






Explore our expert-made templates & start with the right one for you.
Table of contents
Amazon Athena and Amazon S3
We’re massive fans of Amazon Athena – not just because Upsolver is the only official partner on the Athena webpage on AWS, but also because we see the fascinating, versatile ways in which customers use Athena for business intelligence, ad hoc reporting, and data science.
In this guide, we’ll cover the basics of querying Amazon S3 using Athena, including some handy links to previous resources we’ve published on this topic, and end with a quick example and tutorial on querying Apache Parquet files on S3 as Athena tables.
Amazon Athena and Amazon S3 – the cloud data lake power couple
In a typical AWS data lake architecture, S3 and Athena are two services that go together like a horse and carriage – with S3 acting as a near-infinite storage layer that allows organizations to collect and retain all of the data they generate, and Athena providing the means to query the data and curate structured datasets for analytical processing.
The key advantage of using Athena is that it can read data directly from S3, using regular SQL. This helps bridge the gap between S3 object storage – which is schemaless and semi-structured – and the needs of analytics users who want to run regular SQL queries on the data (although, as we will cover below, data preparation is still required).
Another advantage of Athena is that it is serverless, with compute resources provisioned by AWS on-demand and as required to answer a specific query. This makes life simpler for data engineers as there is no infrastructure to manage, unlike traditional data warehouses such as Amazon Redshift (read more about the differences between Athena and Redshift).
What are Athena tables?
Since Athena is based on regular SQL, it supports DDL statements and has the concept of “tables.” These behave similarly to tables in a relational database. However, unlike a traditional database, Athena uses schema-on-read rather than schema-on-write – meaning a schema is projected on the data when a query is run, rather than when the data is ingested into the database (since Athena doesn’t ingest the data but rather reads it, unmodified, from S3).
Hence, when we talk about “tables” in Athena we are actually talking about a logical namespace that describes the schema and the location where data is stored on S3. Athena uses the Apache Hive metastore to define tables and create databases, but doesn’t store any data, in accordance with its serverless architecture.
You can read more about Athena tables in the AWS documentation, or peruse our previous blog post covering the differences between Amazon Athena and traditional databases.
Optimizing the S3 Storage Layer for Improved Performance in Athena
While Athena is serverless and easy to use due to its reliance on regular SQL, its performance can still be impacted by the way data is stored in the underlying Amazon S3 bucket. While this likely won’t be material if you’re just querying a few thousand files or a few hundred megabytes, at larger scales it is essential to preprocess the data to ensure Athena performs well and also to control costs.
To provide optimal performance, implement data lake best practices including storing data in columnar formats such as Apache Parquet, rather than raw CSV and JSON; merging small files in a process known as compaction; and data partitioning. We’ve covered all of these topics in some depth before, so go ahead and click on the links to explore further. You can also check out everything we’ve ever written about Amazon Athena.
As a no-code data lake engineering platform, Upsolver automates these data preparation tasks, which otherwise would need to be coded manually using tools such as AWS Glue or Apache Spark. However, whether you go self-service or code-intensive, it’s crucial to keep your S3 storage “tidy” to make it easier for Athena and other query engines to scan and retrieve data from your data lake.
Example: Creating an Athena table from Apache Parquet on S3
So how does all of this work in practice? Let’s look at a real-life example of how we would ingest a streaming data source into Amazon S3, store it as optimized Apache Parquet, and then retrieve that data as a table in Amazon Athena. We will be using the Upsolver platform for this example – if you don’t have an account, you can get a free Community Edition account and follow along.
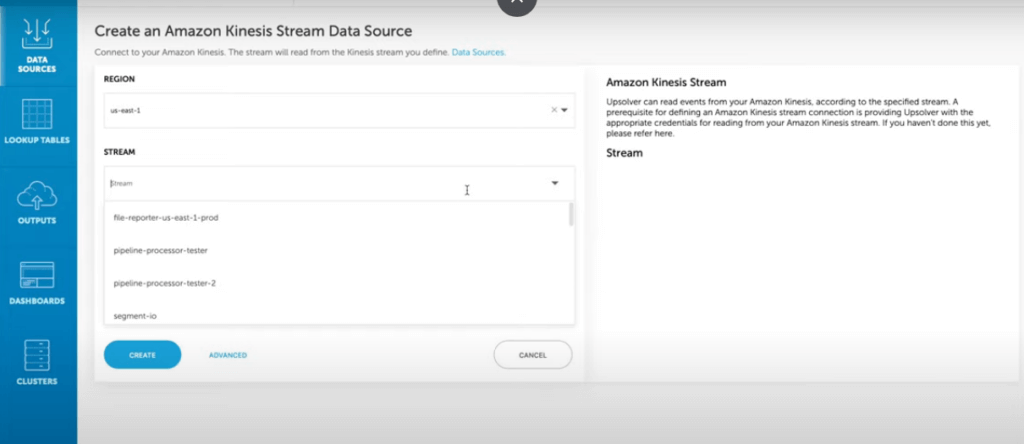
Ingesting data from Kinesis
To ingest data from Kinesis to S3, we’ll create a Kinesis Data Source using the Upsolver UI:
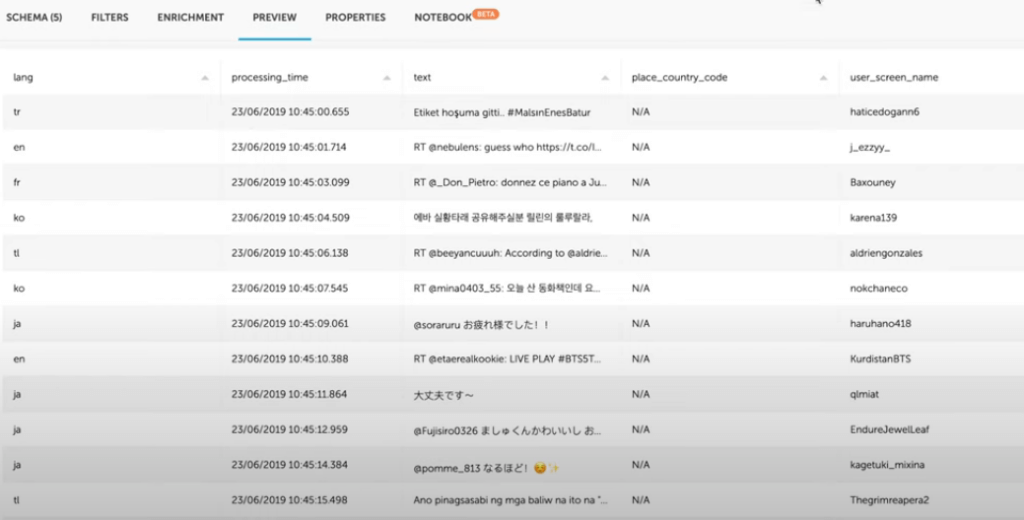
Upsolver enables us to explore this data source and see the original schema in which the JSON data is being ingested. Since we’re working in a data lake architecture, we ingest the data as is and will not alter the schema-on-write. Instead we will project a schema on the data as we are preparing to query it with Athena.
We can see that the Kinesis data we are ingesting has multiple values in the data.lang field.
Having stored this data on S3, we would like to build an Athena table from several fields within this data source, and partition the data by the data.lang field. In Upsolver terms, this will be called an Output. We can now map the data into an Athena table, and since we have the schema and statistics at hand, this is easy to do without making mistakes along the way.
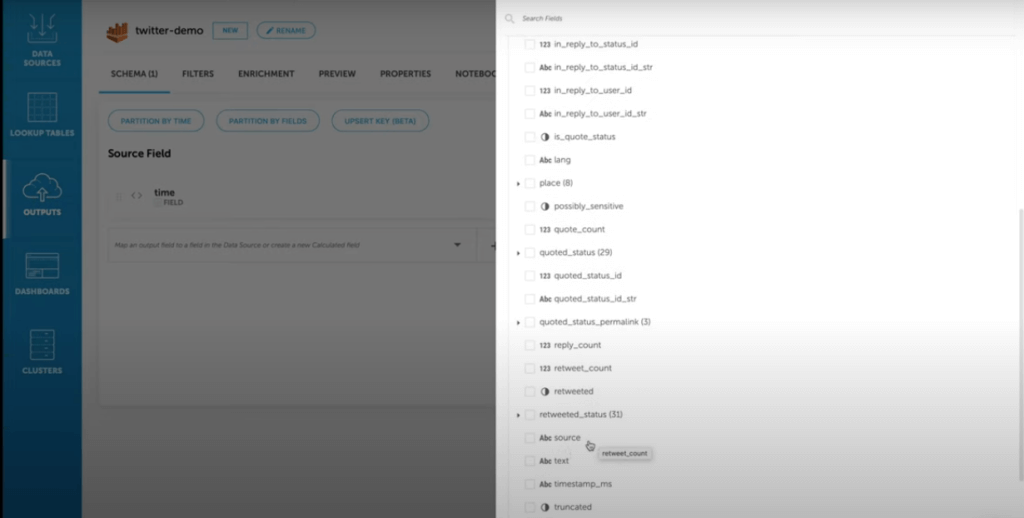
After choosing the relevant fields to include in our Athena table, we can select the field by which we wish to partition the table. If we would like to query the data according to a specific language, we should add the data.lang field as a partition field to ensure good performance when querying the data.
We can then proceed to preview the table, before actually writing any data:
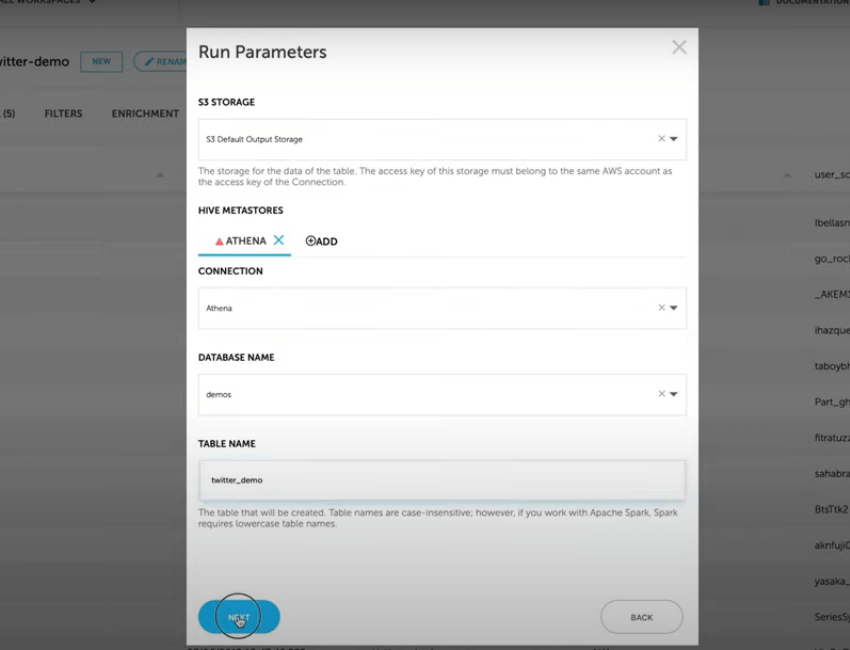
Running the output tells Upsolver to create an Athena table on the Glue Data Catalog, while maintaining the partitions on S3 according to the table metadata. Upsolver also optimizes the data, merges small files, and converts the data to columnar Apache Parquet format. This makes it easier to read and reduces the amount of data Athena needs to scan.
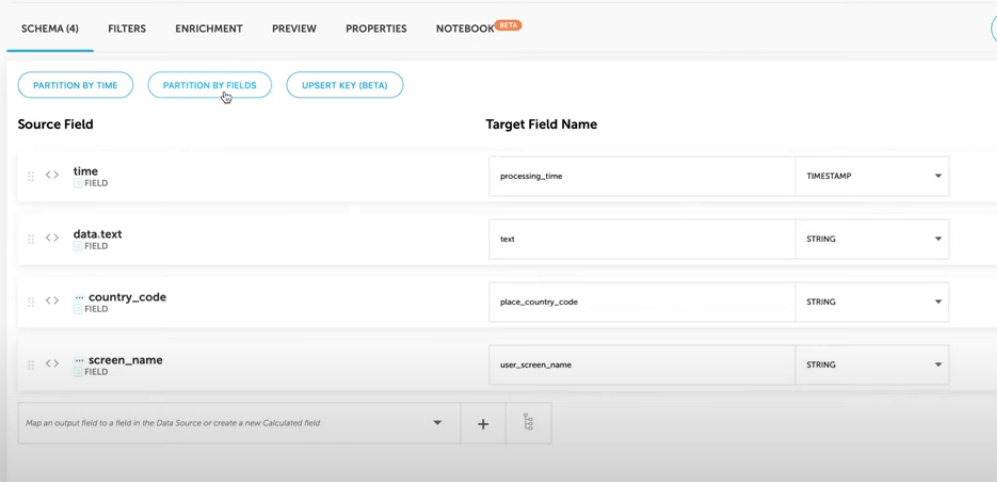
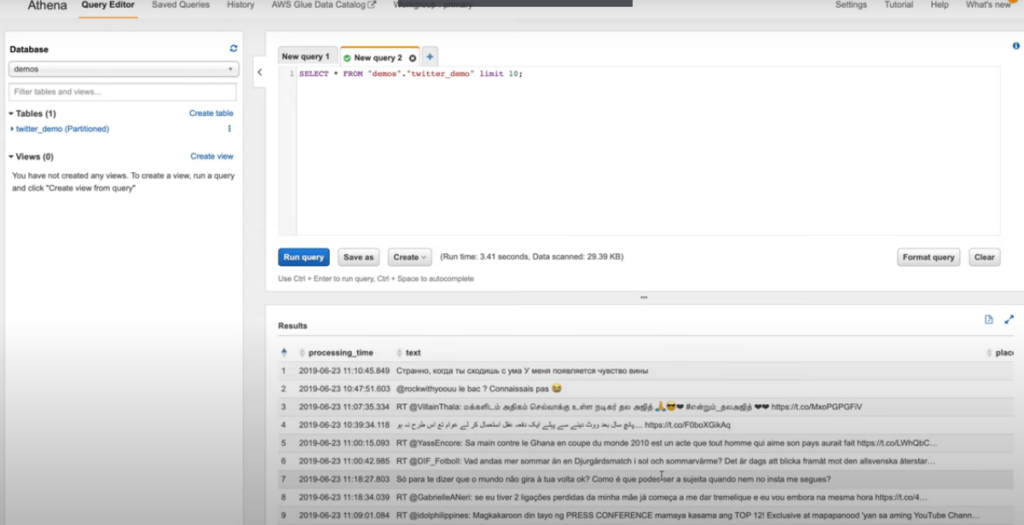
After the job finishes running, we can simply switch over to Athena, and select the data from the table we have asked Upsolver to create:
While this example was simple and we took the shortcut of using Upsolver, you can understand the basics of what you need to do to go from data in Athena to tables in S3:
- Retrieve the original schema and fields you would like to include in your Athena table while ensuring that these are consistently present in your data source
- Manage the table schema in the Glue Data Catalog and the S3 partitions where the data resides
- Optimize the data for performance if working with large datasets or streaming data sources
- Query the table in Athena using regular SQL
You can watch a video version of this tutorial here.
Want to learn more about Amazon Athena?
- Check out our complete guide to Athena performance
- Watch our webinar on ETL for Amazon Athena
- Visit our Athena solution space