
Explore our expert-made templates & start with the right one for you.
Demystifying the Data Mesh: a Quick “What is” and “How to”
-
 Jerry Franklin
Jerry Franklin
- Cloud Architecture
- March 16, 2022
The Rise of the Data Mesh
In a little over two years the concept of “data mesh” has gone from a new construct to the data architecture du jour. While it’s not a panacea, it can offer significant value. This article discusses:
- Why it came to be
- What a data mesh is
- Why there’s so much interest in it
- Key concepts, presented as four discrete operational pillars
- Where it can be of most value and where it’s less applicable
- Where and how Upsolver fits into a data mesh approach
The Challenges of Centralization: Data Warehouses and Data Lakes
For decades the dominant paradigm for analytics has been the data warehouse, where all transactional and operational data (Oracle, SAP, IBM relational databases) was centralized and standardized, then served back to the domain owner (a business unit or department), often in an adjunct data mart for price/performance reasons. Data was centralized in a data warehouse so you could separate it from its source system and then query it on a platform optimized for analytics, without impacting the source system’s operational performance.
As data increased by orders of magnitude in volume, velocity, and variety, it could no longer be kept in a data warehouse due to cost or capability constraints. That led to the invention of the Hadoop-based data lake as the big data sibling to the data warehouse. The data lake was optimized for economically storing and processing raw data from non-transactional sources such as clickstreams, system and application logs, and IoT sensors.
More recently the trend has been to migrate data warehouses and data lakes to the cloud as managed services. Yet the big data/small data dichotomy remains.
A data architecture based on centralized data stores has created organizational distance – in both knowledge about the data and goals for its use – between the domain that generates the data and the central IT group that makes the data analytics-ready via pipelines and processing. The domain owners are disconnected from the full value of their data. They must compete with other domains for access to limited central data engineering resources, while the data engineers responsible for data pipeline development and operational management may not have the best understanding of the semantics of the data. Delayed pipeline development ensues, as the central team struggles to serve the full range of business use cases with different requirements. And data reliability is threatened, as a central group lacking in domain expertise is less likely to detect errors in data or pipeline logic.
These challenges create the need for a new way of thinking: the data mesh.
The Data Mesh Paradigm Explained
In her influential 2019 blog post, Zhermak Dehghani, Director of Emerging Technologies at Thoughtworks, described a new distributed architecture for building data platforms, which she named the “data mesh.” This model doesn’t rely on any new technologies per se; rather, it’s a novel topological approach that literally puts data at the center of business activities. A data mesh replaces the concept of a centrally managed data lake or warehouse with independent lakes or warehouses managed by individual business units overseen by data domain owners. Each domain is responsible for ingesting, transforming, and serving its own data; there’s no single or central group tasked with creating data pipelines on demand. Ownership, responsibility, and accountability for the data devolve to the domain.
According to Dehghani, the data mesh “socio-technical paradigm” addresses key issues of data use that a monolithic architecture leaves unresolved.
The “socio” part of the paradigm: how data mesh aligns domain-focused and infrastructure teams
- It replaces the bottleneck of the centralized monolithic lake or warehouse with smaller and more nimble data domains to reflect the rapid proliferation of different data sources and systems.
- It provides greater flexibility in the face of continual changes in data models and data schema by shifting response to the people who best know the data – the experts in the individual domains.
- It compels a “data as a product” mindset, where domains standardize the data sets they expose to the rest of the organization, requiring them to address data quality the same way one thinks about product quality.
- It’s designed to work with a highly-complex and dynamic organizational environment and not against it by distributing out data pipeline work to the area where business priorities are managed.
- Domains can retain unique business terms and language in their data and still interoperate freely. For example, they can share U.S. sales data regardless of whether the domain dataset stipulates the country as “U.S.,” “U.S.A.,” “USA,” or “United States.”
The “technical” part of the paradigm: how the data mesh impacts data engineering workflows
- It improves data integrity and trustworthiness by merging the analytical and operational computing planes and moving analytical data closer to its source.
- It reduces unintentional complexity of pipelines and copying of data. Reduced data pipeline complexity supports greater autonomy for LOB owners to scale, innovate, and make smaller changes faster. Reduced copying lowers storage costs and the impact of changes from data drift that jeopardize data quality.
- It emphasizes data serving rather than data ingestion.
- It accounts for the need for a standardized data observability, governance, and discoverability layer to understand the health of data assets across their life cycle.
The 4 Core Principles of Data Mesh
Dhaghani defined four discrete tenets:
- Domain-oriented decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
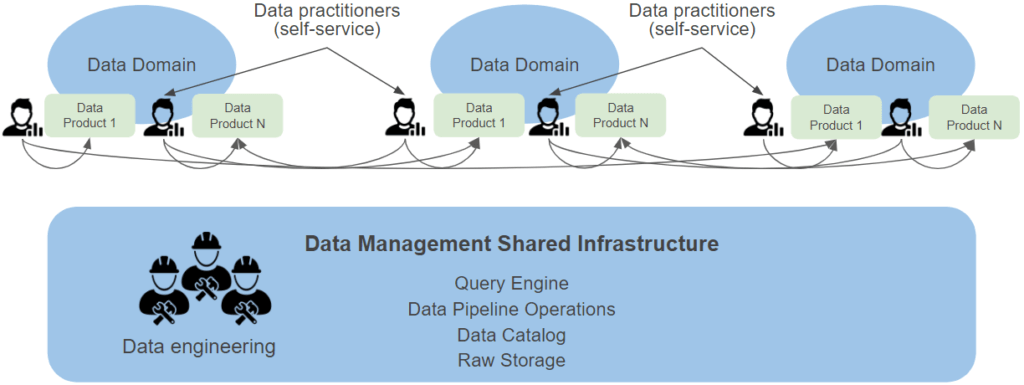
Domain-oriented decentralized data ownership and architecture
A data mesh decouples the management and responsibility of a data platform, placing them instead in the hands of each data domain. It distributes ownership and accountability for data to the people who best understand it, have domain knowledge, and can ensure it is reliable and accurate.
In a data mesh, data practitioners have self-service access to their domain data. They build their own pipelines, they perform any necessary transformations (aggregations, joins, formatting, and so on) ideally with little or no coding (reducing skill requirements), and they productize their analytical data for easy consumption.
Data as a product
In a data mesh, data isn’t a by-product of an operational activity – it is a product itself. But it goes well beyond simply a suite of quality datasets. In a data mesh, each domain is the manufacturer and seller, and must embrace software product thinking, including design-driven principles and best practices in the software development lifecycle (SDLC). From a strict organizational view, the change is also significant. You’re dividing the data platform team, creating the role of domain data product owner, and incentivizing domains to own and be accountable for the datasets they produce and share.
Data as a product has the characteristics of a discrete application developed to address a specific business need. That means:
- It’s easy for the consumer to discover (it’s cataloged), understand (the metadata of the data structure profile is exposed), and use (it’s optimized for adequate query performance and ideally is accessible via a well-documented API).
- It conforms to cross-domain rules and standards in relation to topics such as ontology / semantics, field structures, versioning, monitoring, security, and governance.
Data infrastructure as a central, shared service platform
A data mesh calls for decentralization of raw data, pipelines, and prepared data sets. Yet it also recognizes the efficiencies of centralizing the underlying data management infrastructure. There’s no reason to believe the business domains are well-versed in infrastructure management, and there are economies of scale and scope to centralizing selection, procurement, and management of these platforms.
A central data infrastructure team owns and provides the technology necessary for creating and maintaining this infrastructure to all domains. Each domain can self-provision this data-infrastructure-as-a-service to capture, process, store, serve, and enhance its data products.
In a data mesh, this infrastructure is easy to use and substantially automated, though that of course is easier said than done. Further, this infrastructure must endow generalist developers with the same capabilities as specialists (such as Spark and Python engineers) for developing analytical data products. And it should be both domain- and vendor agnostic.
Federated computational governance
In addition to data infrastructure, governance is also most effective when it’s centralized. Each domain relies on agreed-upon business-wide standards covering a range of data characteristics – privacy, access controls, quality, discoverability, and compliance with internal rules or government regulations. Within these common constraints, domains can interoperate yet remain independent in terms of both their decision-making and their product focus.
7 Signs You Are a Good Candidate for a Data Mesh
It may seem obvious, but before you start evaluating a data mesh, be clear on the problem(s) you’re trying to solve. Are you trying to accelerate innovation? Reduce costs and improve quality by minimizing copying of raw data? Remove a data engineering or DevOps bottleneck? Enforce data quality standards?
Here are some general indicators that a data mesh is worth considering:
- You have a central IT team that onboards new data sets for the entire organization, causing long lead times and needless iterations.
- You have a variety of business units or independent teams with heterogeneous analytics needs.
- Analytics agility is critical to the success of your team.
- Most of the consumption of the domain’s data sets comes from users within the domain. Yet the backlog of their requests for data pipelines keeps growing due to central data engineering capacity constraints.
- The data has nuanced semantics and complex preparation needs and thus requires domain specialists more than engineering specialists.
- Your standard data engineering tools match your domain users’ skill sets. Tools such as Upsolver require only SQL knowledge; others require Python, Java, Spark, and Airflow expertise.
- Your business philosophy defaults to decentralizing control to business units/domains, with a relatively thin layer of shared services provided by corporate.
5 Signs You Are Not a Good Candidate for a Data Mesh
Shifting to a data mesh paradigm is not trivial. Here’s when you’re less likely to see ROI:
- You’re a small or medium-sized business so there is little or no distinction between domains and central IT.
- Your analytics users are centralized and their needs across domains are homogenous (for example, only BI/reporting but not ad hoc analytics, data science, or machine learning).
- Central governance and control over data is paramount – that is, without additional specialized tools, the cost of a lapse in governance or compliance dwarfs the benefits of decentralization.
- There’s just no better alternative to moving some data into a central data store.
- You lack a robust culture of change management. A data mesh requires restructuring; you must overcome both any staff resistance to taking on additional responsibilities and any business domain ownership resistance to creating data as a product as a core responsibility. Without broad buy-in to ensure domain cooperation, data product interoperability, and adherence to technical standards, you may decentralize but not reap the benefits of a data mesh.
Upsolver Simplifies Data Pipeline Engineering and Enables Your Data Mesh
If you decide to devolve pipelines to the business domains in a data mesh pattern, how do you avoid having to deploy heavy-duty data engineering skills into all of these groups? Finding these experienced engineers is difficult and expensive; a LinkedIn search for data engineers shows there are twice as many job openings as there are currently staffed positions. That’s substantially worse than the more publicized hiring situation for data scientists.
You can get around this “skills squeeze” by standardizing on pipeline engineering and operations infrastructure that is highly automated and uses a widely familiar declarative language, such as SQL, to specify your pipeline logic.
Upsolver’s SQL data pipeline platform acts as standard infrastructure for developing, executing, and managing pipelines on cloud data lakes. It requires only SQL knowledge and is supported by full automation of pipeline engineering. Upsolver’s visual IDE enables domain-based data practitioners to define the attributes of their data product in SQL (including extensions to handle operations on streaming data, such as sliding windows and stateful joins). Then they can output data to suit their product specs, such as a Parquet table on the domain-specific data lake or a table in an external database or data warehouse. Users don’t need to know programming languages such as Python, Java, or Scala, and they don’t need to use orchestration tools such as Airflow or dbt. This means they can deliver “data-as-a-product” quickly and reliably.
Because Upsolver can ingest and process streaming data at millions of events per second, the data products you can create can be live tables that update automatically and incrementally as new events flow in, regardless of scale.
Upsolver automates the “ugly plumbing” of table management and optimization and delivers standard Parquet files that are queryable from engines like Amazon Athena, Amazon Redshift Spectrum, Starburst, Presto, and Dremio. It also handles management of an underlying data catalog such as AWS Glue Data Catalog or the Apache Hive Metastore. Because it’s a cloud-native service it can scale automatically with requirements. And it’s easy to create SQL pipeline-as-code templates that enforce corporate governance standards around formatting, semantic alignment, and PII handling.
In short, with Upsolver as shared infrastructure, SQL practitioners in your business domains can build highly powerful pipelines quickly, for their own group’s use and to expose their data products to other domains.
Read about how you can build, scale, and future-proof your data pipeline architecture.
To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Published in:
Blog
,
Cloud Architecture