
Explore our expert-made templates & start with the right one for you.
Easing Life for Every Data Engineer
-
 Ori Rafael
Ori Rafael
- Upsolver News
- December 13, 2021
Over the last decade, cloud data lakes have become cool. Funneling every data source into them has become the norm, and working with data has created some of the most esteemed professions of the 21st century. From data engineers to data scientists and data analysts, the skills required to work with data have risen to the top as some of the most respected in the economy.
But no matter how cool it is to have the sexiest job of the 21st century, 80% of a data professional’s time is still spent wrangling data, engineering transformations, getting data analytics-ready and struggling with creating data pipelines. Building data pipelines for cloud data lakes is fraught with complexity as organizations aspire to land every data type in them. For data engineers, working on pipelines has become painful and tedious as data consumers demand analytics-ready data delivered faster than ever. One astounding fact from an October 2021 study* found that 97% of data engineers reported experiencing burn out in their day-to-day jobs. Moreover, 79% have even considered switching careers.
What’s Behind the Burn Out?
Today, data engineers are saddled with mounting hours of work building data pipelines that turn complex raw data into analytics-ready data for data scientists and analysts. That includes integrating batch and streaming data, extrapolating schema from files, manually coding transformations, and orchestrating the myriad jobs required to optimally execute a data pipeline at scale.
Once these complex pipelines are built and deployed, the ongoing maintenance begins. These same data engineers have to endure the vicious cycle of scaling execution, handling myriad change requests from data consumers (including retroactive changes), managing pipeline performance, implementing non-stop data lake hygiene tasks like retention, partition management, compaction and, of course, controlling pipeline costs. In spite of all this effort, companies report that more than 30% of the data in their data lakes remains unusable, and most data consumers wait far too long for data to be ready for analytics.
Engineering Modern Data Pipelines
The rise of modern big data systems has dramatically increased the complexity of this challenge. In the old days of relational databases, data consumers had access to raw data and DBAs could tackle tough cases with SQL. However, in the world of the data lakes, engineering data pipelines demands technical sophistication — writing code, configuring orchestration tools, managing file-based object storage and finding ways to transform unstructured and semi-structured data, including streaming data. This leaves data engineers in the middle, constantly mediating between the demands of data consumers and raw data sources.
As much as scalable cloud data lakes have opened massive analytics opportunities, building and managing data pipelines has become the bane of every data engineer’s existence. The complexity and effort involved is unsustainable; there simply aren’t enough data engineers to keep up with the demand. However, this means there is also an immediate and large opportunity to make the data engineer’s life a whole lot easier, freeing them from ugly data pipeline plumbing so they can redirect their unique skills to higher value areas.
We at Upsolver were once data engineers and DBAs. We deeply understand this pain. And we are driven to make the most challenging but critical job of the 21st century enjoyable, fulfilling and pain-free. So how are we doing this?
An Easier, Faster Path to Creating Production-Grade Data Pipelines
Upsolver’s mission centers on three pillars; eliminate code-intensive development of data pipelines; automate all orchestration and maintenance of pipelines for cloud data; and speed the delivery of analytics-ready tables to data consumers. We achieve this by delivering an integrated continuous data pipeline platform, wrapped in a delightful user experience, and based on the world’s most widely used language for data – SQL.
That may sound like a lofty goal, but we started on this journey 5 years ago and today data teams across organizations big and small, have been more than impressed by what we’ve helped them achieve. For example, ironSource uses us to process 500,000 events per second and credits Upsolver for saving them “thousands of hours of engineering”, and ProofPoint reported building “a data lake driving real value to customers in weeks”, thanks to Upsolver’s low-code, SQL driven data pipeline solution. These are just two of many real-world examples.
Data Pipelines Made Simple, Scalable and Automated
We have reinvented data pipelines to be powerful and scalable for every data type, streaming and complex data included. We have made it simple to build pipelines and affordable to run them. In a single integrated system, data teams can now look forward to creating pipelines at scale in days to a couple weeks, at scale.
How Upsolver Simplifies Pipelines for Every Data Engineer
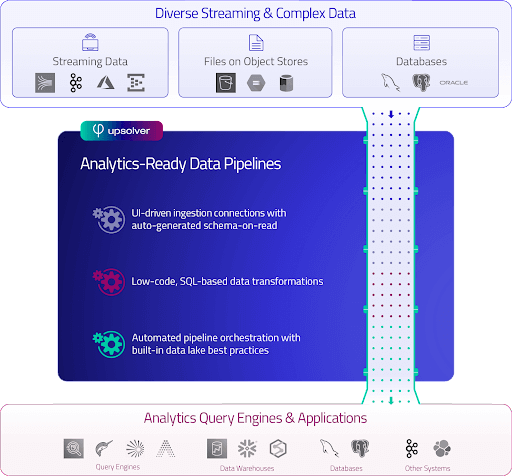
As innovators and practitioners, we are extremely gratified to hear how much easier we’ve made the lives of data engineers. It’s what makes everyone at Upsolver push harder to innovate faster.
Removing the Roadblock to Maximizing Value from Cloud Data Lakes
Data sources are plentiful. Cloud data lakes are proven. Delivering faster analytics-ready data is urgent. It’s now time to remove the biggest roadblock to unlocking analytics value by making data pipelines easy to build, manage and scale – no matter how complex the data. Easing the creation and maintenance of production-grade data pipelines for cloud data lakes, even on complex and streaming data, allows organizations to dramatically speed delivering analytics-ready data. That in turn speeds answers to urgent questions and reveals new truths to business stakeholders, to speed decision-making in the digital world. Moreover, we ease life for every data engineer, freeing them from painful pipeline development so they can apply their highly sought after skills to the highest value work.
Subscribe to our blog below to stay up-to-date on data pipeline innovation.
* Wakefield Research, October 2021
Published in:
Blog
,
Upsolver News