
Explore our expert-made templates & start with the right one for you.
Table of contents
Frequently Asked Questions
What is a Data Pipeline?
A data pipeline is an automated or semi-automated process for moving data between disparate systems. Data pipelines can execute simple jobs, such as extracting and replicating data periodically, or they can accomplish more complex tasks such as transforming, filtering and joining data from multiple sources.
Example Use Cases for Data Pipelines
Data pipelines are used to support business or engineering processes that require data. This could mean ‘manual’ data exploration, a dashboard that updates with fresh data, or triggering a process within a software application.
Typical business scenarios that are supported by data pipelines include:
- Business intelligence: In order to give businesses stakeholders access to information about key metrics, BI dashboards require fresh and accurate data. A data pipeline can pull data from multiple sources or APIs, store in an analytical database such as Google BigQuery or Amazon Redshift, and make it available for querying and visualization in tools such as Looker or Google Data Studio.
- Centralizing data from different sources: Siloed data marts are problematic when you want to make sure different departments (such as Sales and Marketing) are looking at the same data. In order to create a single source of truth, the data pipeline needs to centralize and normalize the data in a single unified repository such as a data warehouse or a data lake.
- Data-driven applications: Many modern software applications are built on driving automated insights from data and responding in real-time. This could include algorithmic trading apps, identifying suspicious e-commerce transactions, or programmatically choosing which ad to display to ensure high click-through rates. These apps require fresh, queryable data delivered in real-time – which is where continuous data pipelines come in.
- Improving data warehouse costs and performance: Data warehouses are crucial for many analytics processes, but using them to store terabytes of semi-structured data can be time and money-consuming. Data pipelines can be used to reduce the amount of data being stored in a data warehouse by deduplicating or filtering records, while storing the raw data in a scalable file repository such as Amazon S3. You can read more about this use case in our data warehouse benchmark report.
- Data science and machine learning: Effective model training and deployment requires consistent access to structured data. Machine learning pipelines typically extract semi-structured data from log files (such as user behavior on a mobile app) and store it in a structured, columnar format that data scientists can then feed into their SQL, Python and R code.
How to Build a Data Pipeline
Every data pipeline you need to build is essentially a build vs buy decision. Data engineers can either write code to access data sources through an API, perform the transformations, and then write the data to target systems – or they can purchase an off-the-shelf data pipeline tool to automate that process.
As with any decision in software development, there is rarely one correct way to do things that applies to all circumstances. For very simple projects, purchasing an additional system might be overkill; for ultra-complex and custom ones, you might not be able to find a complete packaged solution and will need to use a mix of hand-coding, proprietary and open-source software.
However, the broadly-accepted best practice is to focus engineering efforts on features that can help grow the business or improve the product, rather than maintaining tech infrastructure. In cases where you find a data pipeline tool that can solve your problem at a lower or similar resource cost, you should consider making this investment in order to free up engineering talent to focus on innovation.
Data Warehouse vs Data Lake Pipelines
The rise of cloud data lakes requires a shift in the way you design your data pipeline architecture. ELT (extract-load-transform) has become a popular choice for data warehouse pipelines, as they allow engineers to rely on the powerful data processing capabilities of modern cloud databases.
However, a data lake lacks built-in compute resources, which means data pipelines will often be built around ETL (extract-transform-load), so that data is transformed outside of the target system and before being loaded into it. Read more about data lake ETL.
While Apache Spark and managed Spark platforms are often used for large-scale data lake processing, they are often rigid and difficult to work with. Organizations that prefer to move fast rather than spend extensive resources on hand-coding and configuring pipelines in Scala can use Upsolver as a self-service alternative to Spark.
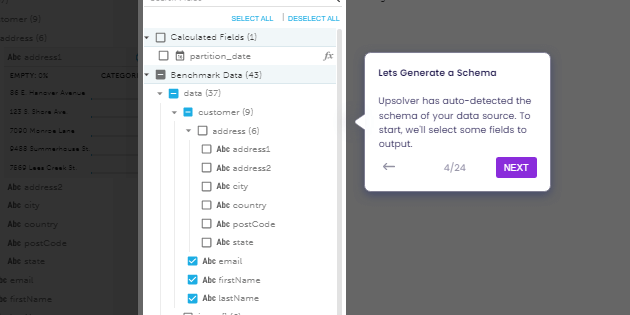
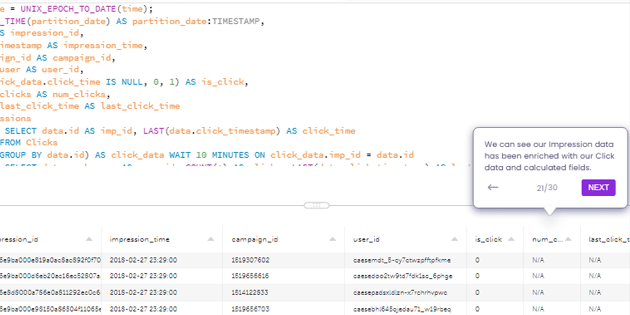
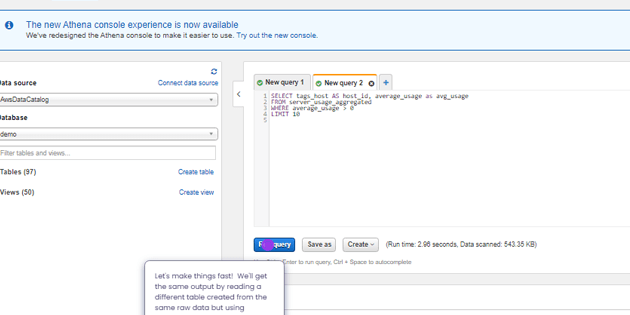
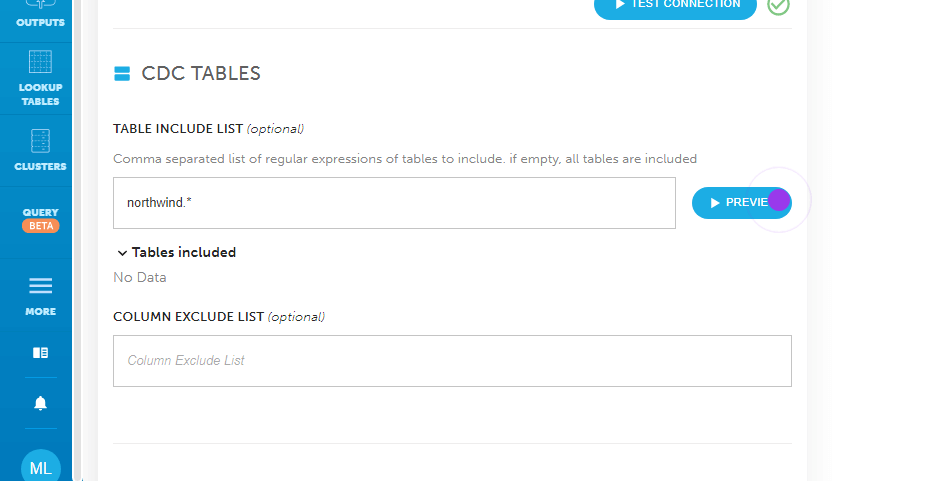
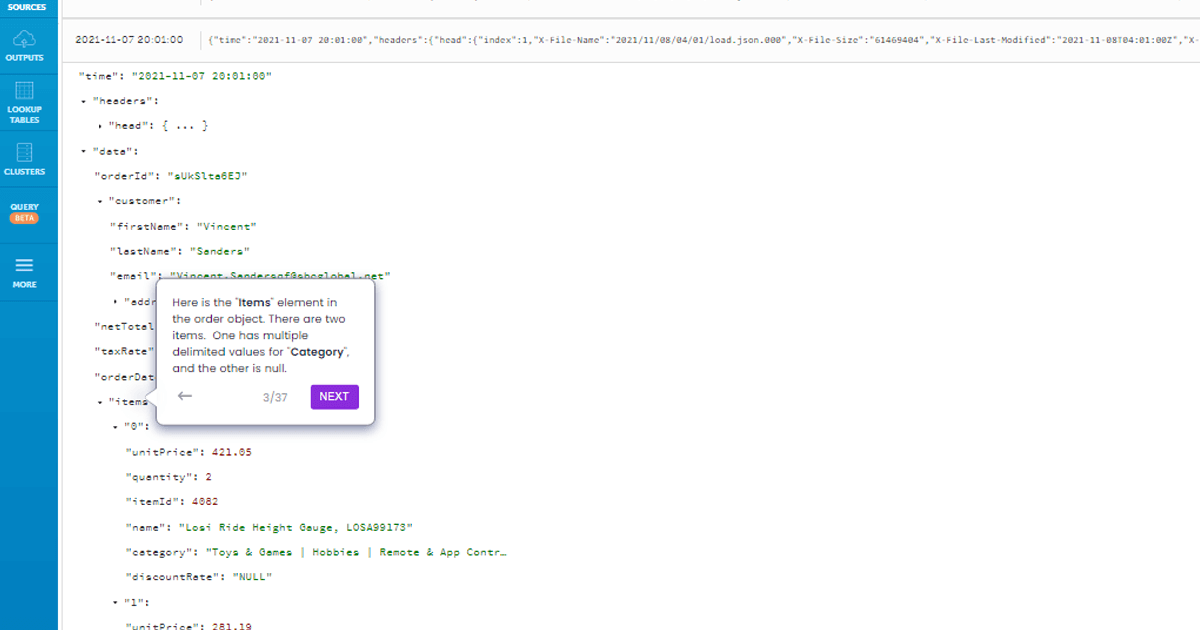
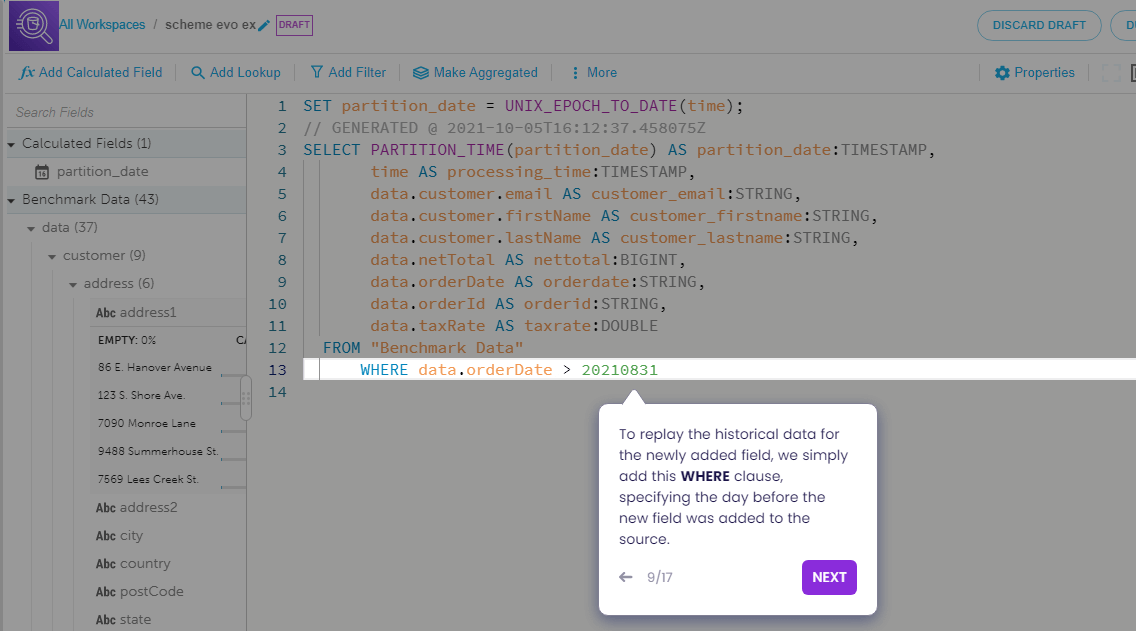
How to Use the Data Pipeline Examples on this Page
At the top of this page you’ll find different examples of data pipelines built with Upsolver. You can run through the interactive example to learn more about types of data pipelines and common challenges you can encounter when designing or managing your data pipeline architecture. You can also start working with your own data in our Try SQLake for Free.