
Explore our expert-made templates & start with the right one for you.
Eliminating the Ugly Plumbing of Data Lake Pipelines
-
 Jerry Franklin
Jerry Franklin
- Data Lakes
- September 24, 2021
When you want to be Shigeru Miyamoto, but are stuck in the backroom drawing Mario or Luigi
Data lake complexities leave too many engineers treading water, manually coding, configuring and optimizing pipelines instead of working on projects that drive business value.
It doesn’t have to be that way. Instead of feeling like one of the plumbers in Donkey Kong, you can gain the freedom to be more like Miyamoto, the guy who created the game.
No architect is happy just putting up drywall or fitting pipes. Why should you be happy spending your time writing, testing, and debugging Scala and Python code, or struggling with numerous Spark configuration settings, or trouble-shooting the innards of someone else’s code in a fault production pipeline? Especially when instead you could be engaged in far more creative and business-impactful work.
Let’s review why this is the case, and then discuss how things can change.
The promise and proliferation of data lakes
Precise estimates vary. But most researchers agree the global data lake market is already well north of $5 billion; by mid-decade they forecast it to more than quadruple, exceeding $20 billion.
The explosion in data volume is one obvious reason. But cost savings is another. Companies realize it’s far too expensive to rely on their data warehouse – cloud or otherwise – for storing and processing petabyte-scale data sets. Many of these companies already use cloud object storage and affordable data lake processing for their big data.
Another reason is the open nature of data lakes. Using a cloud object store and the cloud provider’s data catalog as the lowest common denominator provides more flexibility than cloud data warehouses or databases, which tend to be full-stack, vendor-specific solutions. You can directly query data in the lake, or treat it as a staging area for refined data tables that are consumed by multiple external systems.
Plumbers?! Why do data lakes need plumbing?
Put simply: data lakes are not like databases. Besides the timestamp for the file, there’s no inherent organization to the data stored in a lake. They’re just files, sitting in object storage. And there’s no built-in mechanism for getting the data from where it’s stored (the lake) to where it can provide value (ML applications, query engines, and so on). Databases (and, to a lesser extent, data warehouses) natively provide structure and functionality that in a data lake you must implement manually. You can also query the data where it’s stored.
That in turn often leads to a dilemma:
- Store data you are never able (practically) to query or analyze
- Store or process a subset of the incoming data, thereby limiting its value (for example, not keeping enough historical data for a proper ML model)
- Blow past your budget – way past it – to pay for the specialized coding expertise in Scala, Python, and more to get the insight and intelligence you seek.
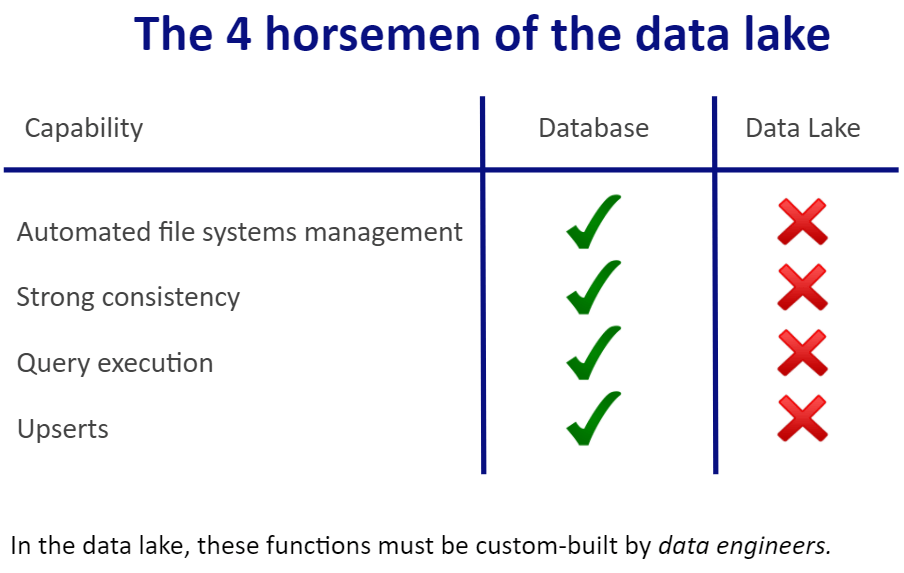
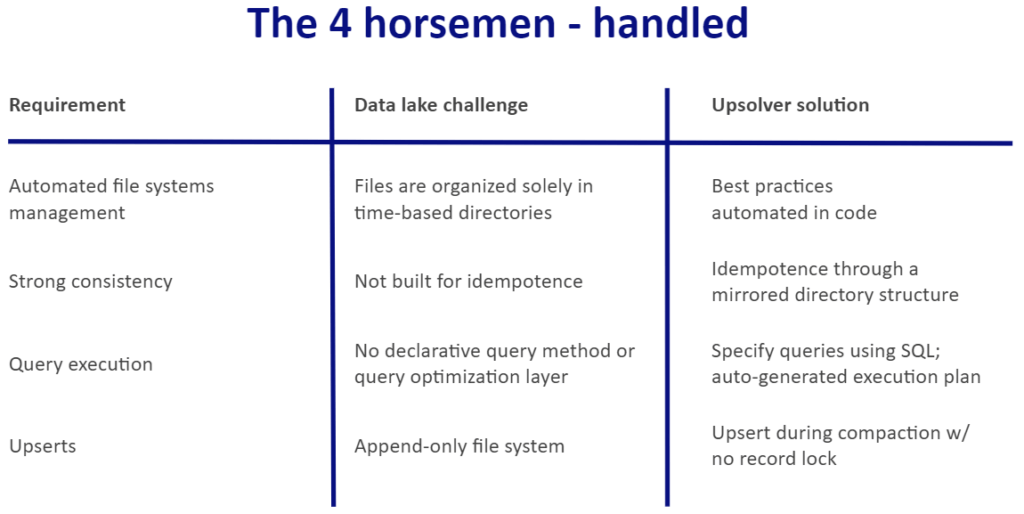
So to wring all the value you want from your data lake, you need plumbing. Still, it’s not an open-ended job. If you can address the four areas below – easier said than done, as you’ll see – you’ll reap the promise of your data lake:
- Automate file system management
- Ensure strong data consistency
- Eliminate pipeline engineering overhead
- Enable upsert capability
For each of these we will describe the challenge, how to address it manually, and then how Upsolver provides an automated solution.
1. Automate file system management in a data lake
Without proper file system management in your data lake, you’ll have latency issues with your queries. That’s because query engines must open, process and manage a lot of files to answer a query. There’s no processing engine that has enough cores of CPU to process hundreds and thousands of files at the same time.
From a database perspective, automated file system management refers to tables. The tables represent data held in files on some file system, but the database abstracts that all away when you insert or delete or truncate a table. In doing this it handles a lot of details underneath – essentially the management of the files that represent these tables, including how the files are distributed, the use of write-ahead logs, deleting stale and temporary files, and much more.
In a data lake, this is not the case. You must deal with where data goes, and how it gets there.
First and foremost, there’s compaction of small files to minimize query latency. Query engines perform poorly when faced with opening a large number of files in cloud object storage to answer a query. Streaming data arrives in huge numbers of tiny chunks so as to maintain freshness, and is distributed across many different folders. As the data volume expands, query performance degrades. To combat this, you must rewrite all those small files into larger files and move data around to accommodate – all without interrupting the steady flow of new data streaming in.
Databases create indexes that point to the exact data you’re seeking. But for data lakes, it’s necessary to pre-filter your data from a petabyte scale to perhaps a gigabyte or terabyte scale. You do this by putting different types of data in different folders. Then, when your WHERE clause includes the prefix of the partition, the system knows where to go. It gets really tricky when you have late-arriving events or when you’re partitioning by a high-cardinality event ID. You must know how to take your stream and distribute it to many different files. And this compounds the small file problem.
In addition, you must manually convert data from common source formats such as .csv or .json into an analytics-friendly columnar format such as Parquet. This is a delicate and complicated task to perform manually.
You can start to see how manual file management quickly becomes detailed, complex, and time-consuming.
Manual solution to data lake file system management
There isn’t a straightforward approach to manually constructing a data lake file system that reduces, much less eliminates, plumbing. The problem isn’t really one of code; the code is straightforward – if time-consuming – to write. It’s the LOGIC that’s complicated. In other words, the challenge is one not of construction, but of design.
File system management at data lake scale requires the deep domain knowledge and experience of specialized big data engineers. When processing slows or hangs, or when data gets lost or duplicated due to failure of components in the data flow, it is slow and painful to troubleshoot. There’s virtually no easy way to list files and track destinations, nor are there robust debugging tools; visibility simply isn’t sufficient for the degree of precision required, especially at scale.
So less is more, but not in a good way. Less thought, experience, and hazard avoidance in manual data lake design leads to more and more ugly plumbing.
Upsolver solution – best practices automated in code
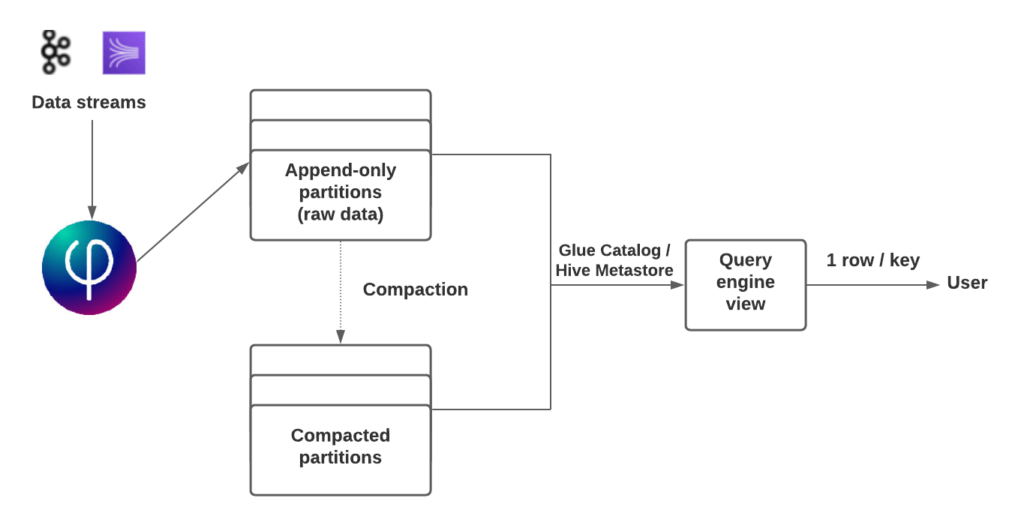
To address this vexing problem, Upsolver automates a range of data lake file preparation and management best practices. While we cover this in greater depth elsewhere, here’s one brief example – how Upsolver performs continuous compaction without interrupting the incoming stream:
- As the data streams in, Upsolver writes the data to multiple partitions in the table.
- When a partition has too many files, Upsolver compacts the data, splits the stream, and starts writing to a new location in tandem with the compaction process.
- When the compaction completes, Upsolver switches the catalog – the Glue catalog or Hive metastore – to point to the new location for that partition.
- When all in-process queries that had been looking at the old data location complete, Upsolver deletes the data in the old partition.
2. Ensuring strong data consistency in a data lake
Reliable data processing requires there be no loss or duplication of data.
Databases are built to be strongly consistent; data lakes are only eventually consistent. So ensuring strong data consistency is tricky. The only way to ensure consistent results on a data lake is by conducting idempotent operations.
Databases are idempotent, but that’s because Oracle and other vendors devote significant resources to ensuring their databases provide the necessary consistency. It’s difficult if not near impossible for an organization to devote an equivalent amount of effort when building out its data lake.
An idempotent operation is an operation you can apply repeatedly without ever changing the result. If your pipeline consists strictly of idempotent operations, you get “exactly once” consistency. Otherwise, for example, a report run on a table may produce results that differ from a report run on the same table, but aggregated. To be strongly consistent, multiple views of the same data must be exactly the same.
The manual approach to data consistency
The issue here is one of the essence: your data lake infrastructure must be intrinsically, even genetically, idempotent. Building pipelines to be idempotent on Spark, Kafka, or Flink requires sizable engineering effort and deep experience. One small human error will result in lack of idempotence and potentially incorrect business decisions down the road. But human errors will happen in every project. The data pipelines will become increasingly costly to maintain with a high probability of dirty data down stream.
What does this mean in practice? It usually means that companies accept and operate with a certain level of data duplication or loss, assuming they lack the resources to test, to carefully construct the code base, and to carefully handle their data. It is extremely difficult to build and maintain idempotence at the code level.
But wait – there’s an answer!
Upsolver’s approach – idempotence through a mirrored directory structure
Upsolver is built from the ground up to be idempotent. And as it’s a full platform – it performs all data transformations, orchestration, and so on – it doesn’t rely on older technologies that are not natively idempotent.
Upsolver achieves idempotence via a robust time-based directory, and automatically maps the directory structure to precisely mirror the data lake file structure. Operating behind the scenes, Upsolver divides work a priori into processing tasks, with each processing task creating a file on S3. Each task in turn looks at a specific file in S3.
Think of it as a directory structure with multiple files, and a mapped directory mirroring both the directory structure and the number of files.
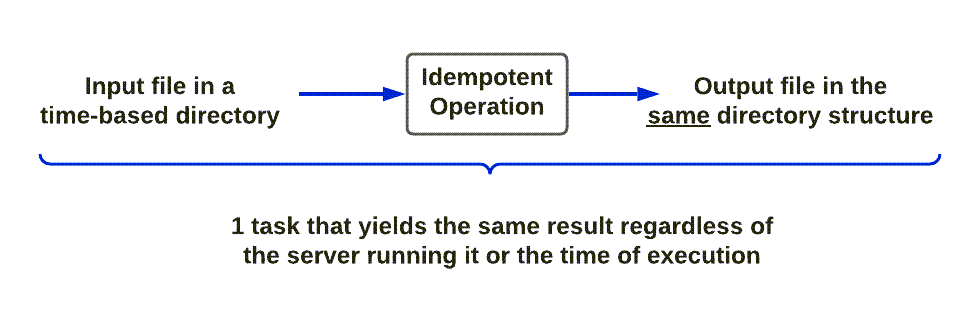
The above example is rudimentary, of course. But it applies at scale. Upsolver automatically executes this action throughout your entire data transformation process. No manual intervention is required. Upsolver’s built-in best practices ensure that any operation you perform is idempotent. So regardless of whether, for example, you combine data from multiple sources into one target; or you write too much data to a single file and must spill some of it over into multiple files, Upsolver runs the same operation on the same data; you cannot get a non-exactly once output.
3. Query execution
Unlike databases that automatically create an execution plan, data lakes force you to orchestrate your own execution plans, including intermediate data structures.
Coding the transformation is significantly easier in a database than in a data lake. For all intents and purposes, ELT is intrinsic to databases. The data is already loaded; you’re simply querying it to transform it – basically hopping from table to table within the database.
That’s extremely convenient because:
- You’re essentially writing a few SQL statements – much more concise and understandable than code you must debug and maintain.
- You don’t need to be a big data engineer to manage it.
- You don’t need to maintain a code base.
For complicated queries that, for example, encompass a groupby and a join on data pulled from multiple sources, databases do a lot of work behind the scenes – in their equivalent of an optimization layer – to ensure these queries run effectively. They index data and cache some query results. Data lakes don’t have this capability. There’s no good way to run a declarative language on top of large amounts of data.
The manual approach to query execution
Some SQL dialects, such as SparkSQL, support transformations in the data lake. But these dialects are not designed to work with streaming data. The Spark framework requires that you write extensive code and understand complex distributed system concepts to process data with optimal performance. It is designed for batch processing with higher latency. It also offers very limited connectors, so you also must develop your own connectors.
Also, Apache Spark evolved from an on-premises-only architecture. Scaling with a cloud provider calls for a complex management and orchestration layer, which makes it difficult to manage and optimize the environment – especially considering the complexity of checkpointing, partitioning, shuffling, and spilling to local disks.
In fact, arguably the only way you could manually orchestrate joins or aggregations on streaming data in a data lake would be to:
- Maintain stateful transactions in an external key-value store such as RocksDB
- Perform a lookup into that state from the distributed system that’s executing the query
But that course of action has its own issues:
- It lacks consistency guarantees because you’re going to an external database.
- It’s difficult to maintain because you now have to manage an external key-value store.
- There’s no time travel capability (that is, replayability); you’re limited to looking up the latest state.
- Operating an external database becomes exorbitantly expensive at scale.
The Upsolver approach – SQL transformation logic and automated execution planning over streams
Upsolver provides a declarative language (SQL) for specifying query logic, but also automatically generates the execution plan. In one fell swoop Upsolver gives you the ability to perform transformations on top of a stream and execute complex queries, while also optimizing incoming data for faster performance.
Databases use indices to address intermediate structures for joins, aggregations, and so on. Upsolver uses indices on object storage plus a few intermediate structures to give you database functionality on a data lake. In short, Upsolver enables the full gamut of transformations on top of a stream.
For instance, when you define a join between two streams, Upsolver automatically creates an intermediate index and stores that index in S3. It speeds data access via keys relevant to the join. These intermediate indices accelerate complex ETL processes by two orders of magnitude – in other words, seconds or minutes instead of hours or days. And because it’s automated there’s no need for countless hours of manual engineering work.
4. Enabling Upserts (for example, CDC)
Increasingly, companies wish to employ data lakes for use cases where updating data is key, such as:
- deleting data to comply with regulations such as GDPR
- correcting old data that was initially written incorrectly
- pre-computing aggregations and keeping only the aggregated results in the data lake
- Taking an actual database source and replicating it in the data lake to run analytics queries against, without overloading the source database
These situations, and others like them, require deleting or replacing records from the existing data lake. But as the underlying data lake file system is append-only, there’s no easy way to accomplish this; data lakes rely on time-series partitioning for storage, which precludes random access by key. So you can write new files to S3, but you can’t modify them.
The manual approach to data lake upserts
There are upsert solutions on the market – Apache Hudi, Databricks Delta Lake, and Apache Iceberg (which lacks some of the functionality now, but is expected to include it). The key limitation they all have in common is that they restrict you to one committer at a time (similar to what happens during compaction), meaning the files are locked during the upsert to avoid creating an inconsistent state.
Performing processes serially also leads to unacceptably long latency, since all processing must halt while compaction takes place. It precludes real-time or even near-real-time analytics since you’re never working with the most recently updated data. It could be hours old, or even a day old.
The Upsolver approach – automatic non-locking upserts
In short: upserts over vanilla Parquet files.
As mentioned above, Upsolver automatically and continuously compacts files in the background; it never has to interrupt the data workflow. And, as part of the compaction process, it also adds a new table partition which is a write-ahead log containing Parquet files. This is used to handle upserts. Upsolver adds additional columns to the Parquet files: metadata that helps identify records that must be deleted, updated, or inserted. Plus, each record has a unique key that further helps ensure consistency. Upsolver cleans up data from the write-ahead log after the committed partitions have all accepted these new records.
The Parquet files work with any third-party query engine or metadata tooling (Athena, Presto, Dremio, AWS Glue, Hive Metastore, and so on), and the compaction maintains fast query performance without locking records.
Summary
The complexity of achieving database functionality in a data lake, so you can perform real-time analysis on continuous or streaming data, requires a sizable amount of data preparation and orchestration. As a result, companies that try to perform this manually need highly-skilled big data engineers spending almost all of their time on plumbing – building and maintaining the data pipelines that get the data they want to the destination they want, in the form they need, with acceptable performance and efficient processing.
It’s necessary work, but mundane and repetitive, and ultimately it’s hygienic in nature and not the best use of a valuable data engineer’s time. By addressing the four primary data lake challenges, the Upsolver platform automates this plumbing, greatly shortening the time it takes to deliver data pipelines and free up data engineers for more creative, impactful, and fulfilling work.
More Information About the Upsolver Platform
There’s much more information about the Upsolver platform, including how it automates a full range of data best practices, real-world stories of successful implementations, and more, at www.upsolver.com.
Download this road map to self-service data lakes in the cloud.
Review these 7 best practices for high-performance data lakes.
To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes
