
Explore our expert-made templates & start with the right one for you.
How to Improve AWS Athena Performance: The Complete Guide
-
 Eran Levy
Eran Levy
- Cloud Architecture
- June 6, 2022
This article is part of our Amazon Athena resource bundle. If you want a ton of additional Athena content covering partitioning, comparisons with BigQuery and Redshift, use case examples and reference architectures, you should sign up to access all of our Athena resources FREE.
Amazon Athena is Amazon Web Services’ fastest growing service – driven by increasing adoption of AWS data lakes, and the simple, seamless model Athena offers for querying huge datasets stored on Amazon using regular SQL.
However, Athena is not without its limitations: and in many scenarios, Athena can run very slowly or explode your budget, especially if insignificant attention is given to data preparation. We’ll help you avoid these issues, and show how to optimize queries and the underlying data on S3 to help Athena meet its performance promise.
Athena is the most popular query engine used with Upsolver SQLake, our all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for data in motion, whether in event streams or frequent batches. SQLake automates everything else, including orchestration, file system optimization and all of Amazon’s recommended best practices for Athena. To give it a try you can execute sample Athena pipeline templates, or start building your own, in Upsolver SQLake for free.
What is Amazon Athena?
Amazon Athena is an interactive query service, which developers and data analysts use to analyze data stored in Amazon S3. Athena’s serverless architecture lowers data platform costs and means users don’t need to scale, provision or manage any servers.
Amazon Athena users can use standard SQL when analyzing data. Athena does not require a server, so there is no need to oversee infrastructure; users only pay for the queries they request. Users just need to point to their data in Amazon S3, define the schema, and begin querying.
However, as with most data analysis tools, certain best practices need to be kept in mind in order to ensure performance at scale. Let’s look at some of the major factors that can have an impact on Athena’s performance, and see how they can apply to your cloud stack.
Understanding Athena Performance
Athena scales automatically and runs multiple queries at the same time. This provides high performance even when queries are complex, or when working with very large data sets. However, Athena relies on the underlying organization of data in S3 and performs full table scans instead of using indexes, which creates performance issues in certain scenarios.
SQLake Brings Free, Automated Performance Optimization to Amazon Athena Users
The code below showcases (using sample data) the process of ingesting raw data from S3 and optimizing it for querying with Amazon Athena. By following the steps in this code, you can easily see how to properly prepare your data for use with Athena and start taking advantage of its powerful query capabilities.
/* Ingest data into SQLake */
-- 1. Create a connection to SQLake sample data source.
CREATE S3 CONNECTION upsolver_s3_samples
AWS_ROLE = 'arn:aws:iam::949275490180:role/upsolver_samples_role'
EXTERNAL_ID = 'SAMPLES'
READ_ONLY = TRUE;
-- 2. Create an empty table to use as staging for the raw data.
CREATE TABLE default_glue_catalog.database_5088dd.orders_raw_data()
PARTITIONED BY $event_date;
-- 3. Create a streaming job to ingest data from the sample bucket into the staging table.
CREATE JOB load_orders_raw_data_from_s3
CONTENT_TYPE = JSON
AS COPY FROM S3 upsolver_s3_samples BUCKET = 'upsolver-samples' PREFIX = 'orders/'
INTO default_glue_catalog.database_5088dd.orders_raw_data;
-- 4. Query your raw data in SQLake.
SELECT * FROM default_glue_catalog.database_5088dd.orders_raw_data limit 10;
How Does Athena Achieve High Performance?
Massively parallel queries
Athena carries out queries simultaneously, so even queries on very large datasets can be completed within seconds. Due to Athena’s distributed, serverless architecture, it can support large numbers of users and queries, and computing resources like CPU and RAM are seamlessly provisioned.
Metadata-driven read optimization
Modern data storage formats like ORC and Parquet rely on metadata which describes a set of values in a section of the data (sometimes called a stripe). If, for example, the user is interested in values < 5 and the metadata says all the data in this stripe is between 100 and 500, the stripe is not relevant to the query at all, and the query can skip over it.
This is a mechanism used by Athena to quickly scan huge volumes of data. To improve this mechanism, the user should cleverly organize the data (e.g. sorting by value) so that common filters can utilize metadata efficiently.
Treating S3 as read only
Another method Athena uses to optimize performance by creating external reference tables and treating S3 as a read-only resource. This avoid write operations on S3, to reduce latency and avoid table locking.
Athena Performance Issues
Athena is a distributed query engine, which uses S3 as its underlying storage engine. Unlike full database products, it does not have its own optimized storage layer. Therefore its performance is strongly dependent on how data is organized in S3—if data is sorted to allow efficient metadata based filtering, it will perform fast, and if not, some queries may be very slow.
In addition, Athena has no indexes—it relies on fast full table scans. This means some operations, like joins between big tables, can be very slow, which is why Amazon recommends running them outside of Athena.
We cover the key best practices you need to implement in order to ensure high performance in Athena further in this article – but you can skip all of those by using Upsolver SQLake. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. It ingests streaming and batch data as events, supports stateful operations such as rolling aggregations, window functions, high-cardinality joins and UPSERTs, and delivers up-to-the minute and optimized data to query engines, data warehouses and analytics systems.
Athena product limitations
According to Athena’s service limits, it cannot build custom user-defined functions (UDFs), write back to S3, or schedule and automate jobs. Amazon places some restrictions on queries: for example, users can only submit one query at a time and can only run up to five simultaneous queries for each account.
Athena restricts each account to 100 databases, and databases cannot include over 100 tables. The platform supports a limited number of regions.
7 Top Performance Tuning Tips for Amazon Athena
Broadly speaking, there are two main areas you would need to focus on to improve the performance of your queries in Athena:
- Optimizing the storage layer – partitioning, compacting and converting your data to columnar file formats make it easier for Athena to access the data it needs to answer a query, reducing the latencies involved with disk reads and table scans
- Query tuning – optimizing the SQL queries you run in Athena can lead to more efficient operations.
We’ll proceed to look at six tips to improve performance – the first five applying to storage, and the last two to query tuning.
1. Partitioning data
Partitioning breaks up your table based on column values such as country, region, date, etc. Partitions function as virtual columns and can reduce the volume of data scanned by each query, therefore lowering costs and maximizing performance. Users define partitions when they create their table.
Here’s an example of how you would partition data by day – meaning by storing all the events from the same day within a partition:
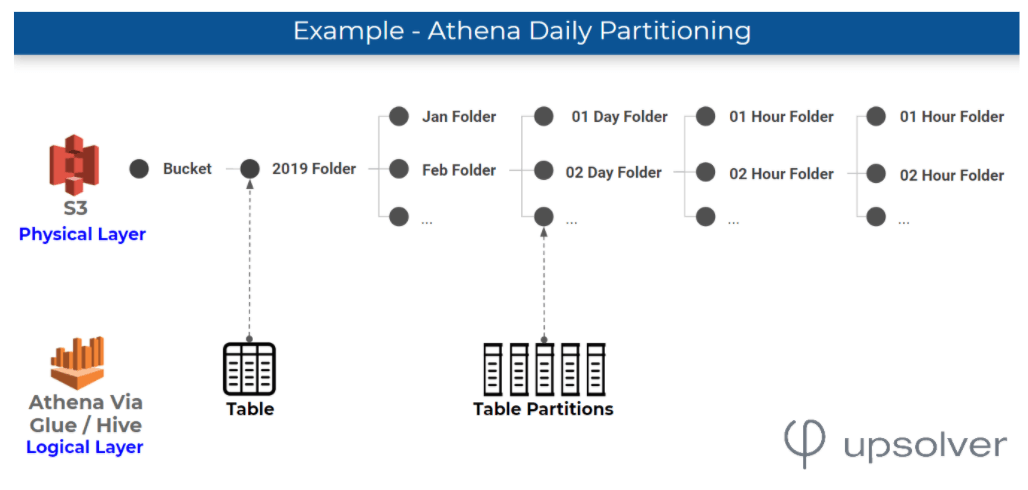
You must load the partitions into the table before you start querying the data, by:
- Using the ALTER TABLE statement for each partition.
- Using a single MSCK REPAIR TABLE statement to create all partitions. To use this method your object key names must comply with a specific pattern (see documentation).
You can read more about partitioning strategies and best practices in our guide to data partitioning on S3.
2. Compress and split files
You can speed up your queries dramatically by compressing your data, provided that files are splittable or of an optimal size (optimal S3 file size is between 200MB-1GB). Smaller data sizes mean less network traffic between Amazon S3 to Athena.
The Athena execution engine can process a file with multiple readers to maximize parallelism. When you have a single unsplittable file, only one reader can read the file, and all other readers are unoccupied.
It is advisable to use Apache Parquet or Apache ORC, which are splittable and compress data by default when working with Athena. If these are not an option, you can use BZip2 or Gzip with optimal file size. LZO and Snappy are not advisable because their compression ratio is low.
When you ingest the data with SQLake, the Athena output is stored in columnar Parquet format while the historical data is stored in a separate bucket on S3:
3. Optimize file sizes
Athena can run queries more productively when blocks of data can be read sequentially and when reading data can be parallelized. Check that your file formats are splittable, to assist with parallelism.
However, if files are very small (less than 128MB), the execution engine may spend extra time opening Amazon S3 files, accessing object metadata, listing directories, setting up data transfer, reading file headers, and reading compression dictionaries and more. If your files are too large or not splittable, the query processing halts until one reader has finished reading the complete file, which can limit parallelism.
Using Athena to query small data files will likely ruin your performance and your budget. SQLake enables you to sidestep this issue by automatically merging small files for optimal performance when you define an output to Athena, using breakthrough indexing and compaction algorithms.
To understand the impact of merging small files, you can check out the following resources:
- In a test by Amazon, reading the same amount of data in Athena from one file vs. 5,000 files reduced run time by 72%.
- In a series of benchmarks test we recently ran comparing Athena vs BigQuery, we discovered staggering differences in the speed at which Athena queries return, based on whether or not small files are merged.
- We’ve also covered this topic in our previous article on dealing with small files on S3, where we reduced query time from 76 to 10 seconds when reading 22 million records.
4. Join big tables in the ETL layer
Since Athena doesn’t have indexes, it relies on full table scans for joins. This is fine when joining two small tables, but very slow and resource-intensive for joins that involve large tables.
To avoid this, you would pre-join the data using an ETL tool, before querying the data in Athena.
To understand how this works, view this video demonstrating how to use SQLake to join store data with employee data before querying the data in Athena:
5. Optimize columnar data store generation
This is another feature that SQLake handles under the hood; otherwise you would need to implement manually in the ETL job you run to convert your S3 files to columnar file formats.
Apache ORC and Apache Parquet are columnar data stores that are splittable. They also offer features that store data by employing different encoding, column-wise compression, compression based on data type, and predicate pushdown. Typically, enhanced compression ratios or skipping blocks of data involves reading fewer bytes from Amazon S3, resulting in enhanced query performance.
You can tune:
- The stripe size or block size parameter—the stripe size in ORC or block size in Parquet equals the maximum number of rows that may fit into one block, in relation to size in bytes. The larger the stripe/block size, the more rows you can store in each block. The default ORC stripe size is 64MB, and the Parquet block size is 128 MB. We suggest a larger block size if your tables have several columns, to make sure that each column block is a size that permits effective sequential I/O.
- Data blocks parameter—if you have over 10GB of data, start with the default compression algorithm and test other compression algorithms.
- Number of blocks to be skipped—optimize by identifying and sorting your data by a commonly filtered column prior to writing your Parquet or ORC files. This ensures the variation between the upper and lower limits within the block is as small as possible within each block. This enhances its ability to be pruned.
6. Optimize SQL operations
Presto is the engine used by Athena to perform queries. When you understand how Presto functions you can better optimize queries when you run them. You can optimize the operations below:
ORDER BY
- Performance issue—Presto sends all the rows of data to one worker and then sorts them. This uses a lot of memory, which can cause the query to fail or take a long time.
- Best practice—Use ORDER BY with a LIMIT clause. This will move the sorting and limiting to individual workers, instead of putting the pressure of all the sorting on a single worker.
- Example— SELECT * FROM lineitem ORDER BY l_shipdate LIMIT 10000
Joins
- Performance issue—When you join two tables, specifically the smaller table on the right side of the join and the larger table on the left side of the join, Presto allocates the table on the right to worker nodes and instructs the table on the left to conduct the join.
- Best practice— If the table on the right is smaller, it requires less memory and the query runs faster.
The exception is when joining several tables together and there is the option of a cross join. Presto will conduct joins from left to right as it still doesn’t support join reordering. In this case, you should specify the tables from largest to smallest. Make sure two tables are not specified together as this can cause a cross join.
- Example— SELECT count(*) FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey
GROUP BY
- Performance issue—The GROUP BY operator hands out rows based on columns to worker nodes, which keep the GROUP BY values in memory. As rows are being processed, the columns are searched in memory; if GROUP BY columns are alike, values are jointly aggregated.
- Best practice—When you use GROUP BY in your query, arrange the columns according to cardinality from highest cardinality to the lowest. You can also use numbers instead of strings within the GROUP BY clause, and limit the number of columns within the SELECT statement.
- Example— SELECT state, gender, count(*) FROM census GROUP BY state, gender;
LIKE
- Performance issue—Refrain from using the LIKE clause multiple times.
- Best practice—It is better to use regular expressions when you are filtering for multiple values on a string column.
- Example—SELECT count(*) FROM lineitem WHERE regexp_like(l_comment, ‘wake|regular|express|sleep|hello’)
7. Use approximate functions
When you explore large datasets, a common use case is to isolate the count of distinct values for a column using COUNT(DISTINCT column). For example, when you are looking at the number of unique users accessing a webpage.
When you do not need an exact number, for example, if you are deciding which webpages to look at more closely, you may use approx_distinct(). This function attempts to minimize the memory usage by counting unique hashes of values rather than entire strings. The downside is that there is a standard error of 2.3%.
SELECT approx_distinct(l_comment) FROM lineitem;
Given the fact that Athena is the natural choice for querying streaming data on S3, it’s critical to follow these 6 tips in order to improve performance.
Data Preparation for Athena – Spark vs Alternatives
As we’ve seen, when using Amazon Athena in a data lake architecture, data preparation is essential. Applying best practices around partitioning, compressing and file compaction requires processing high volumes of data in order to transform the data from raw to analytics-ready, which can create challenges around latency, efficient resource utilization and engineering overhead. This challenge becomes all the more acute with streaming data, which is semi-structured, frequently changing, and generated at high velocity
The traditional go-to for data lake engineering has been the open-source framework Apache Spark, or the various commercial products that offer a managed version of Spark. While Spark is a powerful framework with a very large and devoted open source community, it can prove very difficult for organizations without large in-house engineering teams due to the high level of specialized knowledge required in order to run Spark at scale.
Alternatives to Spark, including SQLake, are geared more towards self-service operations by replacing code-intensive data pipeline management with declarative SQL. You can learn more about the difference between Spark platforms and the cloud-native processing engine used by SQLake in our Spark comparison ebook.
Athena Performance Benchmarks
We’ve run multiple tests throughout the years to see how Athena performance stacks up to other serverless querying tools such as Google BigQuery, as well as to try and measure the impact data preparation has on query performance and costs. You can see the results of these tests summarized here: Benchmarking Amazon Athena vs BigQuery.
You can see another example of how data integration can generate massive returns when it comes to performance in a webinar we ran with Looker, where we showcased how Looker dashboards that rely on Athena queries can be significantly more performant. You can watch the full webinar below.
(Note that in Upsolver SQLake, our newest release, the UI has changed to an all-SQL experience, making building a pipeline as easy as writing a SQL query. But the cloud-native processing engine and the superior performance are the same as that demonstrated in the webinar. Scroll down for more details.)
Athena vs Redshift Spectrum
Amazon Redshift Spectrum is another service that allows you query data on S3 using SQL, and to easily run the same queries on data stored in your Redshift cluster and perform joins between S3 and Redshift data.
As such, you would need to consider whether Redshift is the better fit for your case, and we’ve covered the key considerations on how to decide between Athena and Redshift in our previous article: Serverless Showdown: Amazon Athena vs Redshift Spectrum, reaching the following findings:
- For queries that are closely tied to a Redshift data warehouse, you should lean towards Redshift Spectrum.
- If all your data is on S3, lean towards Athena.
- If you are willing to pay more for better performance, lean towards Redshift Spectrum.
How to Improve your Query Performance by 10-15x
While SQLake doesn’t tune your queries in Athena, it does remove around 95% of the ETL effort involved in optimizing the storage layer (something you’d otherwise need to do in Spark/Hadoop/MapReduce). You can build reliable, maintainable, and testable processing pipelines on batch and streaming data, using only SQL, in 3 simple steps:
- Create connections to data sources and targets.
- Ingest source data into a staging location in your data lake where you can inspect events, validate quality, and ensure data freshness.
- Transform and refine the data using the full power of SQL. Then insert, update, and delete it in your target system.
SQLake abstracts the complexity of ETL operations. All the various best practices we covered in this article, and which are very complex to implement – such as merging small files and optimally partitioning the data – are invisible to the user and handled automatically under the hood. SQLake automatically manages the orchestration of tasks (no manual DAGs to create), scales compute resources up and down, and optimizes the output data. And it easily scales to millions of events per second with complex stateful transformations such as joins, aggregations, and upserts.
SQLake pipelines typically result in 10-15x faster queries in Athena compared to alternative solutions, and take a small fraction of the time to implement.
See for yourself. Try SQLake for free for 30 days – no credit card required. You can get started right away via a range of SQL templates designed to get you up and running in almost no time. Use your own data, or our sample data. Data pipeline templates include:
- S3 to Athena
- Kinesis to Athena
- Joining two data sources and outputting to Athena
And more.
Want to master data engineering for Amazon Athena? Get the free resource bundle:
Learn everything you need to build performant cloud architecture on Amazon S3 with our ultimate Amazon Athena pack, including:
– Ebook: Partitioning data on S3 to improve Athena performance
– Recorded Webinar: Improving Athena + Looker Performance by 380%
– Recorded Webinar: 6 Must-know ETL tips for Amazon Athena
– Athena compared to Google BigQuery + performance benchmarks
And much more. Get the full bundle for FREE right here.
Athena Performance – Frequently Asked Questions
Why is Athena running slowly?
Issues with Athena performance are typically caused by running a poorly optimized SQL query, or due to the way data is stored on S3. If data is not compressed or organized efficiently, some queries can take a long time to return. In addition, Athena has no indexes, which can make joins between big tables slow.
Is Athena cost effective?
Using Athena rather than a cloud data warehouse can reduce your overall cloud costs. Because Athena is serverless and can read directly from S3, it allows a strong decoupling between storage and compute. Efficient storage such as Parquet can help you reduce the amount of data scanned per query, further reducing Athena costs.
Is Amazon Athena scalable?
While Athena is frequently used for interactive analytics, it can scale to production workloads. A well-tuned implementation of Athena can scale to petabytes, and many current Upsolver customers use Athena to run BI and analytics workloads in place of data warehouses such as Redshift.
What is the difference between Athena and Redshift?
AWS Athena is a serverless query engine used to retrieve data from Amazon S3 using SQL. Amazon Redshift is a cloud data warehouse optimized for analytics performance. Redshift can be faster and more robust, but Athena is more flexible. (Learn more about the differences between Athena and Redshift.)
Published in:
Blog
,
Cloud Architecture
