
Explore our expert-made templates & start with the right one for you.
Redshift Pricing Explained + Controlling Costs with ETL
-
 Jerry Franklin
Jerry Franklin
- Cloud Architecture
- November 30, 2021
This article is an excerpt our Comprehensive Guide to Understanding and Reducing Redshift Costs. You can get access to the full document with 3 additional videos right here.
Amazon Redshift is a fully managed and scalable data warehouse service in the cloud. Redshift’s speed, flexibility, and scalability, along with a frequent stream of new features and capabilities from AWS, make it one of the most popular data warehouses in use.
But Redshift can be expensive. Its pricing model can come across as byzantine. Examining the nuances, options, and methods of Redshift charges is time-consuming. It can be hard to feel confident that you have optimized your Redshift bill.
In the first part of this article, we’ll help you understand the different pricing methods available, as well as the different performance/cost tradeoffs, so you can identify with confidence how best to spend your Redshift budget appropriately and predictably. In the next part, we’ll review some of the tools and methods you can use to track your Redshift usage and reduce and maximize your Redshift spend.
Note that our intent is not to discourage you from using Redshift which, as we earlier indicated, is powerful, versatile, and highly scalable. Rather, we want to help you envision how you can most cost-effectively leverage the speed and power of Redshift (and, by extension, any data warehouse solution).
Data warehouse costs are only part of your larger data platform. Check out our recent guide to data platform costs to learn more about how to understand and reduce the total cost of ownership for your data infrastructure.
Surveying the many pricing options in Amazon Redshift
Here’s a scene we can envision, after a DevOps or data practitioner explores the cost of configuring and deploying Redshift and reports back to management:
BOSS: OK, Dude. What’d we find out about Redshift?
DATA DUDE: Well, we can pay by the hour on demand, unless we want to reserve compute resources in advance and get a discount.
BOSS: Great – let’s go for the discount.
DATA DUDE: OK. But then we have to figure out whether to pay up front partially or fully, or not at all, so we’ll need to closely analyze and monitor current and anticipated usage to make the most cost-effective decision.
BOSS: Great – we’ll do that.
DATA DUDE: OK. But before we do that we have to figure out if we want a dc2-type node or an RA3-type node, though before we do THAT we should determine whether we want a large node or a more expensive extra-large node.
BOSS: Great – we’ll do – wait – what’s the difference?
DATA DUDE: Well, the DC2 large and the RA3 extra large are more cost-effective in some cases, although the DC2 extra-large and the RA3 large are a better choice in other cases. In either case we can save money by having fewer nodes.
BOSS: So let’s have fewer nodes.
DATA DUDE: Sure, but it’s hard to scale down and easier to pay for nodes we’re not fully using.
BOSS: But – why should we pay for resources we’re not using?
DATA DUDE: Exactly. Also don’t forget about where our data resides because Redshift charges higher prices to store data in certain regions but also charges to transfer it to other regions.
BOSS: But compliance and governance – we don’t always have flexibility –
DATA DUDE: We can also save money by using Redshift Spectrum to query data in our data lake instead of in Redshift itself, although that costs money per volume of data queried to use Redshift Spectrum, too, so we want to watch how much data we’re querying, though we can be more efficient and get free credits by choosing concurrency scaling –
BOSS: Concurrency scaling.
DATA DUDE: But we should be careful not to exceed our credits or we’ll be charged by the second.
BOSS: Um – uhhh –
DATA DUDE: And no matter what, don’t forget about the technical overhead involved in managing and maintaining clusters, and no matter what again we can save a lot of money by fine-tuning our queries, and we might also consider Redshift Serverless, which Amazon just came out with, to manage capacity when our usage spikes, and – boss? Boss?
BOSS: (staring off into space)
We’ve seen Apache Airflow DAGs a lot less complex than that.
But we can flatten this out a bit and help clarify just what your options are.
Let’s get started.
How Redshift charges
Here we break down Amazon Redshift pricing accordingly:
- Base pricing
- Types of nodes
- Number of nodes
- Vehicles for reducing pricing
- Maintenance costs
Amazon Redshift base pricing
First, foremost, and generally speaking, Redshift charges by the hour, based on the type and number of nodes in your cluster. (There are ancillary charges that can be significant; we cover those later in this blog.) A Redshift node is a finite set of resources optimized for compute and storage. A node includes an engine and a database.
- Use the native Redshift query engine to query data stored in Redshift; this engine is based on PostgreSQL.
- Use Redshift Spectrum, a serverless query processing engine, to query data stored outside of Redshift (in Amazon S3, for example). Redshift Spectrum costs extra and has its own pricing scale.
Where pricing can get confusing is in the variety of pricing models: by the hour based on your node usage (on demand), by the number of bytes scanned (Redshift Spectrum), by the time spent over your free daily credits (concurrency scaling), or by committing to an annual plan (reserved instance).
Types of Amazon Redshift Nodes
There are 2 types of nodes:
- Dense compute (DC2)
- RA3 (these supersede the earlier dense storage nodes, as per Amazon’s recommendation)
Each type comes in different sizes:
- Large
- Extra large
- Extra large plus (for RA3-type nodes)
If you frequent Starbucks, you could think of them as Tall, Grande, and Vente.
Number of Redshift nodes to purchase
How many nodes do you need, and of what type? That’s dictated by the amount of data you’re working with.
- DC2-type nodes are optimized for faster queries and are preferable for smaller data sets.
- RA3-type nodes are more expensive than dense compute but are better optimized for storing large amounts of data. They include a feature called Managed Storage, in which they offload less-frequently-used data to less-expensive Amazon S3 object storage.
- With RA3-type nodes only, you pay for compute and storage separately: per hour for compute, plus per GB per hour for data stored on the nodes.
- Extra large nodes offer more storage, use HDD storage instead of SSD storage, and on average cost roughly between 8x and 20x more than large nodes.
Amazon Web Services recommends DC2-type nodes for datasets <1TB uncompressed. For fast-growing datasets, or datasets >1TB, AWS recommends RA3-type nodes.
Adding nodes, of course, can improve query performance as well as expand storage capacity. Be sure to factor in query performance and disk I/O requests in addition to data volume. Also be aware you cannot mix and match node types.
The base cost of your Redshift cluster generally is determined by node type x n nodes x hours in use. Simple, enough. Head to Amazon’s Redshift site for the latest pricing. But here, too, there are multiple variations on the theme.
Vehicles for reducing Amazon Redshift pricing
- Reserved instance. You get a discount for reserving a certain amount of work in advance. The discount varies widely – from 20% off all the way up to 76% off – based on:
- whether you commit to a 1- or 3-year increment
- whether and how much you pay up front. You can make a full payment, a partial payment, or no payment.
- Concurrency Scaling. Each cluster earns up to one hour of free credits per day. If you exceed that, Amazon charges the per-second on-demand rate. AWS recommends concurrency scaling as a way to maintain high performance even with “…virtually unlimited concurrent users and concurrent queries.”
- Use Redshift Spectrum to query data directly in S3. Spectrum is an additional cost – per byte scanned, rounded up by megabyte, with a 10MB minimum per query. But it’s intended to more than compensate for that cost by minimizing the data you must load into Redshift tables (as opposed to leaving it in dirt cheap S3 storage). In addition, you can prepare the data on S3 such that your queried data is small and thus your Spectrum queries incur a minimal load.
- Cluster location. Redshift’s pricing varies widely across regions. Clusters in Asia cost more than clusters in the U.S. In addition, Amazon adds data transfer charges for inter-region transfer and for every transfer involving data movement from a non-AWS location.
Amazon Redshift maintenance costs
Finally, there are other costs to factor in when deploying and maintaining Redshift:
- If your data volumes are dynamic – often the case with high volumes of streaming data – you may find yourself investing significant engineering time in cluster management.
- Much maintenance in Redshift is time-consuming, executed manually via a command line interface. Take into account the staffing resources you will spend running your commands, updating rows, and monitoring your clusters for better performance.
Given the above, Amazon recently introduced Redshift Serverless. Redshift Serverless is intended to get you up and running quickly by automatically provisioning the necessary compute resources. It automates cluster setup and management and makes it much simpler to manage variable capacity. Redshift Serverless introduces yet more pricing methods:
- per second for compute (measured in this case in Redshift Processing Units, or RPUs)
- per amount of data stored in Redshift-managed storage. Amazon says this is similar to the cost of a provisioned cluster using RA3 instances.
How to hone in on the right Redshift cluster size for your situation
One important thing you can do is identify the scale-cost-performance combination most appropriate for your organization. These 3 factors are usually in tension and can help you make intelligent trade-offs.
- Is latency your primary concern? Adding nodes to a cluster gives more storage space, more memory, and more CPU to allocate to your queries, enhancing performance in linear fashion (so an 8-node cluster, for example, processes a query 2x as fast as a 4-node cluster).
- Is cost your primary concern? You can try removing one or more nodes. You can use AWS Cost Explorer (explained a bit further down) to calculate whether you have enough capacity in other nodes to pick up the slack.
- Is scale your primary concern? Again, add enough nodes to cover any anticipated usage spikes (though you may wind up paying for compute resources that sit idle much of the time).
It’s important to measure your current data usage and estimate future usage as accurately as possible, so you’ll know how much Redshift to buy. Amazon provides a couple of tools to help you analyze your usage and adjust your spend accordingly:
- AWS Cost Explorer, to visualize, understand, and manage your AWS costs and usage over time.
- Amazon Redshift Advisor, to identify undesirable end user behaviors such as large uncompressed columns that aren’t sort key columns, and come up with recommendations to improve performance and reduce cost. Redshift Advisor recommendations are viewable on the AWS Management Console.
Reigning in Redshift costs
There are multiple pathways for keeping Redshift costs in check. In the next section, we go into greater detail on the tools, technologies, and techniques you can use to wring the maximum amount of value from your Redshift investment.
Understand your Amazon Redshift usage patterns
Know as best you can how you’re using your data warehouse. And forecast as best you can how you’ll be using it in the foreseeable future. This helps you focus on just what needs changing.
- Minimize compute by “right sizing” your data set to match requirements. Do you store raw data when per-second aggregates would be sufficient? Do you store per-second aggregates when all of your reporting and query responses only require hourly or daily results? The most important factor in cost reduction is minimizing compute time. The easiest way to do this is to right size your data. Aggregate rows to what is needed and filter columns that are rarely or never used.
- Use reserved instances if you have steady workloads. Reserve a set number of nodes for 1 or 3 years – 3 years gets you a bigger discount — and calculate whether a partial or full upfront payment is preferable.
- Turn off or pause unused clusters. For Redshift clusters used for development, testing, staging, or any other non-24×7 purpose, you can turn them off when you don’t need them. For clusters in production, use the pause and resume feature in the Redshift console to suspend billing when nodes are not in use over consecutive hours. You can do this manually, or on a set schedule. The underlying data structures remain intact.
When you pause a Redshift cluster, it may take several minutes for the cluster actually to cease working; likewise, it may take several minutes for the cluster to resume processing after it has been paused. But Amazon stops charging you from the moment the pause begins, and doesn’t resume charging until the cluster is fully back in action. Redshift also completes any outstanding queries before any pause takes effect.
Finally, you can also shut down a cluster. Before shutting it down you can opt to create a final snapshot. To resume running the cluster you can restore that snapshot and resume querying data from it; anecdotally, this can take up to 30 minutes or more. Tools such as AWS CloudFormation can help you automate the restore operation.
- Minimize data transfer charges. While not always practical, try to keep all your deployment and data in as few regions as possible. Where this isn’t possible – for example, to comply with data residency requirements – factor in data transfer costs when you budget. You can also consider aggregating the data – say from minutes to hours or days – before transferring it to reduce the overall volume-based transfer cost.
- Use available tools. Amazon provides tools that give you visibility into your Redshift usage:
- Amazon Web Services Cost Explorer enables you to view and analyze your costs and usage for up to the prior 12 months, and also forecast how much you’re likely to spend for the next 12 months. Then it recommends what Reserved Instances to purchase. Viewing data is free of charge; there’s a fee for accessing your data via the Cost Explorer API.
- Redshift Advisor analyzes performance and usage metrics for your cluster. It recommends changes you can make to improve cluster performance and decrease operating costs.
- The Amazon Redshift Partners site lists more than 100 partner companies that provide complementary or supplementary products and services.
- Consider offloading ETL to the data lake. While you can transform data into smaller tables for analytics inside your data warehouse, a data lake can usually handle the job much more cost-effectively. If you find data lake processing a daunting subject, consider Upsolver, which is a tool that enables you to build continuous pipelines to your data warehouse using only SQL to define the transformations.
What to look for to right-size your Amazon Redshift clusters
In addition to right-sizing your data, you can also rely on certain usage statistics to determine whether to add or remove nodes from your Redshift cluster:
- Current and historic disk utilization. Keep disk utilization below 70-80% to leave room for query execution. If it’s much lower than this you might be able to downsize without impacting users.
- Workload management concurrency and queue wait-times. Determine whether queries are sitting around waiting for cluster resources to become available. Use your query response SLA to guide whether to resize.
- Percentage of disk-based queries. Examine the breakdown of memory usage per queue. Typically, keep the percentage of disk-based queries to less than 10% as data retrieval from disk creates a severe performance impact.
Finally, other AWS tools and services can help you assess your cluster usage. But these tools’ nomenclature alone could add to the confusion. For example, in addition to Amazon Cloudformation (mentioned above), Amazon Cloudwatch automatically collects a range of cluster metrics and makes them available via a Web-based monitoring interface. Finally there are third-party tools as well; companies such as SumoLogic and DataDog also promote comprehensive Redshift monitoring (among other capabilities).
Identify which data to store where
Store as much data as you can in cheap object storage (Amazon S3). Understanding your total data volume can lead you to the best cost/performance combination of node type and cluster size.
- Keep operational data in Redshift. This is the most current and frequently-queried data. Redshift stores data in tables and enforces schema-on-write, so using its native query engine provides good performance.
- Pre-aggregate when you can. Rarely is the granularity of the raw data equivalent to the granularity required for analytics. For example, do you need seconds, or are hours sufficient? Do you need Postal Code, or will Metro Area or State/Province suffice?
- Keep all other data in raw S3 storage. Store historical data, and data you don’t query often, more economically in a data lake. Keep it prepared into smaller tables based on your likely query needs, and use Redshift Spectrum when you do wish to access this data.
- Also store unstructured or semi-structured data – such as raw event data captured from clickstreams, IoT sensors, or online advertising – especially streaming data – in S3. When you need to query it, use a third-party tool such as Upsolver to transform this schemaless data and then load it into Redshift. This saves significant time and money you’d otherwise spend on coding ETL, workflow orchestration, and so on.
- Delete orphaned snapshots. Redshift backups are in the form of snapshots. If you delete clusters, be sure to delete these snapshots.
- Vacuum tables. Be sure to run vacuum periodically after deletes, as Redshift doesn’t do this automatically. This saves space and, by extension, cost.
Optimize your data for faster, cheaper Redshift queries
Fine-tuning your queries can greatly improve cluster performance. In turn this can significantly lower your Redshift compute costs. If you’re using Spectrum to query data in AWS S3, commit to common best practices in data processing to control query costs.
Optimizing queries on cloud object storage entails a range of best practices in data transformation preparation. It can be challenging to do this via manual coding using Scala, Python, and so on, but there are third-party tools you can take advantage of to automate the process and save significant time and effort. Depending on your requirements you can do this in advance. This gives you the added benefit of using a different or supplemental query tool in addition to Redshift Spectrum, such as Athena, depending on the use case.
These best practices include:
- Optimizing the storage layer, including partitioning, compacting, and converting into columnar Parquet.
- Converting data into generic columnar Parquet files.
- Compressing the data to save space and improve performance, which could reduce the number of nodes you require.
- Compacting data such that file sizes are as big as possible while still fitting into memory.
- Partitioning wisely so as to best answer the queries being run.
- Flattening data. Redshift does not support nested data types (such as JSON files), meaning it’s up to you to get nested data ready for querying.
- Vacuuming on S3 during the data prep process (reducing the data in S3 before it goes to Redshift).
Specific examples of data preparation in Redshift could include:
- Casting data types to support Redshift’s supported data types.
- Aligning field names in the data to Redshift column naming conventions.
- Removing unused fields to reduce storage requirements on Redshift.
- Aggregating data to match query requirements while reducing Redshift storage and compute.
- Joining two streaming sources.
- Performing high cardinality joins before moving the data to Redshift, so you can use Redshift’s resources for querying rather than for infrastructure development.
Amazon Redshift and Upsolver – a complementary pair
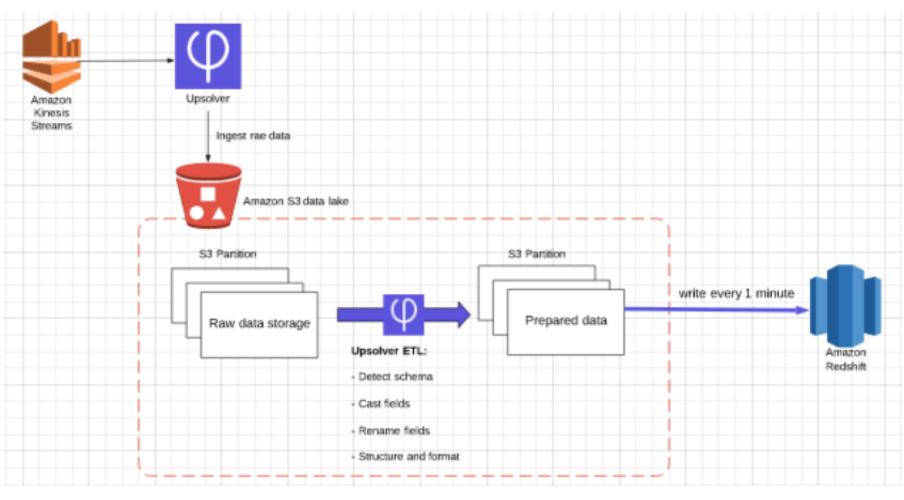
Upsolver is a continuous pipeline platform that lets you build data preparation using only SQL, run the processing on affordable EC2 Spot instances, and output live tables to Amazon Redshift. Upsolver provides click-to-connect data sources and outputs, declarative pipeline construction with just SQL and a visual IDE, and automated orchestration, table management, and optimization. These make it easy to implement continuous production pipelines at scale – for Redshift, standalone query engines, data stores, stream processors, and so on. And all of the best practices mentioned above – which are very complex to implement – are handled automatically, invisible to the user.
More information
Peruse the Upsolver Web site for much more information about the Upsolver platform, including how it automates a full range of data best practices, real-world stories of successful implementations, and more.
To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo
Or just see for yourself how easy it is: try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Cloud Architecture
