
{kind=link}
Explore our expert-made templates & start with the right one for you.
Parquet, ORC, and Avro: The File Format Fundamentals of Big Data
-
 Jerry Franklin
Jerry Franklin
- Streaming Data
- October 26, 2022
The following is an excerpt from our complete guide to big data file formats. Get the full resource for additional insights into the distinctions between ORC and Parquet file formats, including their optimal use cases, and a deeper dive into best practices for cloud data storage. Read it for free here
The Evolution of File Formats
With an estimated 2.5 quintillion bytes of data created daily in 2022 – a figure that’s expected to keep growing – it’s paramount that methods evolve to store this data in an efficient manner.
While JSON and CSV files are still common for storing data, they were never designed for the massive scale of big data and tend to eat up resources unnecessarily (JSON files with nested data can be very CPU-intensive, for example). They are in text format and therefore human readable. But they lack the efficiencies offered by binary options.
So as data has grown, file formats have evolved. File format impacts speed and performance, and can be a key factor in determining whether you must wait an hour for an answer – or milliseconds. Matching your file format to your needs is crucial for minimizing the time it takes to find the relevant data and also to glean meaningful insights from it.
This article compares the most common big data file formats currently available – Avro versus ORC versus Parquet – and walks through the benefits of each.
Explaining the Row vs. Columnar Big Data File Formats
There are two main ways in which you can organize your data: rows and columns. Which one you choose largely controls how efficiently you store and query your data.
- Row – the data is organized by record. Think of this as a more “traditional” way of organizing and managing data. All data associated with a specific record is stored adjacently. In other words, the data of each row is arranged such that the last column of a row is stored next to the first column entry of the succeeding data row.
- Columnar – the values of each table column (field) are stored next to each other. This means like items are grouped and stored next to one another. Within fields the read-in order is maintained; this preserves the ability to link data to records.
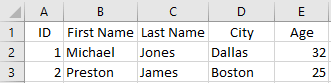
Row format: Traditionally you can think of row storage this way:
1, Michael, Jones, Dallas, 32
2, Preston, James, Boston, 25
But you can also represent row data visually in the order in which it would be stored in memory, like this:
1, Michael, Jones, Dallas, 32, 2, Preston, James, Boston, 25
Columnar format: Traditionally you can think of columnar storage this way:
ID: 1, 2
First Name: Michael, Preston
Last Name: Jones, James
City: Dallas, Boston
Age: 32, 25
But you can also represent columnar data visually in the order in which it would be stored in memory
1, 2, Michael, Preston, Jones, James, Dallas, Boston, 32, 25
Choosing a format is all about ensuring your format matches your downstream intended use for the data. Below we highlight the key reasons why you might use row vs. columnar formatting. Optimize your formatting to match your storage method and data usage, and you’ve optimized valuable engineering time and resources.
The Particulars of Row Formatting
WIth data in row storage memory, items align in the following way when stored on disk:

Adding more to this dataset is trivial – you just append any newly acquired data to the end of the current dataset:

As writing to the dataset is relatively cheap and easy in this format, row formatting is recommended for any case in which you have write-heavy operations. However, read operations can be very inefficient.
Here’s an example: Obtain the sum of ages for individuals in the data. This simple task can be surprisingly compute-intensive with a row-oriented database. Since ages are not stored in a common location within memory, you must load all 15 data points into memory, then extract the relevant data to perform the required operation:
Load:

Extract:
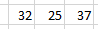
Sum:
32 + 25 + 37 = 94
Now imagine millions or billions of data points, stored across numerous disks because of their scale.
Using the same example:
Suppose the data lives in several discs, and each disk can hold only the 5 data points. The sample dataset is split across 3 storage discs:
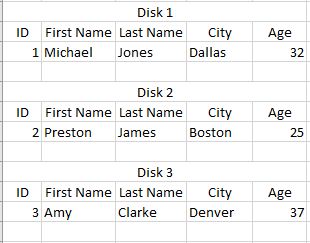
You must load all the data in all the discs to obtain the information necessary for your query. If each disk is filled to capacity with data, this can easily require extra memory utilization and quickly become burdensome.
That said, row formatting does offer advantages when schema changes – we’ll cover this later. In general, if the data is wide – that is, it has many columns – and is write-heavy, a row-based format may be best.
The Particulars of Columnar Formatting
Again, referring to the example dataset in columnar format, we can visually represent the data in the order in which it would be stored in memory as follows:

The data is grouped in terms of like columns:
- ID
- First Name
- Last Name
- City
- Age
Writing data is somewhat more time-intensive in columnar formatted data than it is in row formatted data; instead of just appending to the end as in a row-based format, you must read in the entire dataset, navigate to the appropriate positions, and make the proper insertions:

Navigating to the appropriate positions for insertions is wasteful. But the way the data is partitioned across multiple disks can alleviate this. Using the same framework as with row formatted data, suppose you had a separate storage location (disk) for each attribute (column) (so in this sample data case there are 5 disks):
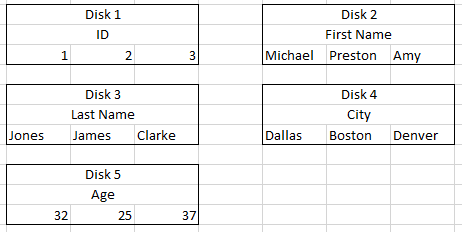
It still takes a large amount of memory and computational time writing to 5 separate locations to add data for a 3rd individual. However, you are simply appending to the end of the files stored in each of the locations.
So the columnar format doesn’t compare favorably to row formatting with regard to write operations. But it is superior for read operations such as querying data. Here’s the same read example from before, applied to column-based storage partitioned by column:
Task: Obtain the sum of ages for individuals in the data.
To accomplish this, go only to the storage location that contains information on ages (disk 5) and read the necessary data. This saves a large amount of memory and time by skipping over non-relevant data very quickly.
Read:
Sum:
32 + 25 + 37 = 94
In this case, all reads came from sequential data stored on a single disk.
But efficient querying isn’t the only reason columnar-formatted data is popular. Columnar-formatted data also allows for efficient compression. By storing each attribute together (ID, ages, and so on) you can benefit from commonalities between attributes, such as a shared or common data type or a common length (number of bits) per entry. For example, if you know that age is an integer data type that won’t exceed a value of 200, you can compress the storage location and reduce memory usage/allocation, as you don’t need standard amounts of allocated memory for such values. (BIGINT is typically stored as 4 bytes, for instance, whereas a short int can be stored as 2 bytes).
Further, columnar-formatted files usually support a number of flexible compression options (Snappy, gzip, and LZO, for example) and provide efficient encoding schemes. For example, you can use different encoding for compressing integer and string data; as all the data is very similar in a column, it can be compressed more quickly for storage and decompressed for analysis or other processing. In a row-based storage structure, on the other hand, you must compress many types of data together – and those rows can get very long in schema on read – and decompress pretty much the entire table when it’s time for analysis or other processing.
Now let’s take a deeper look into three popular file formats for big data: Avro, ORC, and Parquet.
The Avro Row-Based File Format Explained
Apache Avro was a project initially released late in 2009 as a row-based, language-neutral, schema-based serialization technique and object container file format. It is an open-source format that is often recommended for Apache Kafka. It’s preferred when serializing data in Hadoop. The Avro format stores data definitions (the schema) in JSON and is easily read and interpreted. The data within the file is stored in binary format, making it compact and space-efficient.
What makes Avro stand out as a file format is that it is self-describing. Avro bundles serialized data with the data’s schema in the same file – the message header contains the schema used to serialize the message. This enables software to efficiently deserialize messages.
The Avro file format supports schema evolution. It supports dynamic data schemas that can change over time; it can easily handle schema changes such as missing fields, added fields, or edited/changed fields. In addition to schema flexibility, the Avro format supports complex data structures such as arrays, enums, maps, and unions.
Avro-formatted files are splittable and compressible (though they do not compress as well as some columnar data). Avro files work great for storage in a Hadoop ecosystem and for running processes in parallel (because they are faster to load.
One caveat: If every message includes the schema in its header, it doesn’t scale well. Avro requires the reading and re-reading of the repeated header schema across multiple files, so at scale Avro can cause inefficiencies in bandwidth and storage space, slowing compute processes.
| Avro Format Features |
|---|
| Can be shared by programs using different languages |
| Self-describing; bundles serialized data with data’s schema |
| Supports schema evolution and flexibility |
| Splittable |
| Compression options including uncompressed, snappy, deflate, bzip2, and xz |
Ideal Avro format use cases
- Write-heavy operations (such as ingestion into a data lake) due to serialized row-based storage.
- When writing speed with schema evolution (adaptability to change in metadata) is critical.
The Optimized Row Columnar (ORC) Columnar File Format Explained
Optimized Row Columnar (ORC) is an open-source columnar storage file format originally released in early 2013 for Hadoop workloads. ORC provides a highly-efficient way to store Apache Hive data, though it can store other data as well. It’s the successor to the traditional Record Columnar File (RCFile) format. ORC was designed and optimized specifically with Hive data in mind, improving the overall performance when Hive reads, writes, and processes data. As a result, ORC supports ACID transactions when working with Hive.
The ORC file format stores collections of rows in a single file, in a columnar format within the file. This enables parallel processing of row collections across a cluster. Due to the columnar layout, each file is optimal for compression, enabling skipping of data and columns to reduce read and decompression loads.
ORC files are organized into independent stripes of data. Each stripe consists of an index, row data, and a footer. The footer holds key statistics for each column within a stripe (count, min, max, sum, and so on), enabling easy skipping as needed. The footer also contains metadata about the ORC file, making it easy to combine information across stripes.
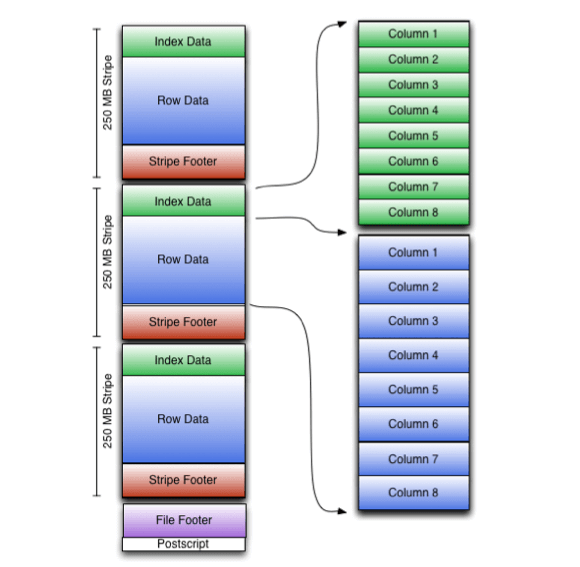
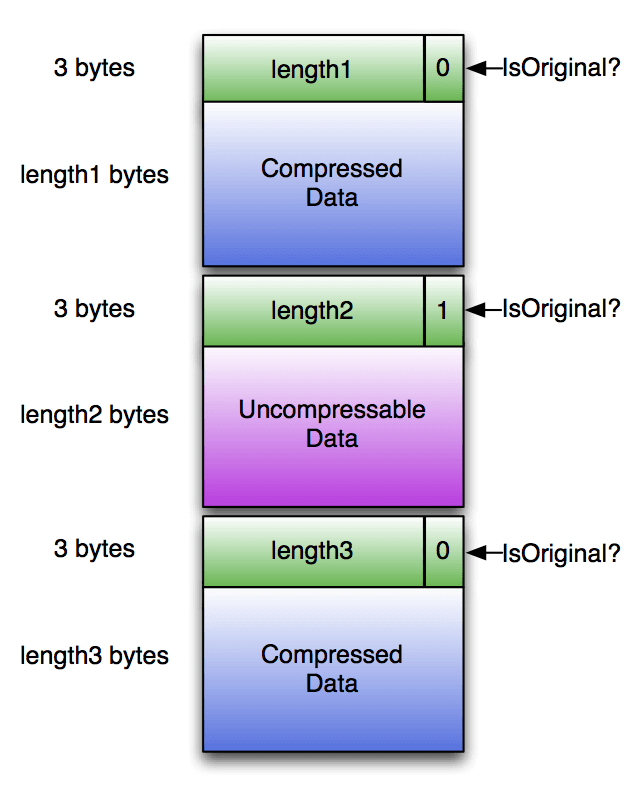
By default, a stripe size is 250 MB; the large stripe size is what enables efficient reads. ORC file formats offer superior compression characteristics (ORC is often chosen over Parquet when compression is the sole criterion), including compression done with Snappy or Zlib. An additional feature unique to ORC is predicate pushdown. In predicate pushdown, the system checks a query or condition against file metadata to see whether rows must be read. This increases the potential for skipping.
| ORC Format Features |
|---|
| NameNode load reduction – single file output per task |
| Complex type support including DateTime, decimal, struct, list, map, and union |
| Separate RecordReaders for concurrent reads of a single file |
| Split files without scanning for markers |
| Predicate pushdown |
| Compression options including Snappy, Zlib |
| Supports ACID when used with Hive |
Ideal ORC format use cases
- When reads constitute a significantly higher volume than writes.
- When you rely on Hive.
- When compression flexibility/options are key.
The Parquet Columnar File Format Explained
The Apache Parquet file format was first introduced in 2013 as an open-source storage format that boasted substantial advances in efficiencies for analytical querying. According to https://parquet.apache.org:
“Apache Parquet is a … file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk…”
Parquet files support complex nested data structures in a flat format and offer multiple compression options.
Parquet is broadly accessible. It supports multiple coding languages, including Java, C++, and Python, to reach a broad audience. This makes it usable in nearly any big data setting. As it’s open source, it avoids vendor lock-in.
Parquet is also self-describing. It contains metadata that includes file schema and structure. You can use this to separate different services for writing, storing, and reading Parquet files.
Parquet files are composed of row groups, header and footer. Each row group contains data from the same columns. The same columns are stored together in each row group:
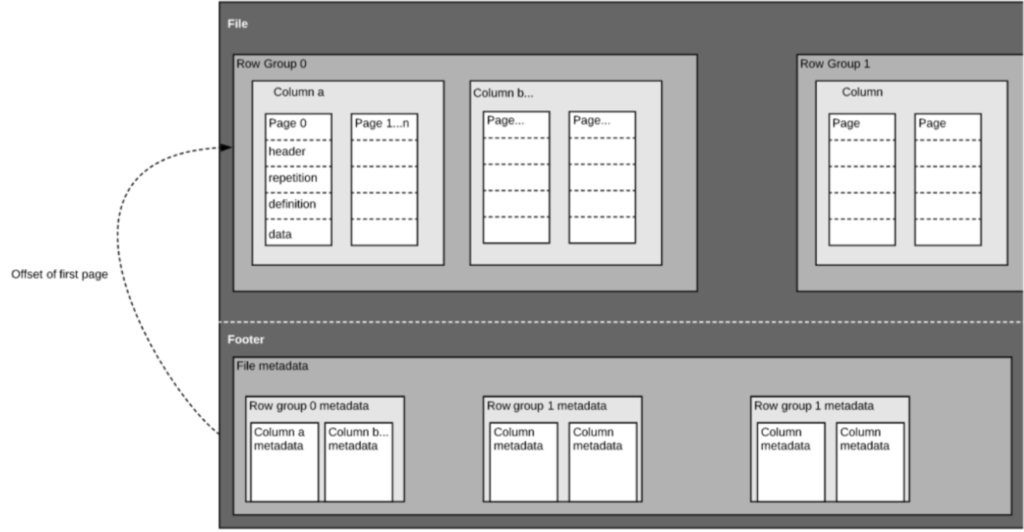
Most importantly, at its core Parquet formatting is designed to support fast data processing for complex nested data structures such as log files and event streams at scale. It saves on cloud storage space by using highly efficient columnar compression, and provides flexible encoding schemes to handle columns with different data types; you can specify compression schemes on a per-column basis. It is extensible to future encoding mechanisms as well, making Parquet “future-proof” in this regard. Parquet supports many query engines including Amazon Athena, Amazon Redshift Spectrum, Qubole, Google BigQuery, Microsoft Azure Data Explorer and Apache Drill). It reports a 2x faster unload speed and consumes as little as ⅙ the storage in Amazon S3 compared to text formats.
Parquet files are splittable as they store file footer metadata containing information on block boundaries for the file. Systems access this block boundary information to determine whether to skip or read only specific parts (blocks) of the file – allowing for more efficient reads – or to more easily submit different blocks for parallel processing. Parquet supports automatic schema merging for schema evolution, so you can start with a simple schema and gradually add more columns as needed.
Parquet files are often most appropriate for analytics (OLAP) use cases, typically when traditional OLTP databases are the source. They offer highly-efficient data compression and decompression. They also feature increased data throughput and performance using techniques such as data skipping (in which queries return specific column values and do not read an entire row of data, greatly minimizing I/O).
| Parquet Format Features |
|---|
| Language agnostic |
| Supports complex data types |
| Multiple flexible compression options |
| Supports schema evolution |
| Enables data skipping, reduced I/O |
Ideal Parquet format use cases
- Storing big data of any kind (structured data tables, images, videos, documents).
- Ideal for services such as AWS Athena and Amazon Redshift Spectrum, which are serverless, interactive technologies.
- A good fit for Snowflake as it supports extremely efficient compression and encoding schemes.
- When your full dataset has many columns, but you only need to access a subset.
- When you want multiple services to consume the same data from object storage.
- When you’re largely or wholly dependent on Spark.
ORC vs Parquet: Key Differences in a Nutshell
ORC (Optimized Row Columnar) and Parquet are two popular big data file formats. Parquet is generally better for write-once, read-many analytics, while ORC is more suitable for read-heavy operations. ORC is optimized for Hive data, while Parquet is considerably more efficient for querying. Both support complex data structures, multiple compression options, schema evolution, and data skipping.
Why Upsolver Uses the Parquet Format
There is overlap between ORC and Parquet. But Parquet is ideal for write-once, read-many analytics, and in fact has become the de facto standard for OLAP on big data. It also works best with Spark, which is widely used throughout the big data ecosystem.
Parquet is really the best option when speed and efficiency of queries are most important. It’s optimized to work with complex data in bulk, including nested data. It’s also highly-effective at minimizing table scans and, like ORC, can compress data to small sizes. It provides the widest range of options for squeezing greater efficiency from your queries regardless of vendor. And its extensibility with regard to future encoding mechanisms also makes it attractive to organizations concerned with keeping their data infrastructure current and optimized.
It’s worth noting that new table formats are also emerging to support the substantial increases in the volume and velocity (that is, streaming) of data. These formats include Apache Iceberg, Apache Hudi, and Databricks Delta Lake. We will explore these in a future blog.
More on benefits and use cases of Parquet.
Introducing Upsolver
With Upsolver, you can build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Easily develop, test, and deploy pipelines that extract, transform, and load data in data lakes and data warehouses in minutes instead of weeks. Upsolver simplifies pipeline operations by automating tasks like job orchestration and scheduling, file system optimization, data retention, and the scaling of compute resources. You no longer need to build and maintain complicated orchestration logic (DAGs), optimize data by hand, or manually scale infrastructure. It’s all automatic.
Try Upsolver for free. No credit card required.
Published in:
Blog
,
Streaming Data