of a Data Lake Platform
- Unifying data lake operations and combining building blocks to create simpler data lake architectures – instead of a patchwork of glued-together systems, a DLP offers a single platform that takes care of everything from data management and storage to processing, ETL jobs and outputs.
- Enforcing dozens of best practices you need to master for a data lake, and thus replacing months of manual coding in Apache Spark or Cassandra with automated actions managed through a GUI.
- Improving performance and resource utilization throughout storage, processing and serving layers.
- Providing governance and visual data management tools.
Want to learn more?
Get the full guide now to read about:
- Data lakes vs databases
- Use case and architecture examples
- Overview of the Upsolver Data Lake Platform
Try SQLake for free (early access)
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes