Explore our expert-made templates & start with the right one for you.
ironSource: built a multi-purpose data lake with Upsolver, Amazon S3, and Amazon Athena
CUSTOMER STORY

INDUSTRY:
In-app and video monetization
USE CASE:
Collect, store, and prepare data to support multiple use cases while minimizing infrastructure and engineering overheads
DATA:
500K events per second and over 20 billion events daily
9X
increase in scale
Fees reduction
Factoring infrastructure, workforce, and licensing costs
70%
of the data stored in Amazon ES cut
ironSource helps app developers take their apps to the next level, including the industry’s largest in-app video network. Over 80,000 apps use ironSource technologies to grow their businesses.
The massive scale in which ironSource operates across its various monetization platforms—including apps, video, and mediation—leads to millions of end-devices generating massive amounts of streaming data.
The Requirements
- Scale – ironSource processes 500K events per second and over 20 billion events daily. The ability to store near-infinite amounts of data in S3 without preprocessing the data is crucial.
- Flexibility – ironSource uses data to support multiple business processes. Because they need to feed the same data into multiple services to provide for different use cases, the company needed to bypass the rigidity and schema limitations entailed by a database approach.
- Resilience – Because all historical data is on S3, recovery from failure is easier, and errors further down the pipeline are less likely to affect production environments.
The Goal
After working for several years in a database-focused approach, the rapid growth in ironSource’s data made their previous system unviable from a cost and maintenance perspective. Instead, they adopted a data lake architecture, storing raw event data on object storage, and creating customized output streams that power multiple applications and analytic flows.
9X
increase in scale
Fees reduction
Factoring infrastructure, workforce, and licensing costs
70%
of the data stored in Amazon ES cut
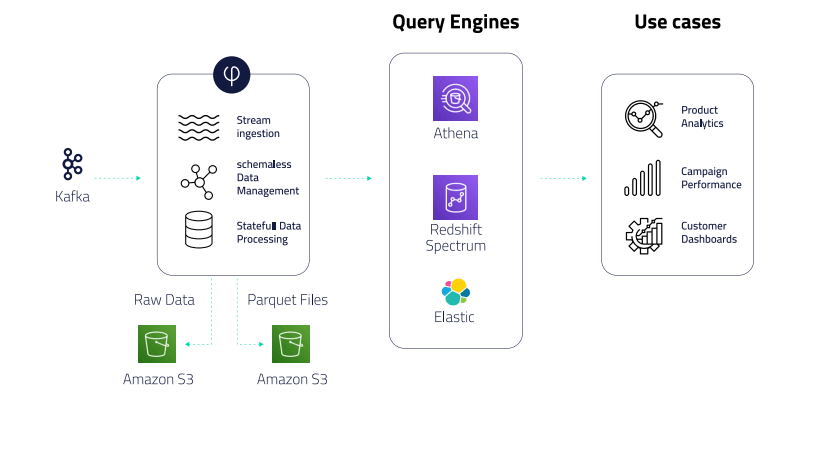
The Solution
- Self-sufficiency for data consumers – As a self-service platform, Upsolver allows BI developers, Ops, and software teams to transform data streams into tabular data without writing code.
- Improved performance – Because Upsolver stores files in optimized Parquet storage on S3, ironSource benefits from high query performance without manual performance tuning.
- Elastic scaling – ironSource is in hyper-growth, so needs elastic scaling to handle increases in inbound data volume and peaks throughout the week, reprocessing of events from S3, and isolation between different groups that use the data.
Upsolver’s streaming data platform automates the coding-intensive processes associated with building and managing a cloud data lake. Upsolver enables ironSource to support a broad range of data consumers and minimize the time DevOps engineers spend on data plumbing by providing a GUI-based, self-service tool for ingesting data, preparing it for analysis, and outputting structured tables to various query services.
The Results
Self-sufficiency is a big part of ironSource’s development ethos. In revamping its data infrastructure, the company sought to create a self-service environment for dev and BI teams to work with data, without becoming overly reliant on DevOps and data engineering. Data engineers can now focus on features rather than building and maintaining code-driven ETL flows.
ironSource successfully built an agile and versatile architecture with Upsolver and AWS data lake tools. This solution enables data consumers to work independently with data, while significantly improving data freshness, which helps power both the company’s internal decision-making and external reporting.