
Explore our expert-made templates & start with the right one for you.
How to Work with Streaming Data in AWS Redshift
-
 Shawn Gordon
Shawn Gordon
- Streaming Data
- April 16, 2020
Building streaming data infrastructure on AWS? Learn how a leading AdTech company manages and transforms petabyte-scale streaming data using Amazon S3, Redshift, Athena and Upsolver in our free webinar with Amazon Web Services.
Amazon Redshift remains one of the most popular cloud data warehouses, and is still constantly being updated with new features and capabilities. Over 10,000 companies worldwide use Redshift as part of their AWS deployments (according to a recent press release).
However, Redshift is just one tool among an increasingly diverse set of platforms, databases and infrastructure at the disposal of today’s data architect. Hence, it is important to understand Redshift’s strengths and weaknesses in order to effectively allocate resources and workloads in any particular scenario.
In this article we will look at streaming data storage and analytics and explain if, when and how to use Redshift for streaming use cases. For another solution to streaming use cases with Redshift, check out our use case with Amazon Redshift Streaming Ingestion.
When to use Redshift for streaming data
Streaming data is data generated from sources such as IoT devices, app interactions, and server logs – a continuous stream of semi-structured data, typically in JSON or XML format, transmitted in real-time or near real-time over the world wide web. Organizations want to analyze this data for reporting, analytics and data science purposes.
In our comparison between Redshift and Athena, we offered a few general guidelines to help you decide whether Redshift is appropriate for a specific scenario. To summarize what we wrote there, Redshift is best used when you need consistent performance for a set of well-defined queries, and are willing to allocate the appropriate human and hardware resources to the job. It can be faster and more robust than Amazon Athena, but also more expensive and complicated to manage.
When it comes to streaming data, we’ll want to keep both of these factors in mind: the costs of storing and querying this data in Redshift can be remarkably high due to the increased ETL effort in structuring the data for analysis, as well as the increased cluster sizes needed to store volumes of data that can often reach petabyte-scale (read more in our guide to Redshift pricing).
This doesn’t mean there’s no room for Redshift within our streaming data architecture; however, we will want to ensure we are using it only for those cases where we actually need high performance and availability, such as for operational dashboards or very complex queries that would be difficult to complete otherwise. Other use cases, such as ad-hoc analytics and data science, might be better suited for Amazon Athena, which reads data directly from S3.
Building the solution – from Kinesis streams to Redshift tables
Now that we understand when we’ll want to use Redshift, let’s see what the actual solution might look like.
As we’ve covered previously, the unique characteristics of streaming data – mainly the high volume and high velocity in which it is generated, and its semi-structured or unstructured format – pose unique challenges when it comes to building your data architecture.
A key component in our solution will be the data lake. We would like to reduce unnecessary costs and ETL work by only sending a relevant subset of the data to Redshift. We will keep the rest of the data, which might be useful for other analytic processes, on Amazon S3. S3 provides inexpensive and scalable object storage, which will be our landing zone and staging area before moving the data to the relevant services such as Athena, Redshift, or Sagemaker.
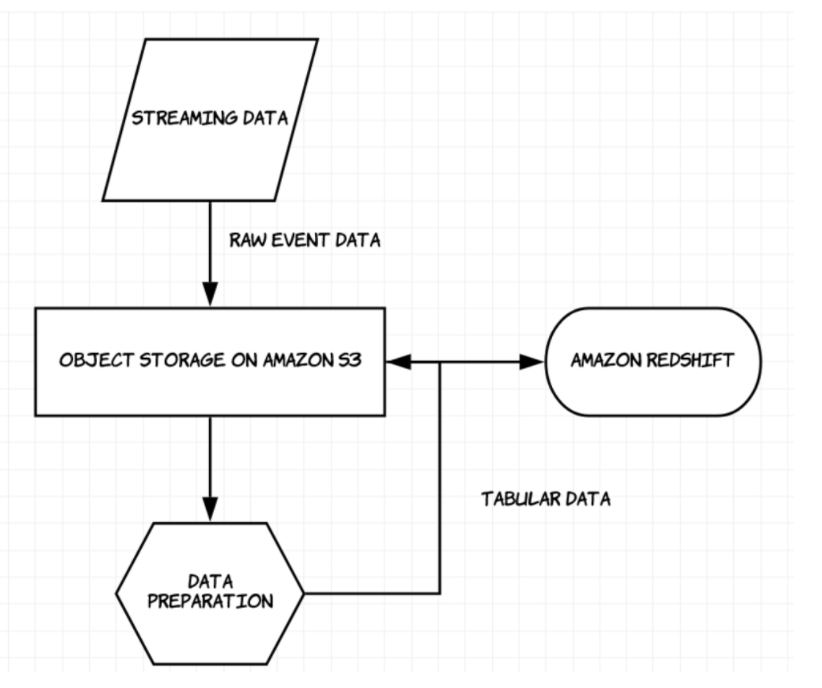
By building our solution around a data lake architecture, we can greatly increase the scale of data we work with in Redshift – for example, ironSource uses a similar architecture to process millions of events.

The ETL challenge
Before we can successfully query our data in Redshift, we need to turn it from semi-structured log files into relational tables that can be queried with SQL. There are various steps we need to address here:
- Schema detection for data sources: In order to understand the structure of the table we’ll be creating in Redshift, we need to understand what’s actually in the data – how events are captured, which fields have sparse data. To learn more about this topic, check out our previous guide to schema discovery.
- Handling nested sources: Data may come in various forms and shapes, including nested data such as JSON files. Redshift is a database and doesn’t support storing nested data. Moreover, we might want to store or query a partial subset of the nested data which is challenging to achieve without using external tools and coding to flatten the data.
- Transformations and enrichments including high-cardinality joins: To ensure optimal performance and costs, we will want to perform some of the ETL work before moving the data to Redshift. Using Redshift, we pay separately for compute and storage. As a result, we would like to optimize both. Performing high cardinality joins before moving the data to Redshift will enable us to utilize Redshift’s resources for other tasks such as querying our table rather for infrastructure development such as high cardinality joins.
- Conversion to Redshift naming convention and data types: Before loading data into Redshift, we need to ensure it adheres to one of the supported data types. Depending on how we are capturing our event data, some transformation could be required. For example, a field in the extracted data might be of type double which Redshift doesn’t support and will need to be converted to decimal type before stored in the Redshift table.
In our solution we will be using various features of Upsolver to address these challenges, but if you are writing your ETL code using Spark/Hadoop, AWS Glue or Kinesis Firehose, you will need to ensure that the job you are writing takes these issues into account.
Reference Architecture and Solution Overview
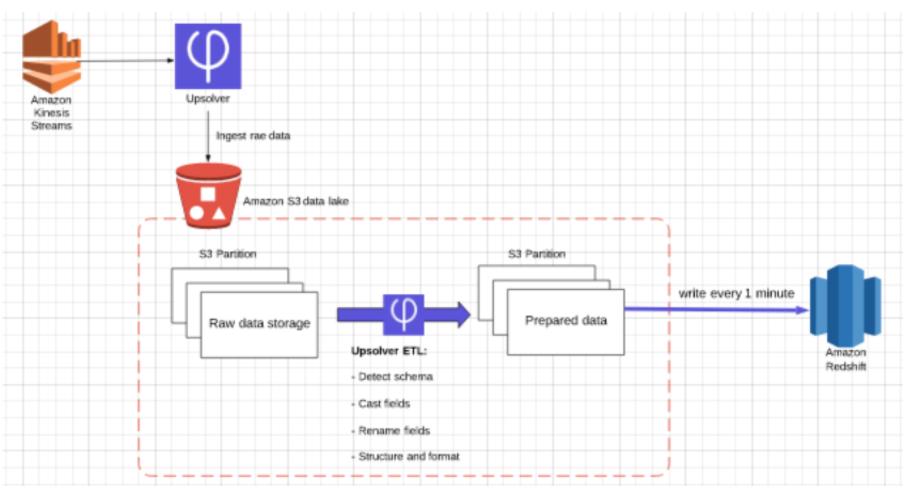
In our solution, streaming data is being processed using Amazon Kinesis. Upsolver is used to ingest the data into S3 as optimized parquet while ensuring exactly-once processing, and enabling the user to create a partitioning strategy and set different retention policies.
In this case we will ingest all the raw event data, then prune and clean the data before loading it onto Redshift. We can use the same data to create separate ETL flows to services such as Amazon Athena and Amazon Sagemaker, and then either delete the historical data or save it for backfill/replay purposes,
In the transformation stage, we will use Upsolver to create the analytics-ready data which will then be written directly to Redshift tables. Based on the original data, some of the transformations we might want to incorporate in this stage could include:
- Casting data types to support Redshift’s supported data types
- Aligning field names in the data to Redshift column naming conventions
- Removing unused fields to reduce storage requirements on Redshift
- Joining two streaming sources
Developing your ETL in Upsolver can be done both using the UI or SQL. In your ETL you simply map the required fields from your raw data to the desired columns in your Redshift table. Writing your transformed data to Redshift is being done by configuring an Output to Redshift in Upsolver which takes a few minutes to implement.
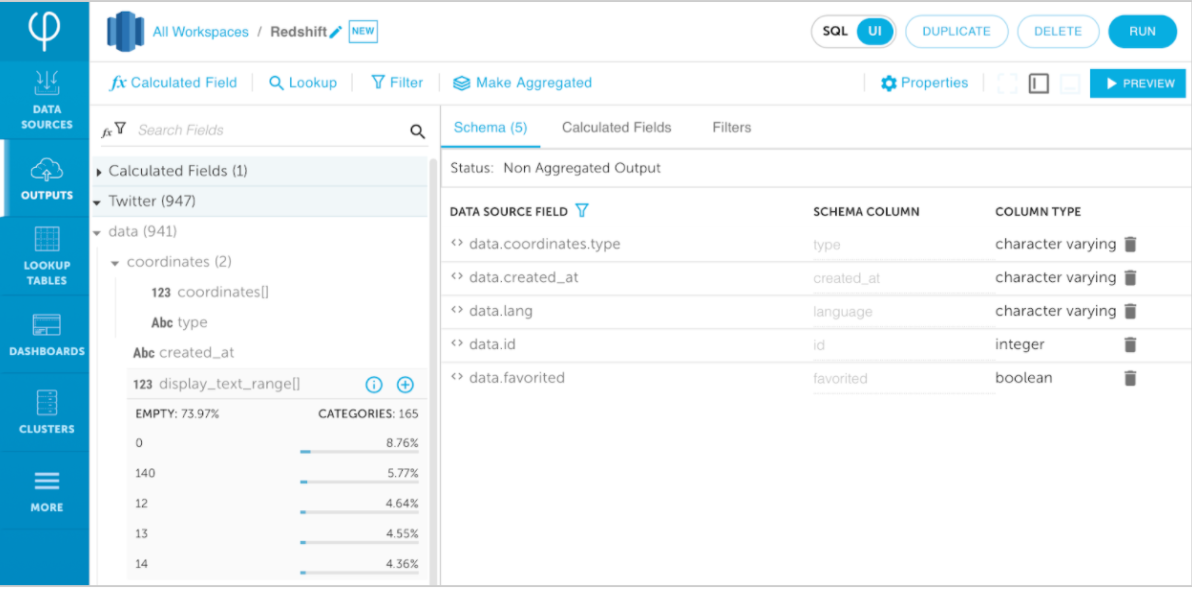
Once we have the transformed data, we can choose when to write it Redshift, for example every 1 minute. Upsolver will then write the data directly to the Redshift table in the interval that we’ve chosen.
And that’s it: We now have an end-to-end ETL pipeline that ensures we have fresh, clean and structured data in Redshift – with minimal infrastructure spend and without spending weeks coding complex ETL jobs or fiddling with manual workflow orchestration.
Learn more about ETLing streaming data to Redshift
If you want to see a real-life example of one company using Redshift to work with streaming data at petabyte scale, check out our on-demand webinar with Amazon Web Services and ironSource: Frictionless Data Lake ETL for Petabyte-scale Streaming Data; or learn more about how to build a data lake in our guide to data lake architecture.
Published in:
Blog
,
Streaming Data